 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video-to-Audio Generation via Multiple Foundation Models Mapper
Sep 05, 2025
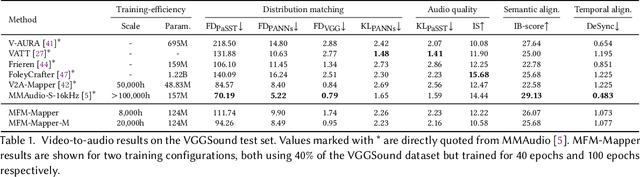


Recent Video-to-Audio (V2A) generation relies on extracting semantic and temporal features from video to condition generative models. Training these models from scratch is resource intensive. Consequently, leveraging foundation models (FMs) has gained traction due to their cross-modal knowledge transfer and generalization capabilities. One prior work has explored fine-tuning a lightweight mapper network to connect a pre-trained visual encoder with a text-to-audio generation model for V2A. Inspired by this, we introduce the Multiple Foundation Model Mapper (MFM-Mapper). Compared to the previous mapper approach, MFM-Mapper benefits from richer semantic and temporal information by fusing features from dual visual encoders. Furthermore, by replacing a linear mapper with GPT-2, MFM-Mapper improves feature alignment, drawing parallels between cross-modal features mapping and autoregressive translation tasks. Our MFM-Mapper exhibits remarkable training efficiency. It achieves better performance in semantic and temporal consistency with fewer training consuming, requiring only 16\% of the training scale compared to previous mapper-based work, yet achieves competitive performance with models trained on a much larger scale.
DenoiseReID: Denoising Model for Representation Learning of Person Re-Identification
Jun 13, 2024In this paper, we propose a novel Denoising Model for Representation Learning and take Person Re-Identification (ReID) as a benchmark task, named DenoiseReID, to improve feature discriminative with joint feature extraction and denoising. In the deep learning epoch, backbones which consists of cascaded embedding layers (e.g. convolutions or transformers) to progressively extract useful features, becomes popular. We first view each embedding layer in a backbone as a denoising layer, processing the cascaded embedding layers as if we are recursively denoise features step-by-step. This unifies the frameworks of feature extraction and feature denoising, where the former progressively embeds features from low-level to high-level, and the latter recursively denoises features step-by-step. Then we design a novel Feature Extraction and Feature Denoising Fusion Algorithm (FEFDFA) and \textit{theoretically demonstrate} its equivalence before and after fusion. FEFDFA merges parameters of the denoising layers into existing embedding layers, thus making feature denoising computation-free. This is a label-free algorithm to incrementally improve feature also complementary to the label if available. Besides, it enjoys two advantages: 1) it's a computation-free and label-free plugin for incrementally improving ReID features. 2) it is complementary to the label if the label is available. Experimental results on various tasks (large-scale image classification, fine-grained image classification, image retrieval) and backbones (transformers and convolutions) show the scalability and stability of our method. Experimental results on 4 ReID datasets and various of backbones show the stability and impressive improvements. We also extend the proposed method to large-scale (ImageNet) and fine-grained (e.g. CUB200) classification tasks, similar improvements are proven.
A LLM-based Controllable, Scalable, Human-Involved User Simulator Framework for Conversational Recommender Systems
May 13, 2024



Conversational Recommender System (CRS) leverages real-time feedback from users to dynamically model their preferences, thereby enhancing the system's ability to provide personalized recommendations and improving the overall user experience. CRS has demonstrated significant promise, prompting researchers to concentrate their efforts on developing user simulators that are both more realistic and trustworthy. The emergence of Large Language Models (LLMs) has marked the onset of a new epoch in computational capabilities, exhibiting human-level intelligence in various tasks. Research efforts have been made to utilize LLMs for building user simulators to evaluate the performance of CRS. Although these efforts showcase innovation, they are accompanied by certain limitations. In this work, we introduce a Controllable, Scalable, and Human-Involved (CSHI) simulator framework that manages the behavior of user simulators across various stages via a plugin manager. CSHI customizes the simulation of user behavior and interactions to provide a more lifelike and convincing user interaction experience. Through experiments and case studies in two conversational recommendation scenarios, we show that our framework can adapt to a variety of conversational recommendation settings and effectively simulate users' personalized preferences. Consequently, our simulator is able to generate feedback that closely mirrors that of real users. This facilitates a reliable assessment of existing CRS studies and promotes the creation of high-quality conversational recommendation datasets.
Towards Robust Recommendation: A Review and an Adversarial Robustness Evaluation Library
Apr 27, 2024


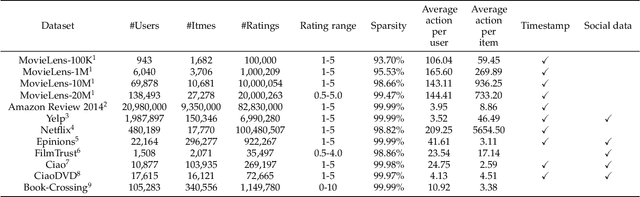
Recently, recommender system has achieved significant success. However, due to the openness of recommender systems, they remain vulnerable to malicious attacks. Additionally, natural noise in training data and issues such as data sparsity can also degrade the performance of recommender systems. Therefore, enhancing the robustness of recommender systems has become an increasingly important research topic. In this survey, we provide a comprehensive overview of the robustness of recommender systems. Based on our investigation, we categorize the robustness of recommender systems into adversarial robustness and non-adversarial robustness. In the adversarial robustness, we introduce the fundamental principles and classical methods of recommender system adversarial attacks and defenses. In the non-adversarial robustness, we analyze non-adversarial robustness from the perspectives of data sparsity, natural noise, and data imbalance. Additionally, we summarize commonly used datasets and evaluation metrics for evaluating the robustness of recommender systems. Finally, we also discuss the current challenges in the field of recommender system robustness and potential future research directions. Additionally, to facilitate fair and efficient evaluation of attack and defense methods in adversarial robustness, we propose an adversarial robustness evaluation library--ShillingREC, and we conduct evaluations of basic attack models and recommendation models. ShillingREC project is released at https://github.com/chengleileilei/ShillingREC.
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Apr 26, 2024


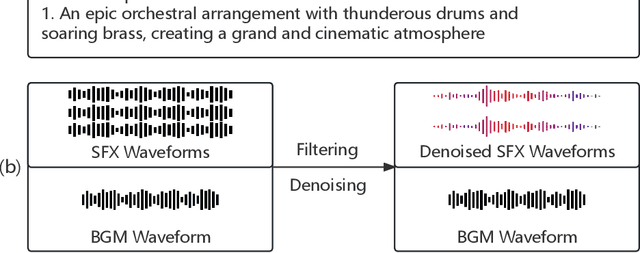
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
Exploring the Privacy Protection Capabilities of Chinese Large Language Models
Mar 27, 2024



Large language models (LLMs), renowned for their impressive capabilities in various tasks, have significantly advanced artificial intelligence. Yet, these advancements have raised growing concerns about privacy and security implications. To address these issues and explain the risks inherent in these models, we have devised a three-tiered progressive framework tailored for evaluating privacy in language systems. This framework consists of progressively complex and in-depth privacy test tasks at each tier. Our primary objective is to comprehensively evaluate the sensitivity of large language models to private information, examining how effectively they discern, manage, and safeguard sensitive data in diverse scenarios. This systematic evaluation helps us understand the degree to which these models comply with privacy protection guidelines and the effectiveness of their inherent safeguards against privacy breaches. Our observations indicate that existing Chinese large language models universally show privacy protection shortcomings. It seems that at the moment this widespread issue is unavoidable and may pose corresponding privacy risks in applications based on these models.
How Reliable is Your Simulator? Analysis on the Limitations of Current LLM-based User Simulators for Conversational Recommendation
Mar 25, 2024


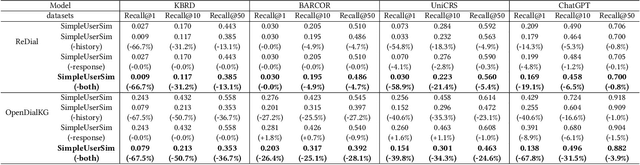
Conversational Recommender System (CRS) interacts with users through natural language to understand their preferences and provide personalized recommendations in real-time. CRS has demonstrated significant potential, prompting researchers to address the development of more realistic and reliable user simulators as a key focus. Recently, the capabilities of Large Language Models (LLMs) have attracted a lot of attention in various fields. Simultaneously, efforts are underway to construct user simulators based on LLMs. While these works showcase innovation, they also come with certain limitations that require attention. In this work, we aim to analyze the limitations of using LLMs in constructing user simulators for CRS, to guide future research. To achieve this goal, we conduct analytical validation on the notable work, iEvaLM. Through multiple experiments on two widely-used datasets in the field of conversational recommendation, we highlight several issues with the current evaluation methods for user simulators based on LLMs: (1) Data leakage, which occurs in conversational history and the user simulator's replies, results in inflated evaluation results. (2) The success of CRS recommendations depends more on the availability and quality of conversational history than on the responses from user simulators. (3) Controlling the output of the user simulator through a single prompt template proves challenging. To overcome these limitations, we propose SimpleUserSim, employing a straightforward strategy to guide the topic toward the target items. Our study validates the ability of CRS models to utilize the interaction information, significantly improving the recommendation results.
Non-generative Generalized Zero-shot Learning via Task-correlated Disentanglement and Controllable Samples Synthesis
Mar 13, 2022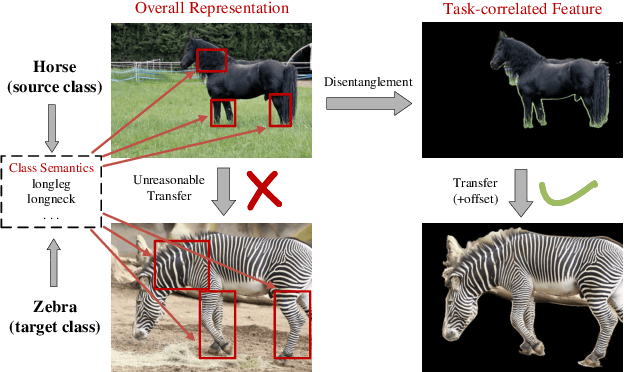
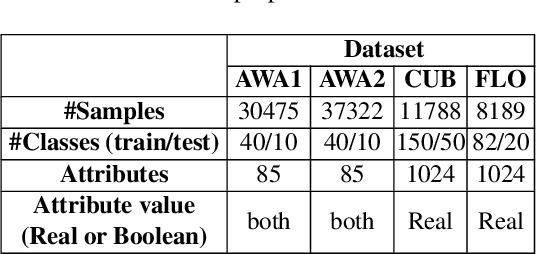
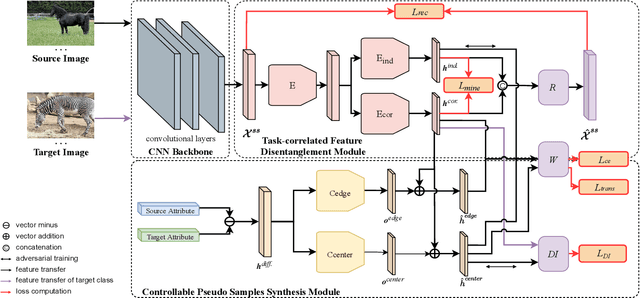
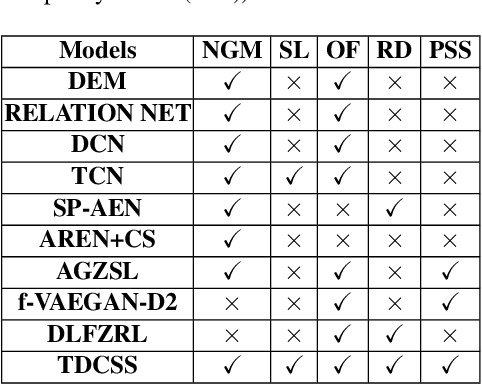
Synthesizing pseudo samples is currently the most effective way to solve the Generalized Zero Shot Learning (GZSL) problem. Most models achieve competitive performance but still suffer from two problems: (1) Feature confounding, the overall representations confound task-correlated and task-independent features, and existing models disentangle them in a generative way, but they are unreasonable to synthesize reliable pseudo samples with limited samples; (2) Distribution uncertainty, that massive data is needed when existing models synthesize samples from the uncertain distribution, which causes poor performance in limited samples of seen classes. In this paper, we propose a non-generative model to address these problems correspondingly in two modules: (1) Task-correlated feature disentanglement, to exclude the task-correlated features from task-independent ones by adversarial learning of domain adaption towards reasonable synthesis; (2) Controllable pseudo sample synthesis, to synthesize edge-pseudo and center-pseudo samples with certain characteristics towards more diversity generated and intuitive transfer. In addation, to describe the new scene that is the limit seen class samples in the training process, we further formulate a new ZSL task named the 'Few-shot Seen class and Zero-shot Unseen class learning' (FSZU). Extensive experiments on four benchmarks verify that the proposed method is competitive in the GZSL and the FSZU tasks.
Learning to Learn a Cold-start Sequential Recommender
Oct 18, 2021
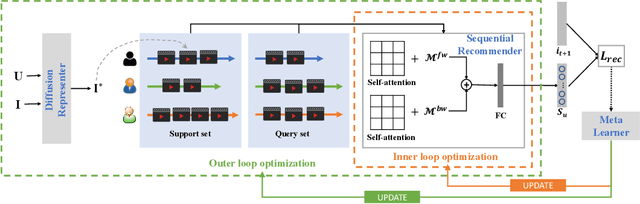
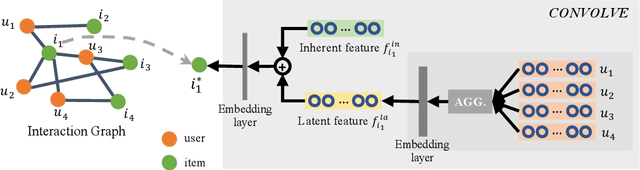
The cold-start recommendation is an urgent problem in contemporary online applications. It aims to provide users whose behaviors are literally sparse with as accurate recommendations as possible. Many data-driven algorithms, such as the widely used matrix factorization, underperform because of data sparseness. This work adopts the idea of meta-learning to solve the user's cold-start recommendation problem. We propose a meta-learning based cold-start sequential recommendation framework called metaCSR, including three main components: Diffusion Representer for learning better user/item embedding through information diffusion on the interaction graph; Sequential Recommender for capturing temporal dependencies of behavior sequences; Meta Learner for extracting and propagating transferable knowledge of prior users and learning a good initialization for new users. metaCSR holds the ability to learn the common patterns from regular users' behaviors and optimize the initialization so that the model can quickly adapt to new users after one or a few gradient updates to achieve optimal performance. The extensive quantitative experiments on three widely-used datasets show the remarkable performance of metaCSR in dealing with user cold-start problem. Meanwhile, a series of qualitative analysis demonstrates that the proposed metaCSR has good generalization.
Knowledge Graph-enhanced Sampling for Conversational Recommender System
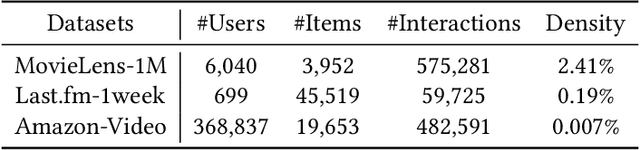
Oct 13, 2021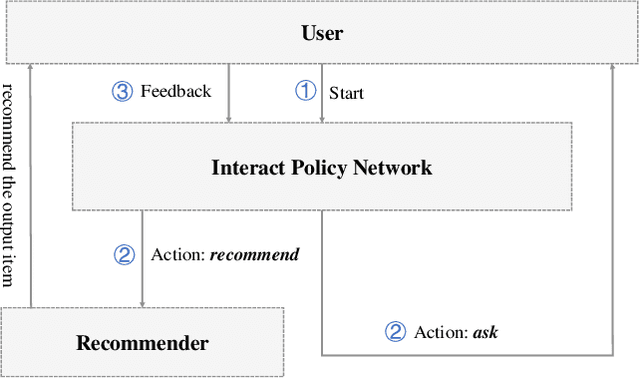
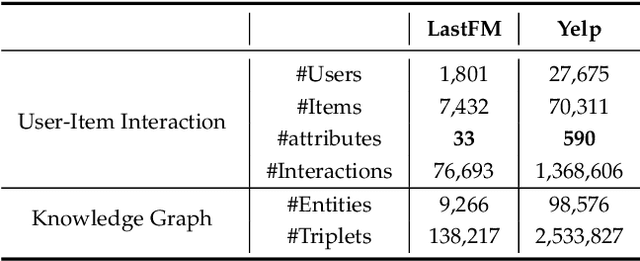
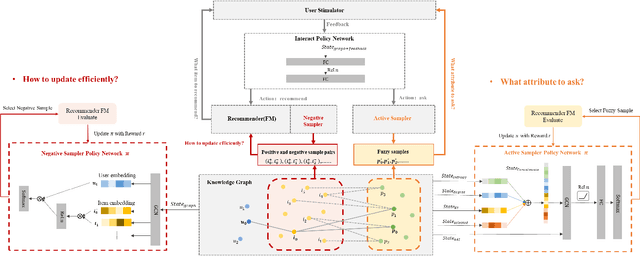
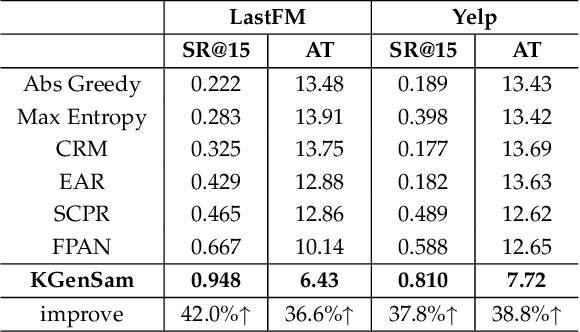
The traditional recommendation systems mainly use offline user data to train offline models, and then recommend items for online users, thus suffering from the unreliable estimation of user preferences based on sparse and noisy historical data. Conversational Recommendation System (CRS) uses the interactive form of the dialogue systems to solve the intrinsic problems of traditional recommendation systems. However, due to the lack of contextual information modeling, the existing CRS models are unable to deal with the exploitation and exploration (E&E) problem well, resulting in the heavy burden on users. To address the aforementioned issue, this work proposes a contextual information enhancement model tailored for CRS, called Knowledge Graph-enhanced Sampling (KGenSam). KGenSam integrates the dynamic graph of user interaction data with the external knowledge into one heterogeneous Knowledge Graph (KG) as the contextual information environment. Then, two samplers are designed to enhance knowledge by sampling fuzzy samples with high uncertainty for obtaining user preferences and reliable negative samples for updating recommender to achieve efficient acquisition of user preferences and model updating, and thus provide a powerful solution for CRS to deal with E&E problem. Experimental results on two real-world datasets demonstrate the superiority of KGenSam with significant improvements over state-of-the-art methods.