 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video-to-Audio Generation via Multiple Foundation Models Mapper
Sep 05, 2025Recent Video-to-Audio (V2A) generation relies on extracting semantic and temporal features from video to condition generative models. Training these models from scratch is resource intensive. Consequently, leveraging foundation models (FMs) has gained traction due to their cross-modal knowledge transfer and generalization capabilities. One prior work has explored fine-tuning a lightweight mapper network to connect a pre-trained visual encoder with a text-to-audio generation model for V2A. Inspired by this, we introduce the Multiple Foundation Model Mapper (MFM-Mapper). Compared to the previous mapper approach, MFM-Mapper benefits from richer semantic and temporal information by fusing features from dual visual encoders. Furthermore, by replacing a linear mapper with GPT-2, MFM-Mapper improves feature alignment, drawing parallels between cross-modal features mapping and autoregressive translation tasks. Our MFM-Mapper exhibits remarkable training efficiency. It achieves better performance in semantic and temporal consistency with fewer training consuming, requiring only 16\% of the training scale compared to previous mapper-based work, yet achieves competitive performance with models trained on a much larger scale.
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Apr 26, 2024


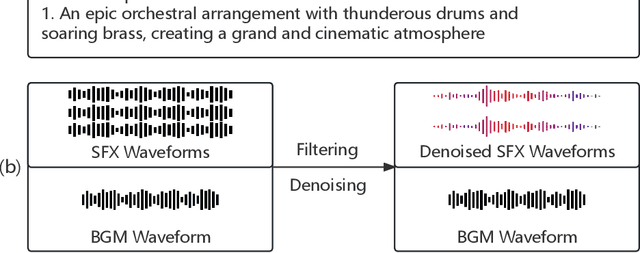
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.