 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Perplexing Behaviors in Modified BP Attributions through Alignment Perspective
Mar 14, 2025


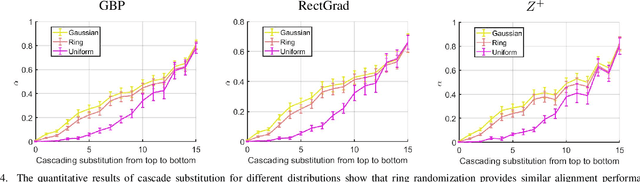
Attributions aim to identify input pixels that are relevant to the decision-making process. A popular approach involves using modified backpropagation (BP) rules to reverse decisions, which improves interpretability compared to the original gradients. However, these methods lack a solid theoretical foundation and exhibit perplexing behaviors, such as reduced sensitivity to parameter randomization, raising concerns about their reliability and highlighting the need for theoretical justification. In this work, we present a unified theoretical framework for methods like GBP, RectGrad, LRP, and DTD, demonstrating that they achieve input alignment by combining the weights of activated neurons. This alignment improves the visualization quality and reduces sensitivity to weight randomization. Our contributions include: (1) Providing a unified explanation for multiple behaviors, rather than focusing on just one. (2) Accurately predicting novel behaviors. (3) Offering insights into decision-making processes, including layer-wise information changes and the relationship between attributions and model decisions.
MMCGAN: Generative Adversarial Network with Explicit Manifold Prior
Jun 18, 2020
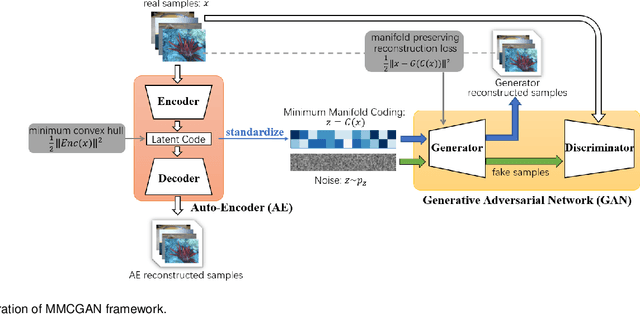
Generative Adversarial Network(GAN) provides a good generative framework to produce realistic samples, but suffers from two recognized issues as mode collapse and unstable training. In this work, we propose to employ explicit manifold learning as prior to alleviate mode collapse and stabilize training of GAN. Since the basic assumption of conventional manifold learning fails in case of sparse and uneven data distribution, we introduce a new target, Minimum Manifold Coding (MMC), for manifold learning to encourage simple and unfolded manifold. In essence, MMC is the general case of the shortest Hamiltonian Path problem and pursues manifold with minimum Riemann volume. Using the standardized code from MMC as prior, GAN is guaranteed to recover a simple and unfolded manifold covering all the training data. Our experiments on both the toy data and real datasets show the effectiveness of MMCGAN in alleviating mode collapse, stabilizing training, and improving the quality of generated samples.
Adaptive Adversarial Logits Pairing
May 25, 2020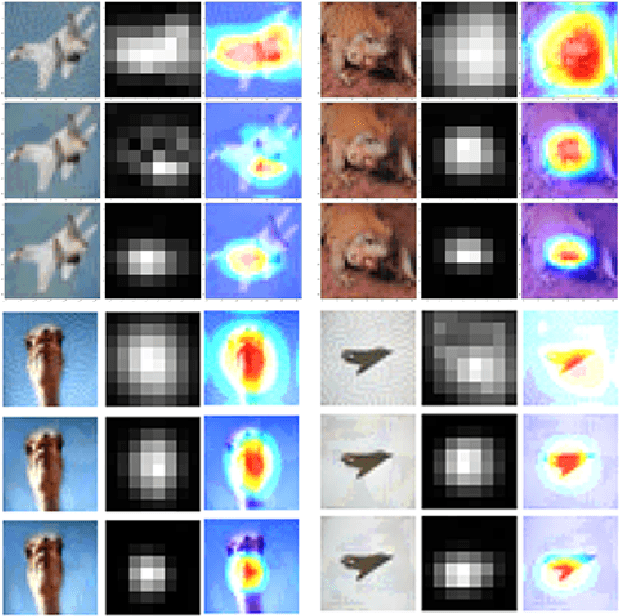
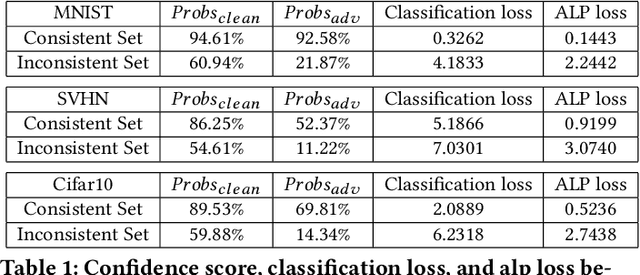
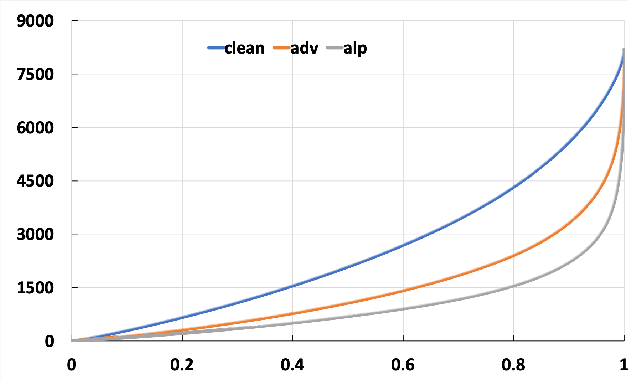
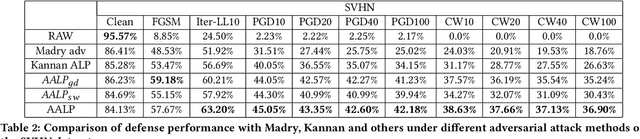
Adversarial examples provide an opportunity as well as impose a challenge for understanding image classification systems. Based on the analysis of state-of-the-art defense solution Adversarial Logits Pairing (ALP), we observed in this work that: (1) The inference of adversarially robust models tends to rely on fewer high-contribution features compared with vulnerable ones. (2) The training target of ALP doesn't fit well to a noticeable part of samples, where the logits pairing loss is overemphasized and obstructs minimizing the classification loss. Motivated by these observations, we designed an Adaptive Adversarial Logits Pairing (AALP) solution by modifying the training process and training target of ALP. Specifically, AALP consists of an adaptive feature optimization module with Guided Dropout to systematically pursue few high-contribution features, and an adaptive sample weighting module by setting sample-specific training weights to balance between logits pairing loss and classification loss. The proposed AALP solution demonstrates superior defense performance on multiple datasets with extensive experiments.
A Generalization Theory based on Independent and Task-Identically Distributed Assumption
Nov 28, 2019

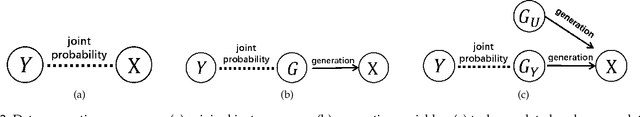
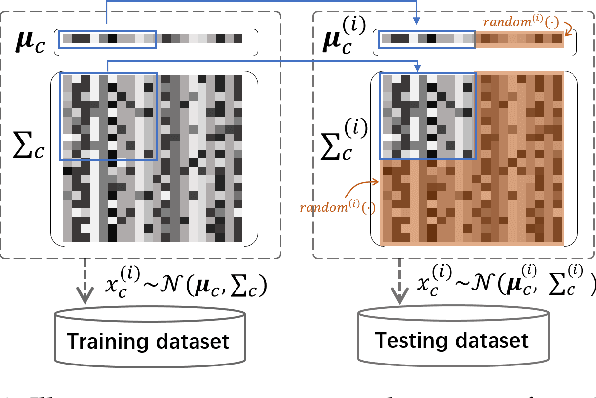
Existing generalization theories analyze the generalization performance mainly based on the model complexity and training process. The ignorance of the task properties, which results from the widely used IID assumption, makes these theories fail to interpret many generalization phenomena or guide practical learning tasks. In this paper, we propose a new Independent and Task-Identically Distributed (ITID) assumption, to consider the task properties into the data generating process. The derived generalization bound based on the ITID assumption identifies the significance of hypothesis invariance in guaranteeing generalization performance. Based on the new bound, we introduce a practical invariance enhancement algorithm from the perspective of modifying data distributions. Finally, we verify the algorithm and theorems in the context of image classification task on both toy and real-world datasets. The experimental results demonstrate the reasonableness of the ITID assumption and the effectiveness of new generalization theory in improving practical generalization performance.
Understanding Deep Learning Generalization by Maximum Entropy
Nov 21, 2017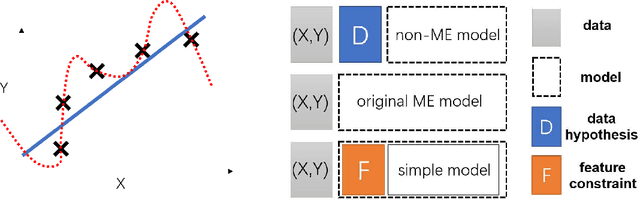
Deep learning achieves remarkable generalization capability with overwhelming number of model parameters. Theoretical understanding of deep learning generalization receives recent attention yet remains not fully explored. This paper attempts to provide an alternative understanding from the perspective of maximum entropy. We first derive two feature conditions that softmax regression strictly apply maximum entropy principle. DNN is then regarded as approximating the feature conditions with multilayer feature learning, and proved to be a recursive solution towards maximum entropy principle. The connection between DNN and maximum entropy well explains why typical designs such as shortcut and regularization improves model generalization, and provides instructions for future model development.