 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Perplexing Behaviors in Modified BP Attributions through Alignment Perspective
Paper and Code
Mar 14, 2025


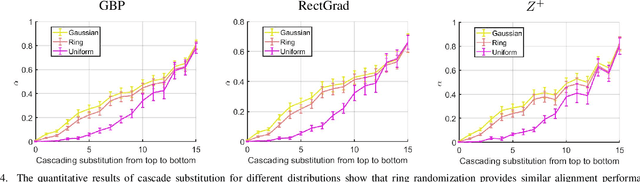
Attributions aim to identify input pixels that are relevant to the decision-making process. A popular approach involves using modified backpropagation (BP) rules to reverse decisions, which improves interpretability compared to the original gradients. However, these methods lack a solid theoretical foundation and exhibit perplexing behaviors, such as reduced sensitivity to parameter randomization, raising concerns about their reliability and highlighting the need for theoretical justification. In this work, we present a unified theoretical framework for methods like GBP, RectGrad, LRP, and DTD, demonstrating that they achieve input alignment by combining the weights of activated neurons. This alignment improves the visualization quality and reduces sensitivity to weight randomization. Our contributions include: (1) Providing a unified explanation for multiple behaviors, rather than focusing on just one. (2) Accurately predicting novel behaviors. (3) Offering insights into decision-making processes, including layer-wise information changes and the relationship between attributions and model decisions.