Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuanced Metrics for Measuring Unintended Bias with Real Data for Text Classification
Paper and Code
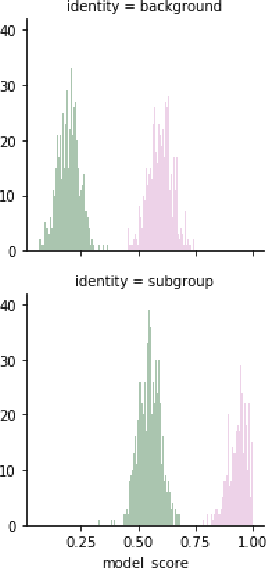
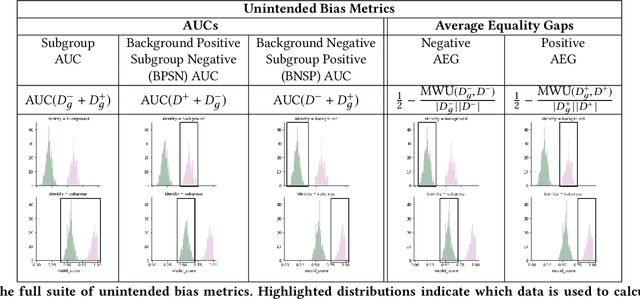
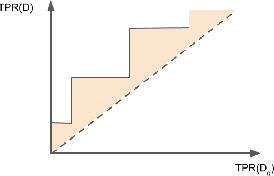
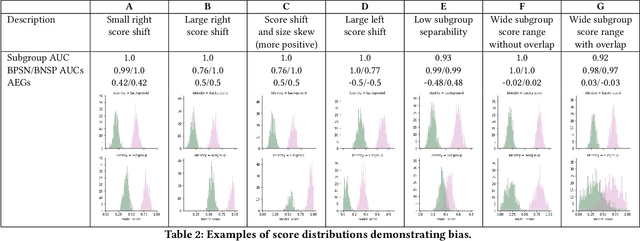
Unintended bias in Machine Learning can manifest as systemic differences in performance for different demographic groups, potentially compounding existing challenges to fairness in society at large. In this paper, we introduce a suite of threshold-agnostic metrics that provide a nuanced view of this unintended bias, by considering the various ways that a classifier's score distribution can vary across designated groups. We also introduce a large new test set of online comments with crowd-sourced annotations for identity references. We use this to show how our metrics can be used to find new and potentially subtle unintended bias in existing public models.
View paper on