 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNodeSynth: Socially Aligned Synthetic Data for AI Evaluation
May 14, 2026Recent advancements in generative AI facilitate large-scale synthetic data generation for model evaluation. However, without targeted approaches, these datasets often lack the sociotechnical nuance required for sensitive domains. We introduce NodeSynth, an evidence-grounded methodology that generates socially relevant synthetic queries by leveraging a fine-tuned taxonomy generator (TaG) anchored in real-world evidence. Evaluated against four mainstream LLMs (e.g., Claude 4.5 Haiku), NodeSynth elicited failure rates up to five times higher than human-authored benchmarks. Ablation studies confirm that our granular taxonomic expansion significantly drives these failure rates, while independent validation reveals critical deficiencies in prominent guard models (e.g., Llama-Guard-3). We open-source our end-to-end research prototype and datasets to enable scalable, high-stakes model evaluation and targeted safety interventions (https://github.com/google-research/nodesynth).
A Unified Framework to Quantify Cultural Intelligence of AI
Mar 01, 2026As generative AI technologies are increasingly being launched across the globe, assessing their competence to operate in different cultural contexts is exigently becoming a priority. While recent years have seen numerous and much-needed efforts on cultural benchmarking, these efforts have largely focused on specific aspects of culture and evaluation. While these efforts contribute to our understanding of cultural competence, a unified and systematic evaluation approach is needed for us as a field to comprehensively assess diverse cultural dimensions at scale. Drawing on measurement theory, we present a principled framework to aggregate multifaceted indicators of cultural capabilities into a unified assessment of cultural intelligence. We start by developing a working definition of culture that includes identifying core domains of culture. We then introduce a broad-purpose, systematic, and extensible framework for assessing cultural intelligence of AI systems. Drawing on theoretical framing from psychometric measurement validity theory, we decouple the background concept (i.e., cultural intelligence) from its operationalization via measurement. We conceptualize cultural intelligence as a suite of core capabilities spanning diverse domains, which we then operationalize through a set of indicators designed for reliable measurement. Finally, we identify the considerations, challenges, and research pathways to meaningfully measure these indicators, specifically focusing on data collection, probing strategies, and evaluation metrics.
Amplify Initiative: Building A Localized Data Platform for Globalized AI
Apr 18, 2025Current AI models often fail to account for local context and language, given the predominance of English and Western internet content in their training data. This hinders the global relevance, usefulness, and safety of these models as they gain more users around the globe. Amplify Initiative, a data platform and methodology, leverages expert communities to collect diverse, high-quality data to address the limitations of these models. The platform is designed to enable co-creation of datasets, provide access to high-quality multilingual datasets, and offer recognition to data authors. This paper presents the approach to co-creating datasets with domain experts (e.g., health workers, teachers) through a pilot conducted in Sub-Saharan Africa (Ghana, Kenya, Malawi, Nigeria, and Uganda). In partnership with local researchers situated in these countries, the pilot demonstrated an end-to-end approach to co-creating data with 155 experts in sensitive domains (e.g., physicians, bankers, anthropologists, human and civil rights advocates). This approach, implemented with an Android app, resulted in an annotated dataset of 8,091 adversarial queries in seven languages (e.g., Luganda, Swahili, Chichewa), capturing nuanced and contextual information related to key themes such as misinformation and public interest topics. This dataset in turn can be used to evaluate models for their safety and cultural relevance within the context of these languages.
Improving Neutral Point of View Text Generation through Parameter-Efficient Reinforcement Learning and a Small-Scale High-Quality Dataset
Mar 05, 2025This paper describes the construction of a dataset and the evaluation of training methods to improve generative large language models' (LLMs) ability to answer queries on sensitive topics with a Neutral Point of View (NPOV), i.e., to provide significantly more informative, diverse and impartial answers. The dataset, the SHQ-NPOV dataset, comprises 300 high-quality, human-written quadruplets: a query on a sensitive topic, an answer, an NPOV rating, and a set of links to source texts elaborating the various points of view. The first key contribution of this paper is a new methodology to create such datasets through iterative rounds of human peer-critique and annotator training, which we release alongside the dataset. The second key contribution is the identification of a highly effective training regime for parameter-efficient reinforcement learning (PE-RL) to improve NPOV generation. We compare and extensively evaluate PE-RL and multiple baselines-including LoRA finetuning (a strong baseline), SFT and RLHF. PE-RL not only improves on overall NPOV quality compared to the strongest baseline ($97.06\%\rightarrow 99.08\%$), but also scores much higher on features linguists identify as key to separating good answers from the best answers ($60.25\%\rightarrow 85.21\%$ for presence of supportive details, $68.74\%\rightarrow 91.43\%$ for absence of oversimplification). A qualitative analysis corroborates this. Finally, our evaluation finds no statistical differences between results on topics that appear in the training dataset and those on separated evaluation topics, which provides strong evidence that our approach to training PE-RL exhibits very effective out of topic generalization.
Socially Responsible Data for Large Multilingual Language Models
Sep 08, 2024
Large Language Models (LLMs) have rapidly increased in size and apparent capabilities in the last three years, but their training data is largely English text. There is growing interest in multilingual LLMs, and various efforts are striving for models to accommodate languages of communities outside of the Global North, which include many languages that have been historically underrepresented in digital realms. These languages have been coined as "low resource languages" or "long-tail languages", and LLMs performance on these languages is generally poor. While expanding the use of LLMs to more languages may bring many potential benefits, such as assisting cross-community communication and language preservation, great care must be taken to ensure that data collection on these languages is not extractive and that it does not reproduce exploitative practices of the past. Collecting data from languages spoken by previously colonized people, indigenous people, and non-Western languages raises many complex sociopolitical and ethical questions, e.g., around consent, cultural safety, and data sovereignty. Furthermore, linguistic complexity and cultural nuances are often lost in LLMs. This position paper builds on recent scholarship, and our own work, and outlines several relevant social, cultural, and ethical considerations and potential ways to mitigate them through qualitative research, community partnerships, and participatory design approaches. We provide twelve recommendations for consideration when collecting language data on underrepresented language communities outside of the Global North.
Ontology of Belief Diversity: A Community-Based Epistemological Approach
Jul 25, 2024AI applications across classification, fairness, and human interaction often implicitly require ontologies of social concepts. Constructing these well, especially when there are many relevant categories, is a controversial task but is crucial for achieving meaningful inclusivity. Here, we focus on developing a pragmatic ontology of belief systems, which is a complex and often controversial space. By iterating on our community-based design until mutual agreement is reached, we found that epistemological methods were best for categorizing the fundamental ways beliefs differ, maximally respecting our principles of inclusivity and brevity. We demonstrate our methodology's utility and interpretability via user studies in term annotation and sentiment analysis experiments for belief fairness in language models.
Detecting Hallucination and Coverage Errors in Retrieval Augmented Generation for Controversial Topics
Mar 13, 2024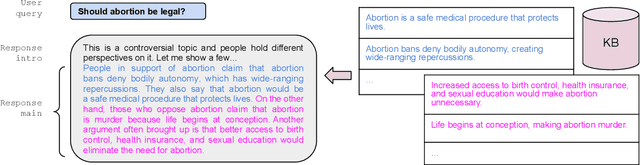



We explore a strategy to handle controversial topics in LLM-based chatbots based on Wikipedia's Neutral Point of View (NPOV) principle: acknowledge the absence of a single true answer and surface multiple perspectives. We frame this as retrieval augmented generation, where perspectives are retrieved from a knowledge base and the LLM is tasked with generating a fluent and faithful response from the given perspectives. As a starting point, we use a deterministic retrieval system and then focus on common LLM failure modes that arise during this approach to text generation, namely hallucination and coverage errors. We propose and evaluate three methods to detect such errors based on (1) word-overlap, (2) salience, and (3) LLM-based classifiers. Our results demonstrate that LLM-based classifiers, even when trained only on synthetic errors, achieve high error detection performance, with ROC AUC scores of 95.3% for hallucination and 90.5% for coverage error detection on unambiguous error cases. We show that when no training data is available, our other methods still yield good results on hallucination (84.0%) and coverage error (85.2%) detection.