 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalse Positive and Cross-relation Signals in Distant Supervision Data
Paper and Code
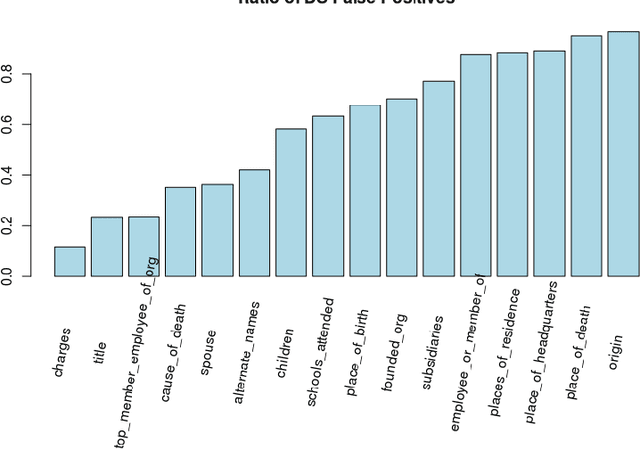
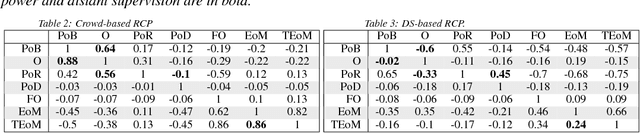
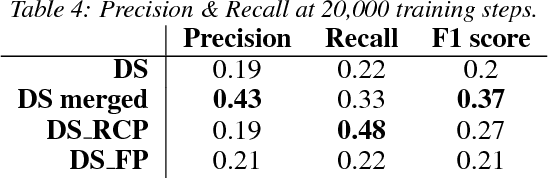
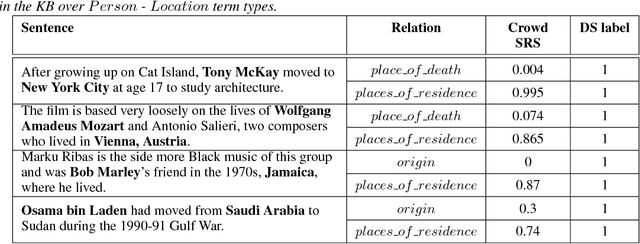
Distant supervision (DS) is a well-established method for relation extraction from text, based on the assumption that when a knowledge-base contains a relation between a term pair, then sentences that contain that pair are likely to express the relation. In this paper, we use the results of a crowdsourcing relation extraction task to identify two problems with DS data quality: the widely varying degree of false positives across different relations, and the observed causal connection between relations that are not considered by the DS method. The crowdsourcing data aggregation is performed using ambiguity-aware CrowdTruth metrics, that are used to capture and interpret inter-annotator disagreement. We also present preliminary results of using the crowd to enhance DS training data for a relation classification model, without requiring the crowd to annotate the entire set.