 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCareer Path Recommendations for Long-term Income Maximization: A Reinforcement Learning Approach
Sep 11, 2023This study explores the potential of reinforcement learning algorithms to enhance career planning processes. Leveraging data from Randstad The Netherlands, the study simulates the Dutch job market and develops strategies to optimize employees' long-term income. By formulating career planning as a Markov Decision Process (MDP) and utilizing machine learning algorithms such as Sarsa, Q-Learning, and A2C, we learn optimal policies that recommend career paths with high-income occupations and industries. The results demonstrate significant improvements in employees' income trajectories, with RL models, particularly Q-Learning and Sarsa, achieving an average increase of 5% compared to observed career paths. The study acknowledges limitations, including narrow job filtering, simplifications in the environment formulation, and assumptions regarding employment continuity and zero application costs. Future research can explore additional objectives beyond income optimization and address these limitations to further enhance career planning processes.
Learning to Match Job Candidates Using Multilingual Bi-Encoder BERT
Sep 15, 2021In this talk, we will show how we used Randstad history of candidate placements to generate labeled CV-vacancy pairs dataset. Afterwards we fine-tune a multilingual BERT with bi encoder structure over this dataset, by adding a cosine similarity log loss layer. We will explain how using the mentioned structure helps us overcome most of the challenges described above, and how it enables us to build a maintainable and scalable pipeline to match CVs and vacancies. In addition, we show how we gain a better semantic understanding, and learn to bridge the vocabulary gap. Finally, we highlight how multilingual transformers help us handle cross language barrier and might reduce discrimination.
conSultantBERT: Fine-tuned Siamese Sentence-BERT for Matching Jobs and Job Seekers
Sep 14, 2021
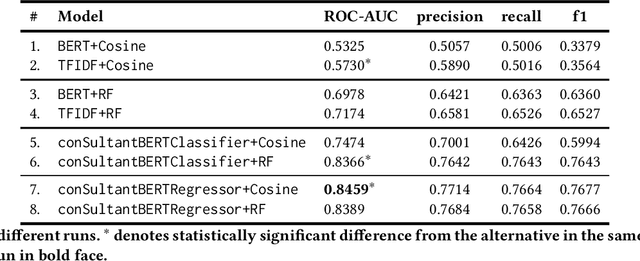
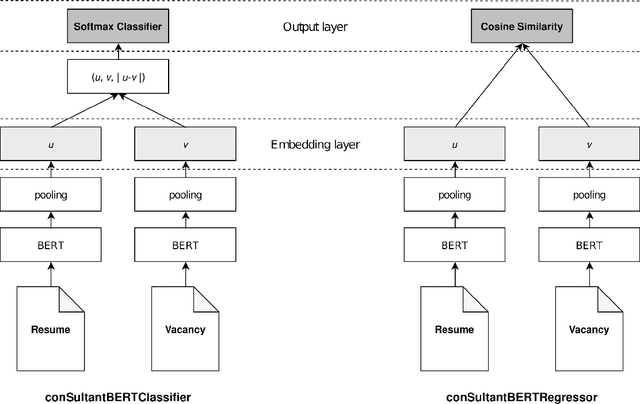
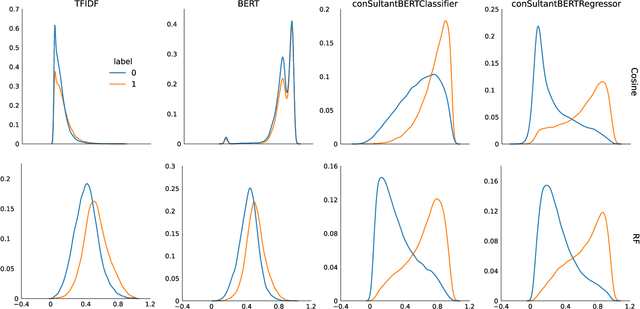
In this paper we focus on constructing useful embeddings of textual information in vacancies and resumes, which we aim to incorporate as features into job to job seeker matching models alongside other features. We explain our task where noisy data from parsed resumes, heterogeneous nature of the different sources of data, and crosslinguality and multilinguality present domain-specific challenges. We address these challenges by fine-tuning a Siamese Sentence-BERT (SBERT) model, which we call conSultantBERT, using a large-scale, real-world, and high quality dataset of over 270,000 resume-vacancy pairs labeled by our staffing consultants. We show how our fine-tuned model significantly outperforms unsupervised and supervised baselines that rely on TF-IDF-weighted feature vectors and BERT embeddings. In addition, we find our model successfully matches cross-lingual and multilingual textual content.