 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICAM-reg: Interpretable Classification and Regression with Feature Attribution for Mapping Neurological Phenotypes in Individual Scans
Mar 03, 2021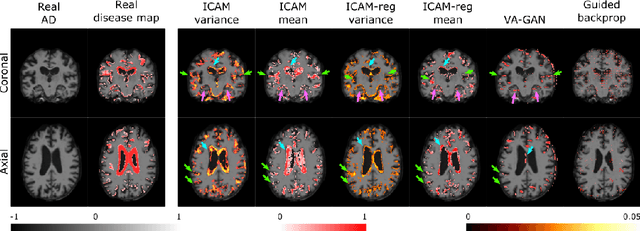
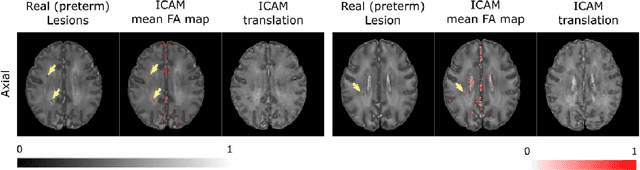

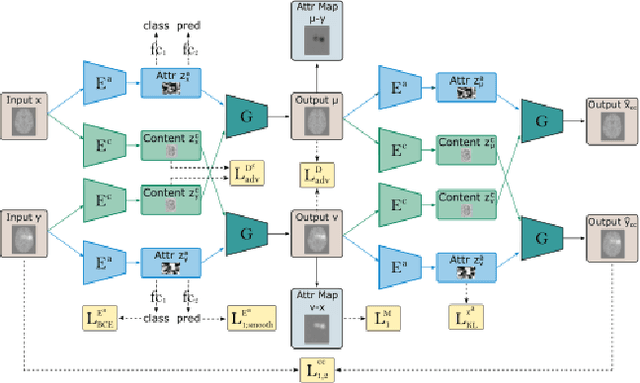
An important goal of medical imaging is to be able to precisely detect patterns of disease specific to individual scans; however, this is challenged in brain imaging by the degree of heterogeneity of shape and appearance. Traditional methods, based on image registration to a global template, historically fail to detect variable features of disease, as they utilise population-based analyses, suited primarily to studying group-average effects. In this paper we therefore take advantage of recent developments in generative deep learning to develop a method for simultaneous classification, or regression, and feature attribution (FA). Specifically, we explore the use of a VAE-GAN translation network called ICAM, to explicitly disentangle class relevant features from background confounds for improved interpretability and regression of neurological phenotypes. We validate our method on the tasks of Mini-Mental State Examination (MMSE) cognitive test score prediction for the Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort, as well as brain age prediction, for both neurodevelopment and neurodegeneration, using the developing Human Connectome Project (dHCP) and UK Biobank datasets. We show that the generated FA maps can be used to explain outlier predictions and demonstrate that the inclusion of a regression module improves the disentanglement of the latent space. Our code is freely available on Github https://github.com/CherBass/ICAM.
ICAM: Interpretable Classification via Disentangled Representations and Feature Attribution Mapping
Jun 16, 2020

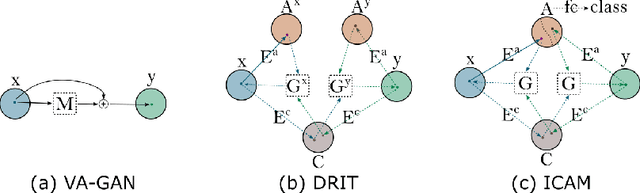
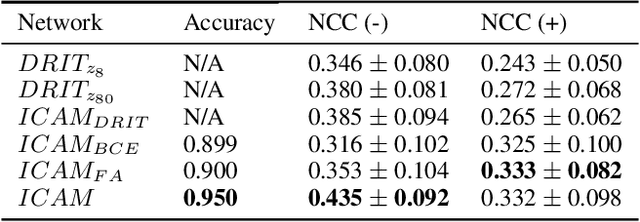
Feature attribution (FA), or the assignment of class-relevance to different locations in an image, is important for many classification problems but is particularly crucial within the neuroscience domain, where accurate mechanistic models of behaviours, or disease, require knowledge of all features discriminative of a trait. At the same time, predicting class relevance from brain images is challenging as phenotypes are typically heterogeneous, and changes occur against a background of significant natural variation. Here, we present a novel framework for creating class specific FA maps through image-to-image translation. We propose the use of a VAE-GAN to explicitly disentangle class relevance from background features for improved interpretability properties, which results in meaningful FA maps. We validate our method on 2D and 3D brain image datasets of dementia (ADNI dataset), ageing (UK Biobank), and (simulated) lesion detection. We show that FA maps generated by our method outperform baseline FA methods when validated against ground truth. More significantly, our approach is the first to use latent space sampling to support exploration of phenotype variation. Our code will be available online at https://github.com/CherBass/ICAM.
Permutation Inference for Canonical Correlation Analysis
Mar 14, 2020


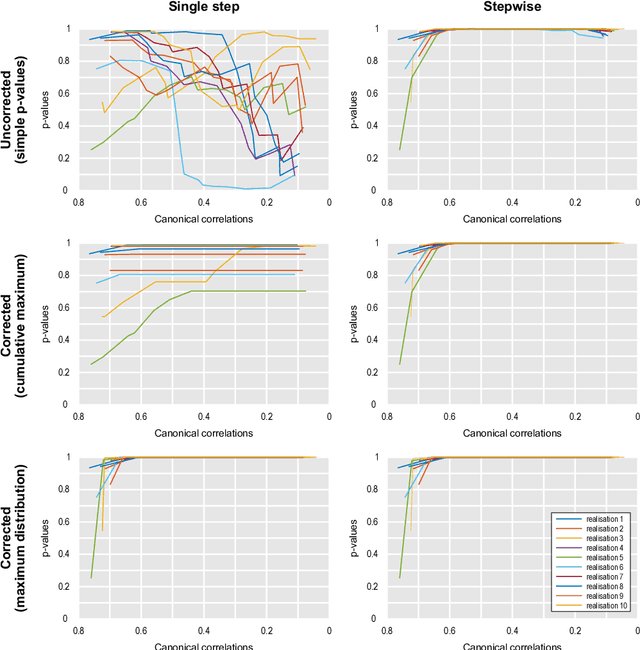
Canonical correlation analysis (CCA) has become a key tool for population neuroimaging, allowing investigation of associations between many imaging and non-imaging measurements. As age, sex and other variables are often a source of variability not of direct interest, previous work has used CCA on residuals from a model that removes these effects, then proceeded directly to permutation inference. We show that a simple permutation test, as typically used to identify significant modes of shared variation on such data adjusted for nuisance variables, produces inflated error rates. The reason is that residualisation introduces dependencies among the observations that violate the exchangeability assumption. Even in the absence of nuisance variables, however, a simple permutation test for CCA also leads to excess error rates for all canonical correlations other than the first. The reason is that a simple permutation scheme does not ignore the variability already explained by previous canonical variables. Here we propose solutions for both problems: in the case of nuisance variables, we show that transforming the residuals to a lower dimensional basis where exchangeability holds results in a valid permutation test; for more general cases, with or without nuisance variables, we propose estimating the canonical correlations in a stepwise manner, removing at each iteration the variance already explained, while dealing with different number of variables in both sides. We also discuss how to address the multiplicity of tests, proposing an admissible test that is not conservative, and provide a complete algorithm for permutation inference for CCA.