 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Propagation for Echocardiography Clinical Metric Estimation via Contour Sampling
Feb 18, 2025Echocardiography plays a fundamental role in the extraction of important clinical parameters (e.g. left ventricular volume and ejection fraction) required to determine the presence and severity of heart-related conditions. When deploying automated techniques for computing these parameters, uncertainty estimation is crucial for assessing their utility. Since clinical parameters are usually derived from segmentation maps, there is no clear path for converting pixel-wise uncertainty values into uncertainty estimates in the downstream clinical metric calculation. In this work, we propose a novel uncertainty estimation method based on contouring rather than segmentation. Our method explicitly predicts contour location uncertainty from which contour samples can be drawn. Finally, the sampled contours can be used to propagate uncertainty to clinical metrics. Our proposed method not only provides accurate uncertainty estimations for the task of contouring but also for the downstream clinical metrics on two cardiac ultrasound datasets. Code is available at: https://github.com/ThierryJudge/contouring-uncertainty.
Efficient Semantic Diffusion Architectures for Model Training on Synthetic Echocardiograms
Sep 28, 2024We investigate the utility of diffusion generative models to efficiently synthesise datasets that effectively train deep learning models for image analysis. Specifically, we propose novel $\Gamma$-distribution Latent Denoising Diffusion Models (LDMs) designed to generate semantically guided synthetic cardiac ultrasound images with improved computational efficiency. We also investigate the potential of using these synthetic images as a replacement for real data in training deep networks for left-ventricular segmentation and binary echocardiogram view classification tasks. We compared six diffusion models in terms of the computational cost of generating synthetic 2D echo data, the visual realism of the resulting images, and the performance, on real data, of downstream tasks (segmentation and classification) trained using these synthetic echoes. We compare various diffusion strategies and ODE solvers for their impact on segmentation and classification performance. The results show that our propose architectures significantly reduce computational costs while maintaining or improving downstream task performance compared to state-of-the-art methods. While other diffusion models generated more realistic-looking echo images at higher computational cost, our research suggests that for model training, visual realism is not necessarily related to model performance, and considerable compute costs can be saved by using more efficient models.
Multi-Site Class-Incremental Learning with Weighted Experts in Echocardiography
Jul 31, 2024Building an echocardiography view classifier that maintains performance in real-life cases requires diverse multi-site data, and frequent updates with newly available data to mitigate model drift. Simply fine-tuning on new datasets results in "catastrophic forgetting", and cannot adapt to variations of view labels between sites. Alternatively, collecting all data on a single server and re-training may not be feasible as data sharing agreements may restrict image transfer, or datasets may only become available at different times. Furthermore, time and cost associated with re-training grows with every new dataset. We propose a class-incremental learning method which learns an expert network for each dataset, and combines all expert networks with a score fusion model. The influence of ``unqualified experts'' is minimised by weighting each contribution with a learnt in-distribution score. These weights promote transparency as the contribution of each expert is known during inference. Instead of using the original images, we use learned features from each dataset, which are easier to share and raise fewer licensing and privacy concerns. We validate our work on six datasets from multiple sites, demonstrating significant reductions in training time while improving view classification performance.
BackMix: Mitigating Shortcut Learning in Echocardiography with Minimal Supervision
Jun 27, 2024
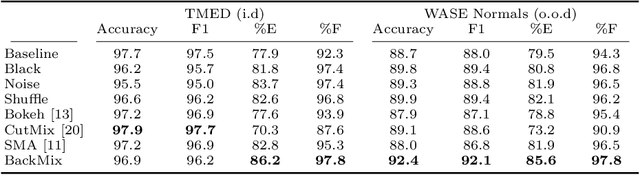
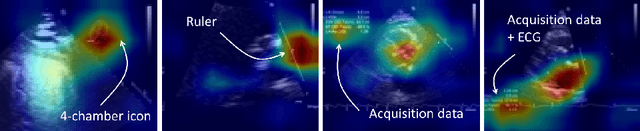
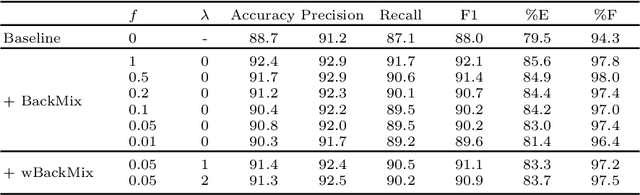
Neural networks can learn spurious correlations that lead to the correct prediction in a validation set, but generalise poorly because the predictions are right for the wrong reason. This undesired learning of naive shortcuts (Clever Hans effect) can happen for example in echocardiogram view classification when background cues (e.g. metadata) are biased towards a class and the model learns to focus on those background features instead of on the image content. We propose a simple, yet effective random background augmentation method called BackMix, which samples random backgrounds from other examples in the training set. By enforcing the background to be uncorrelated with the outcome, the model learns to focus on the data within the ultrasound sector and becomes invariant to the regions outside this. We extend our method in a semi-supervised setting, finding that the positive effects of BackMix are maintained with as few as 5% of segmentation labels. A loss weighting mechanism, wBackMix, is also proposed to increase the contribution of the augmented examples. We validate our method on both in-distribution and out-of-distribution datasets, demonstrating significant improvements in classification accuracy, region focus and generalisability. Our source code is available at: https://github.com/kitbransby/BackMix
Robustness Testing of Black-Box Models Against CT Degradation Through Test-Time Augmentation
Jun 27, 2024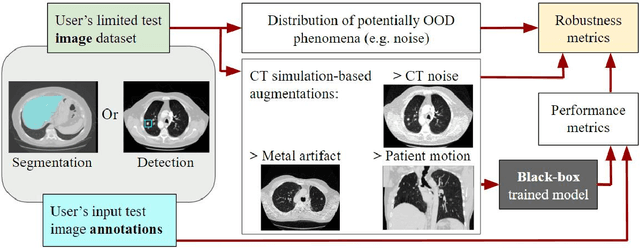
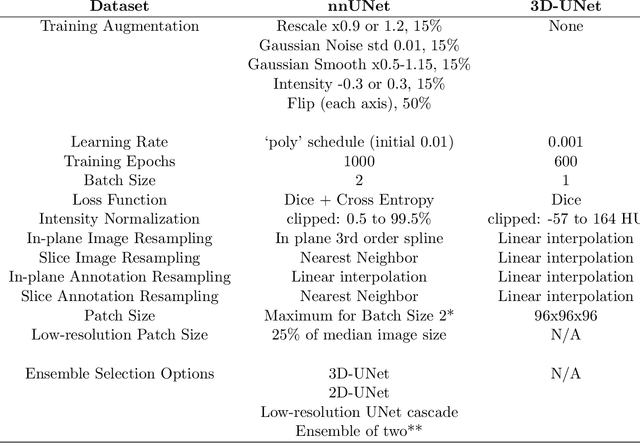
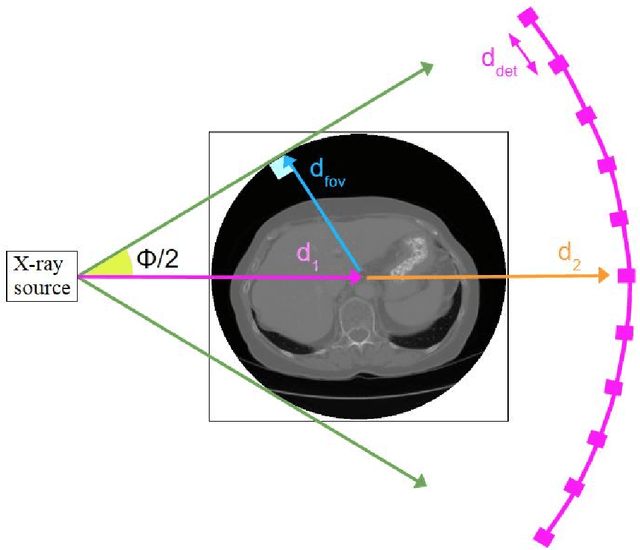

Deep learning models for medical image segmentation and object detection are becoming increasingly available as clinical products. However, as details are rarely provided about the training data, models may unexpectedly fail when cases differ from those in the training distribution. An approach allowing potential users to independently test the robustness of a model, treating it as a black box and using only a few cases from their own site, is key for adoption. To address this, a method to test the robustness of these models against CT image quality variation is presented. In this work we present this framework by demonstrating that given the same training data, the model architecture and data pre processing greatly affect the robustness of several frequently used segmentation and object detection methods to simulated CT imaging artifacts and degradation. Our framework also addresses the concern about the sustainability of deep learning models in clinical use, by considering future shifts in image quality due to scanner deterioration or imaging protocol changes which are not reflected in a limited local test dataset.
Echo from noise: synthetic ultrasound image generation using diffusion models for real image segmentation
May 09, 2023We propose a novel pipeline for the generation of synthetic images via Denoising Diffusion Probabilistic Models (DDPMs) guided by cardiac ultrasound semantic label maps. We show that these synthetic images can serve as a viable substitute for real data in the training of deep-learning models for medical image analysis tasks such as image segmentation. To demonstrate the effectiveness of this approach, we generated synthetic 2D echocardiography images and trained a neural network for segmentation of the left ventricle and left atrium. The performance of the network trained on exclusively synthetic images was evaluated on an unseen dataset of real images and yielded mean Dice scores of 88.5 $\pm 6.0$ , 92.3 $\pm 3.9$, 86.3 $\pm 10.7$ \% for left ventricular endocardial, epicardial and left atrial segmentation respectively. This represents an increase of $9.09$, $3.7$ and $15.0$ \% in Dice scores compared to the previous state-of-the-art. The proposed pipeline has the potential for application to a wide range of other tasks across various medical imaging modalities.
Efficient Pix2Vox++ for 3D Cardiac Reconstruction from 2D echo views
Jul 27, 2022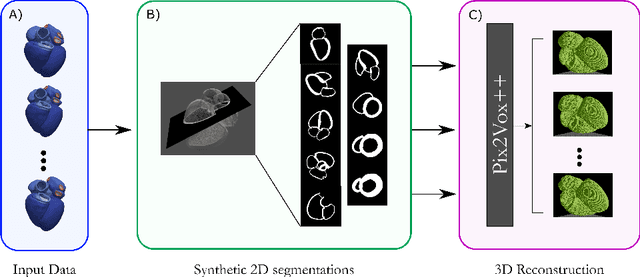

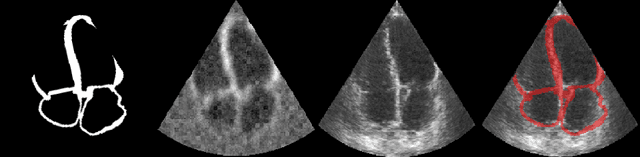
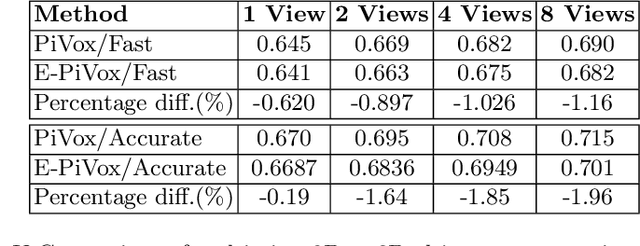
Accurate geometric quantification of the human heart is a key step in the diagnosis of numerous cardiac diseases, and in the management of cardiac patients. Ultrasound imaging is the primary modality for cardiac imaging, however acquisition requires high operator skill, and its interpretation and analysis is difficult due to artifacts. Reconstructing cardiac anatomy in 3D can enable discovery of new biomarkers and make imaging less dependent on operator expertise, however most ultrasound systems only have 2D imaging capabilities. We propose both a simple alteration to the Pix2Vox++ networks for a sizeable reduction in memory usage and computational complexity, and a pipeline to perform reconstruction of 3D anatomy from 2D standard cardiac views, effectively enabling 3D anatomical reconstruction from limited 2D data. We evaluate our pipeline using synthetically generated data achieving accurate 3D whole-heart reconstructions (peak intersection over union score > 0.88) from just two standard anatomical 2D views of the heart. We also show preliminary results using real echo images.
CRISP - Reliable Uncertainty Estimation for Medical Image Segmentation
Jun 15, 2022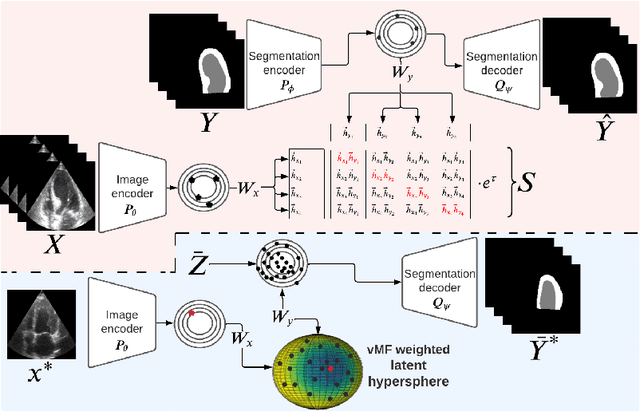
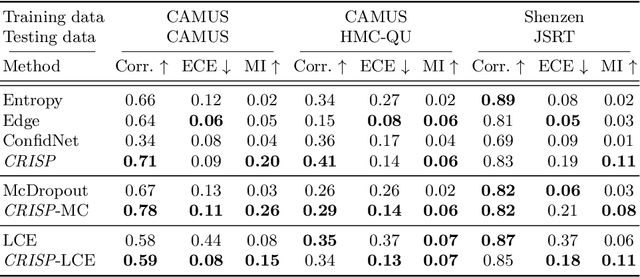
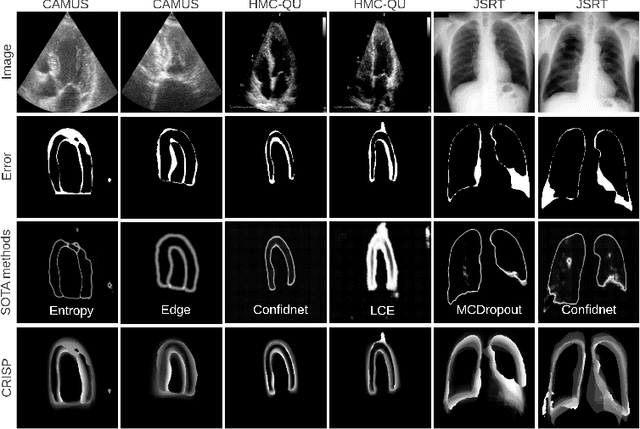
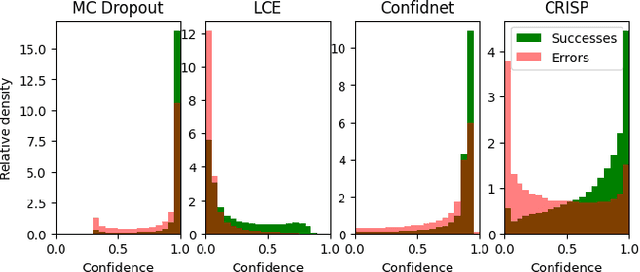
Accurate uncertainty estimation is a critical need for the medical imaging community. A variety of methods have been proposed, all direct extensions of classification uncertainty estimations techniques. The independent pixel-wise uncertainty estimates, often based on the probabilistic interpretation of neural networks, do not take into account anatomical prior knowledge and consequently provide sub-optimal results to many segmentation tasks. For this reason, we propose CRISP a ContRastive Image Segmentation for uncertainty Prediction method. At its core, CRISP implements a contrastive method to learn a joint latent space which encodes a distribution of valid segmentations and their corresponding images. We use this joint latent space to compare predictions to thousands of latent vectors and provide anatomically consistent uncertainty maps. Comprehensive studies performed on four medical image databases involving different modalities and organs underlines the superiority of our method compared to state-of-the-art approaches.
D'ARTAGNAN: Counterfactual Video Generation
Jun 03, 2022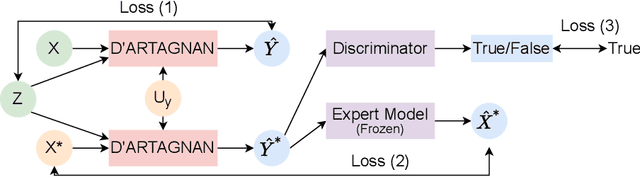


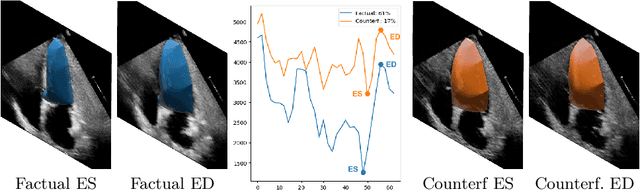
Causally-enabled machine learning frameworks could help clinicians to identify the best course of treatments by answering counterfactual questions. We explore this path for the case of echocardiograms by looking into the variation of the Left Ventricle Ejection Fraction, the most essential clinical metric gained from these examinations. We combine deep neural networks, twin causal networks and generative adversarial methods for the first time to build D'ARTAGNAN (Deep ARtificial Twin-Architecture GeNerAtive Networks), a novel causal generative model. We demonstrate the soundness of our approach on a synthetic dataset before applying it to cardiac ultrasound videos by answering the question: "What would this echocardiogram look like if the patient had a different ejection fraction?". To do so, we generate new ultrasound videos, retaining the video style and anatomy of the original patient, with variations of the Ejection Fraction conditioned on a given input. We achieve an SSIM score of 0.79 and an R2 score of 0.51 on the counterfactual videos. Code and models are available at https://github.com/HReynaud/dartagnan.
Contrastive Learning for View Classification of Echocardiograms
Aug 06, 2021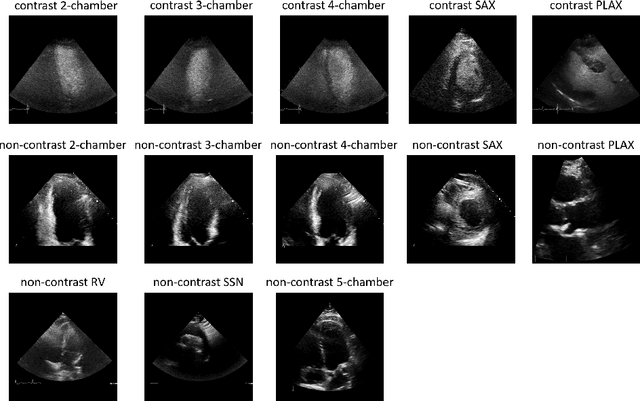
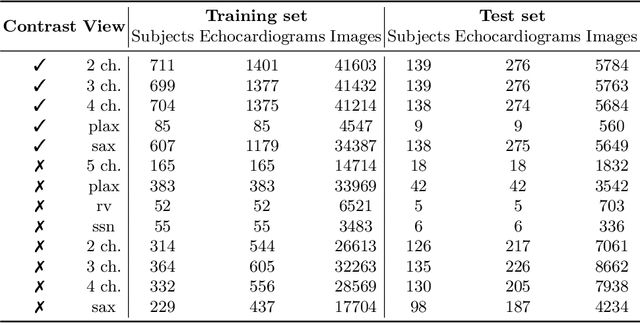
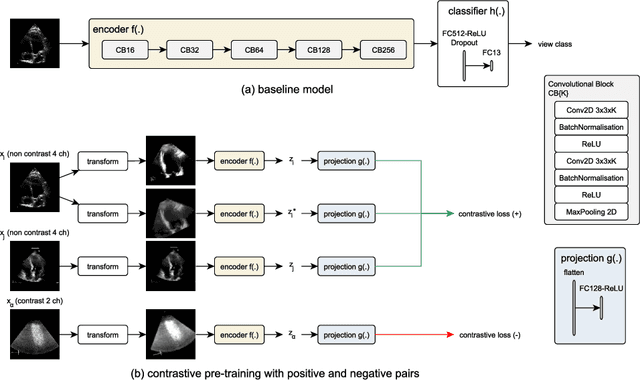
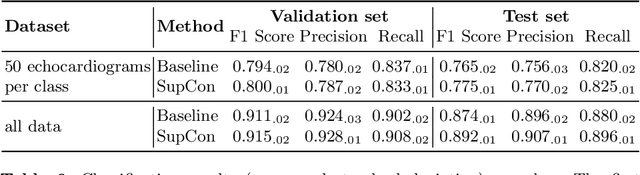
Analysis of cardiac ultrasound images is commonly performed in routine clinical practice for quantification of cardiac function. Its increasing automation frequently employs deep learning networks that are trained to predict disease or detect image features. However, such models are extremely data-hungry and training requires labelling of many thousands of images by experienced clinicians. Here we propose the use of contrastive learning to mitigate the labelling bottleneck. We train view classification models for imbalanced cardiac ultrasound datasets and show improved performance for views/classes for which minimal labelled data is available. Compared to a naive baseline model, we achieve an improvement in F1 score of up to 26% in those views while maintaining state-of-the-art performance for the views with sufficiently many labelled training observations.