 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for View Classification of Echocardiograms
Aug 06, 2021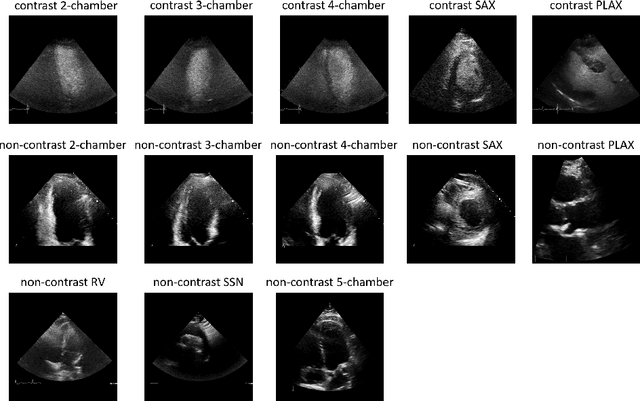
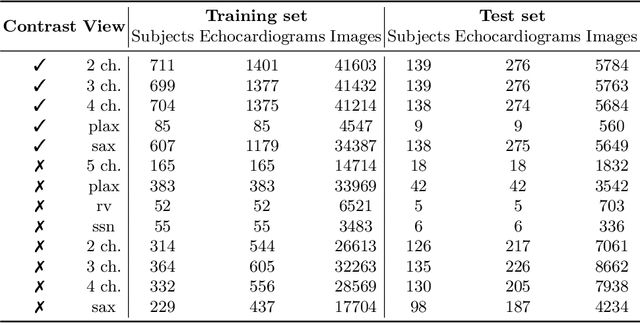
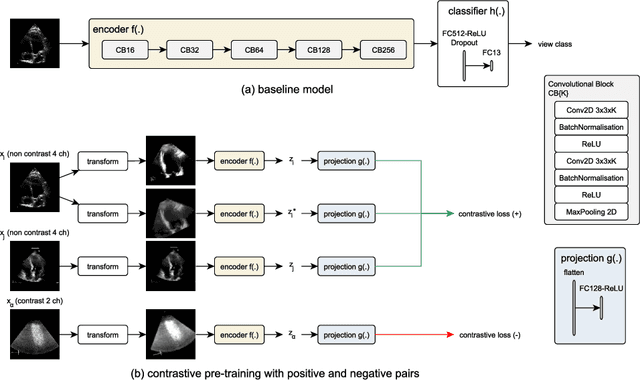
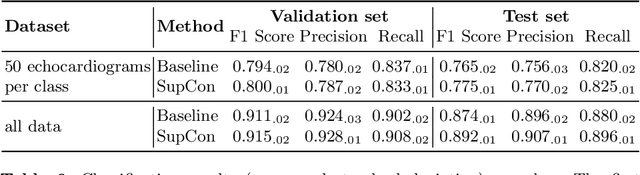
Analysis of cardiac ultrasound images is commonly performed in routine clinical practice for quantification of cardiac function. Its increasing automation frequently employs deep learning networks that are trained to predict disease or detect image features. However, such models are extremely data-hungry and training requires labelling of many thousands of images by experienced clinicians. Here we propose the use of contrastive learning to mitigate the labelling bottleneck. We train view classification models for imbalanced cardiac ultrasound datasets and show improved performance for views/classes for which minimal labelled data is available. Compared to a naive baseline model, we achieve an improvement in F1 score of up to 26% in those views while maintaining state-of-the-art performance for the views with sufficiently many labelled training observations.