 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness Testing of Black-Box Models Against CT Degradation Through Test-Time Augmentation
Jun 27, 2024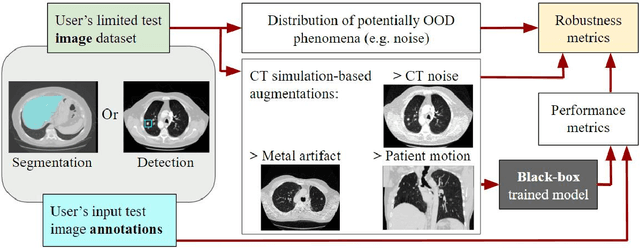
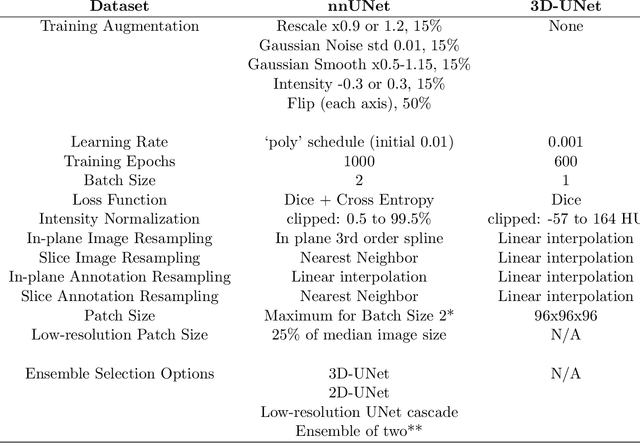
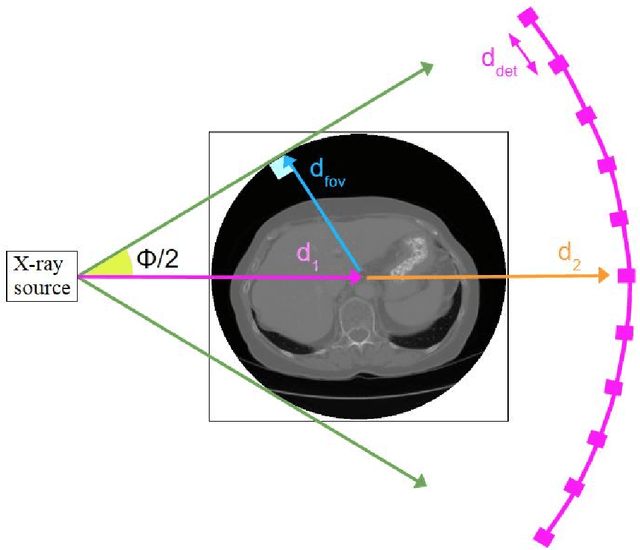

Deep learning models for medical image segmentation and object detection are becoming increasingly available as clinical products. However, as details are rarely provided about the training data, models may unexpectedly fail when cases differ from those in the training distribution. An approach allowing potential users to independently test the robustness of a model, treating it as a black box and using only a few cases from their own site, is key for adoption. To address this, a method to test the robustness of these models against CT image quality variation is presented. In this work we present this framework by demonstrating that given the same training data, the model architecture and data pre processing greatly affect the robustness of several frequently used segmentation and object detection methods to simulated CT imaging artifacts and degradation. Our framework also addresses the concern about the sustainability of deep learning models in clinical use, by considering future shifts in image quality due to scanner deterioration or imaging protocol changes which are not reflected in a limited local test dataset.