 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoFlow: A Foundation Model for Cardiac Ultrasound Image and Video Generation
Mar 28, 2025



Advances in deep learning have significantly enhanced medical image analysis, yet the availability of large-scale medical datasets remains constrained by patient privacy concerns. We present EchoFlow, a novel framework designed to generate high-quality, privacy-preserving synthetic echocardiogram images and videos. EchoFlow comprises four key components: an adversarial variational autoencoder for defining an efficient latent representation of cardiac ultrasound images, a latent image flow matching model for generating accurate latent echocardiogram images, a latent re-identification model to ensure privacy by filtering images anatomically, and a latent video flow matching model for animating latent images into realistic echocardiogram videos conditioned on ejection fraction. We rigorously evaluate our synthetic datasets on the clinically relevant task of ejection fraction regression and demonstrate, for the first time, that downstream models trained exclusively on EchoFlow-generated synthetic datasets achieve performance parity with models trained on real datasets. We release our models and synthetic datasets, enabling broader, privacy-compliant research in medical ultrasound imaging at https://huggingface.co/spaces/HReynaud/EchoFlow.
EchoNet-Synthetic: Privacy-preserving Video Generation for Safe Medical Data Sharing
Jun 02, 2024To make medical datasets accessible without sharing sensitive patient information, we introduce a novel end-to-end approach for generative de-identification of dynamic medical imaging data. Until now, generative methods have faced constraints in terms of fidelity, spatio-temporal coherence, and the length of generation, failing to capture the complete details of dataset distributions. We present a model designed to produce high-fidelity, long and complete data samples with near-real-time efficiency and explore our approach on a challenging task: generating echocardiogram videos. We develop our generation method based on diffusion models and introduce a protocol for medical video dataset anonymization. As an exemplar, we present EchoNet-Synthetic, a fully synthetic, privacy-compliant echocardiogram dataset with paired ejection fraction labels. As part of our de-identification protocol, we evaluate the quality of the generated dataset and propose to use clinical downstream tasks as a measurement on top of widely used but potentially biased image quality metrics. Experimental outcomes demonstrate that EchoNet-Synthetic achieves comparable dataset fidelity to the actual dataset, effectively supporting the ejection fraction regression task. Code, weights and dataset are available at https://github.com/HReynaud/EchoNet-Synthetic.
Feature-Conditioned Cascaded Video Diffusion Models for Precise Echocardiogram Synthesis
Mar 23, 2023Image synthesis is expected to provide value for the translation of machine learning methods into clinical practice. Fundamental problems like model robustness, domain transfer, causal modelling, and operator training become approachable through synthetic data. Especially, heavily operator-dependant modalities like Ultrasound imaging require robust frameworks for image and video generation. So far, video generation has only been possible by providing input data that is as rich as the output data, e.g., image sequence plus conditioning in, video out. However, clinical documentation is usually scarce and only single images are reported and stored, thus retrospective patient-specific analysis or the generation of rich training data becomes impossible with current approaches. In this paper, we extend elucidated diffusion models for video modelling to generate plausible video sequences from single images and arbitrary conditioning with clinical parameters. We explore this idea within the context of echocardiograms by looking into the variation of the Left Ventricle Ejection Fraction, the most essential clinical metric gained from these examinations. We use the publicly available EchoNet-Dynamic dataset for all our experiments. Our image to sequence approach achieves an $R^2$ score of 93%, which is 38 points higher than recently proposed sequence to sequence generation methods. Code and models will be available at: https://github.com/HReynaud/EchoDiffusion.
D'ARTAGNAN: Counterfactual Video Generation
Jun 03, 2022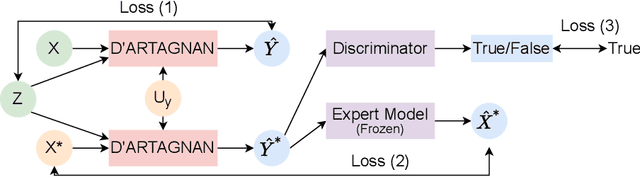


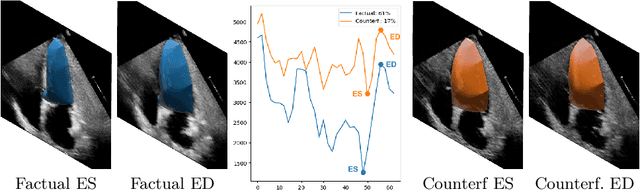
Causally-enabled machine learning frameworks could help clinicians to identify the best course of treatments by answering counterfactual questions. We explore this path for the case of echocardiograms by looking into the variation of the Left Ventricle Ejection Fraction, the most essential clinical metric gained from these examinations. We combine deep neural networks, twin causal networks and generative adversarial methods for the first time to build D'ARTAGNAN (Deep ARtificial Twin-Architecture GeNerAtive Networks), a novel causal generative model. We demonstrate the soundness of our approach on a synthetic dataset before applying it to cardiac ultrasound videos by answering the question: "What would this echocardiogram look like if the patient had a different ejection fraction?". To do so, we generate new ultrasound videos, retaining the video style and anatomy of the original patient, with variations of the Ejection Fraction conditioned on a given input. We achieve an SSIM score of 0.79 and an R2 score of 0.51 on the counterfactual videos. Code and models are available at https://github.com/HReynaud/dartagnan.
Ultrasound Video Transformers for Cardiac Ejection Fraction Estimation
Jul 02, 2021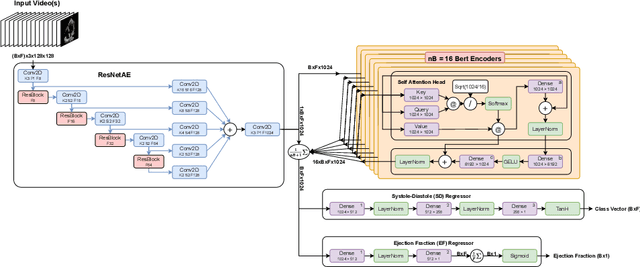
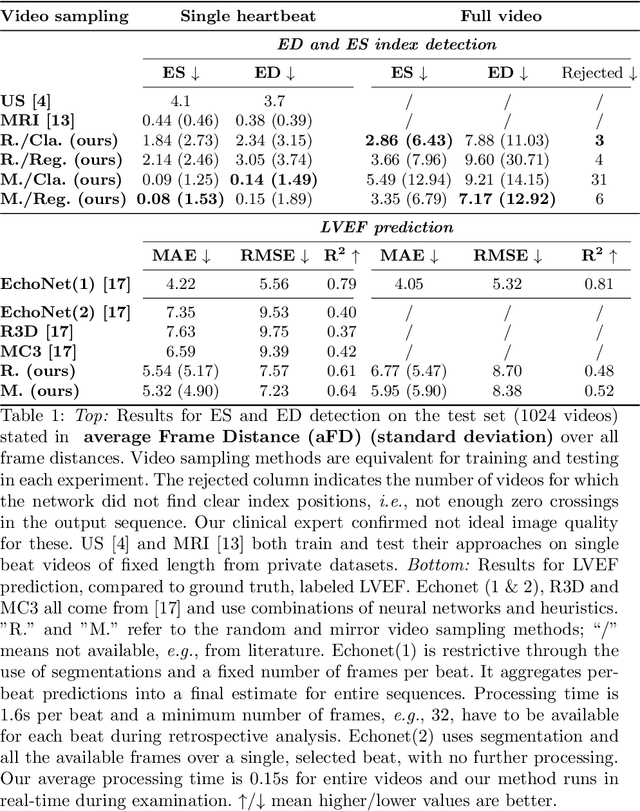

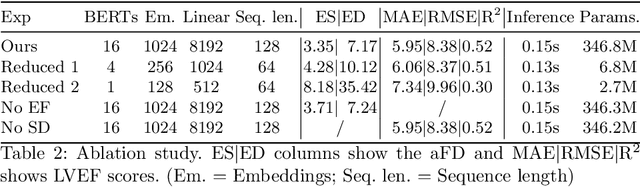
Cardiac ultrasound imaging is used to diagnose various heart diseases. Common analysis pipelines involve manual processing of the video frames by expert clinicians. This suffers from intra- and inter-observer variability. We propose a novel approach to ultrasound video analysis using a transformer architecture based on a Residual Auto-Encoder Network and a BERT model adapted for token classification. This enables videos of any length to be processed. We apply our model to the task of End-Systolic (ES) and End-Diastolic (ED) frame detection and the automated computation of the left ventricular ejection fraction. We achieve an average frame distance of 3.36 frames for the ES and 7.17 frames for the ED on videos of arbitrary length. Our end-to-end learnable approach can estimate the ejection fraction with a MAE of 5.95 and $R^2$ of 0.52 in 0.15s per video, showing that segmentation is not the only way to predict ejection fraction. Code and models are available at https://github.com/HReynaud/UVT.