 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Segmentation of Colonoscopy Images
Dec 19, 2023



Colonoscopy plays a crucial role in the diagnosis and prognosis of various gastrointestinal diseases. Due to the challenges of collecting large-scale high-quality ground truth annotations for colonoscopy images, and more generally medical images, we explore using self-supervised features from vision transformers in three challenging tasks for colonoscopy images. Our results indicate that image-level features learned from DINO models achieve image classification performance comparable to fully supervised models, and patch-level features contain rich semantic information for object detection. Furthermore, we demonstrate that self-supervised features combined with unsupervised segmentation can be used to discover multiple clinically relevant structures in a fully unsupervised manner, demonstrating the tremendous potential of applying these methods in medical image analysis.
Discriminative and Generative Models for Anatomical Shape Analysison Point Clouds with Deep Neural Networks
Oct 02, 2020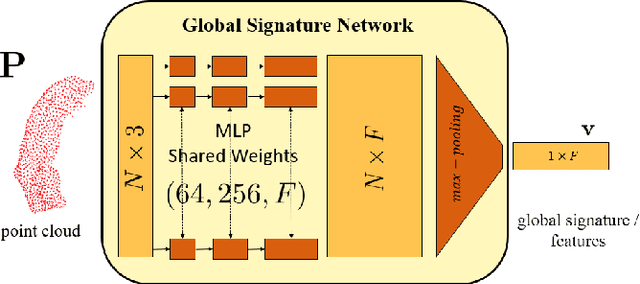
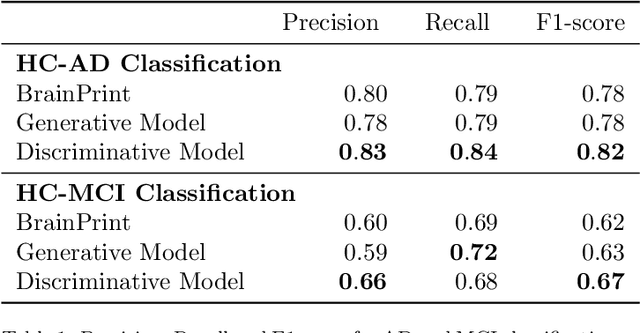
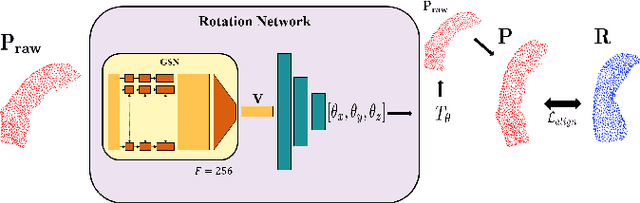
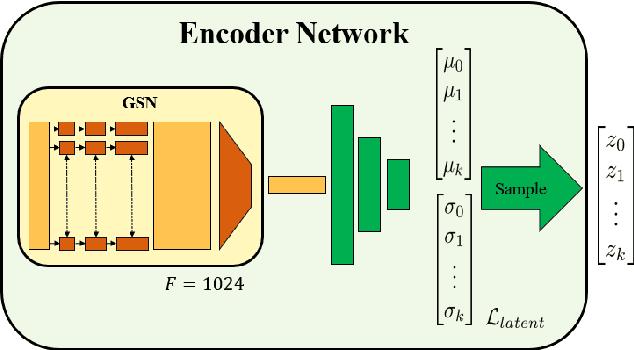
We introduce deep neural networks for the analysis of anatomical shapes that learn a low-dimensional shape representation from the given task, instead of relying on hand-engineered representations. Our framework is modular and consists of several computing blocks that perform fundamental shape processing tasks. The networks operate on unordered point clouds and provide invariance to similarity transformations, avoiding the need to identify point correspondences between shapes. Based on the framework, we assemble a discriminative model for disease classification and age regression, as well as a generative model for the accruate reconstruction of shapes. In particular, we propose a conditional generative model, where the condition vector provides a mechanism to control the generative process. instance, it enables to assess shape variations specific to a particular diagnosis, when passing it as side information. Next to working on single shapes, we introduce an extension for the joint analysis of multiple anatomical structures, where the simultaneous modeling of multiple structures can lead to a more compact encoding and a better understanding of disorders. We demonstrate the advantages of our framework in comprehensive experiments on real and synthetic data. The key insights are that (i) learning a shape representation specific to the given task yields higher performance than alternative shape descriptors, (ii) multi-structure analysis is both more efficient and more accurate than single-structure analysis, and (iii) point clouds generated by our model capture morphological differences associated to Alzheimers disease, to the point that they can be used to train a discriminative model for disease classification. Our framework naturally scales to the analysis of large datasets, giving it the potential to learn characteristic variations in large populations.
Quantifying Confounding Bias in Neuroimaging Datasets with Causal Inference
Jul 09, 2019
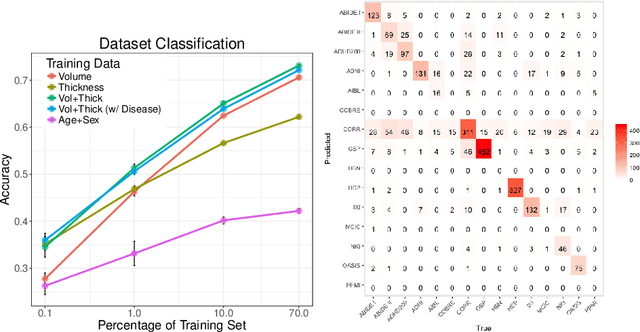
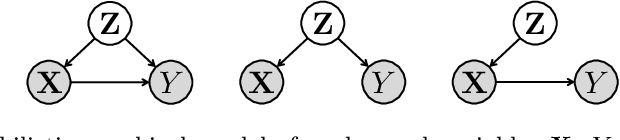
Neuroimaging datasets keep growing in size to address increasingly complex medical questions. However, even the largest datasets today alone are too small for training complex machine learning models. A potential solution is to increase sample size by pooling scans from several datasets. In this work, we combine 12,207 MRI scans from 15 studies and show that simple pooling is often ill-advised due to introducing various types of biases in the training data. First, we systematically define these biases. Second, we detect bias by experimentally showing that scans can be correctly assigned to their respective dataset with 73.3% accuracy. Finally, we propose to tell causal from confounding factors by quantifying the extent of confounding and causality in a single dataset using causal inference. We achieve this by finding the simplest graphical model in terms of Kolmogorov complexity. As Kolmogorov complexity is not directly computable, we employ the minimum description length to approximate it. We empirically show that our approach is able to estimate plausible causal relationships from real neuroimaging data.
Detect, Quantify, and Incorporate Dataset Bias: A Neuroimaging Analysis on 12,207 Individuals
Apr 28, 2018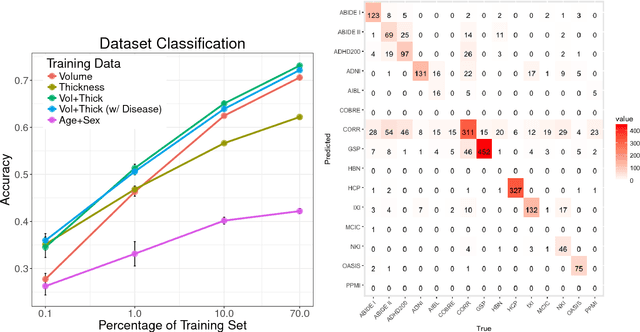
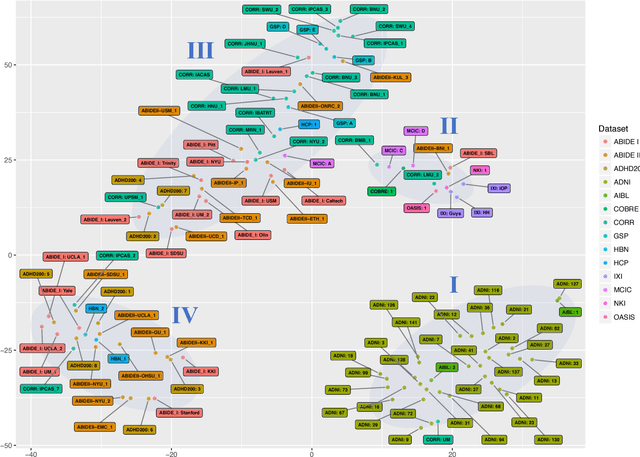
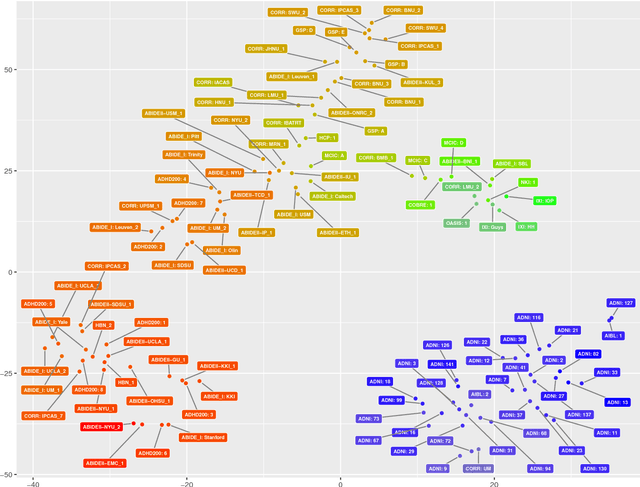
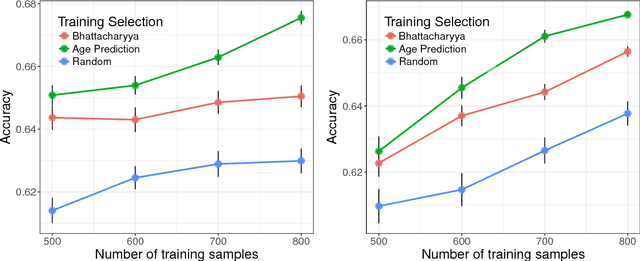
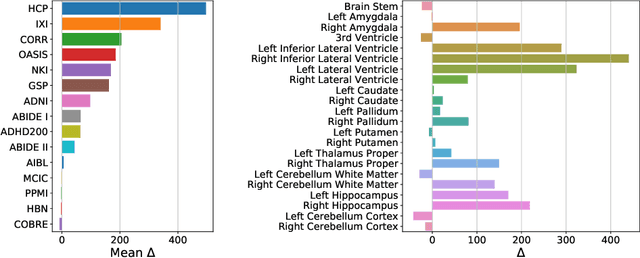
Neuroimaging datasets keep growing in size to address increasingly complex medical questions. However, even the largest datasets today alone are too small for training complex models or for finding genome wide associations. A solution is to grow the sample size by merging data across several datasets. However, bias in datasets complicates this approach and includes additional sources of variation in the data instead. In this work, we combine 15 large neuroimaging datasets to study bias. First, we detect bias by demonstrating that scans can be correctly assigned to a dataset with 73.3% accuracy. Next, we introduce metrics to quantify the compatibility across datasets and to create embeddings of neuroimaging sites. Finally, we incorporate the presence of bias for the selection of a training set for predicting autism. For the quantification of the dataset bias, we introduce two metrics: the Bhattacharyya distance between datasets and the age prediction error. The presented embedding of neuroimaging sites provides an interesting new visualization about the similarity of different sites. This could be used to guide the merging of data sources, while limiting the introduction of unwanted variation. Finally, we demonstrate a clear performance increase when incorporating dataset bias for training set selection in autism prediction. Overall, we believe that the growing amount of neuroimaging data necessitates to incorporate data-driven methods for quantifying dataset bias in future analyses.
Gaussian Process Uncertainty in Age Estimation as a Measure of Brain Abnormality
Apr 04, 2018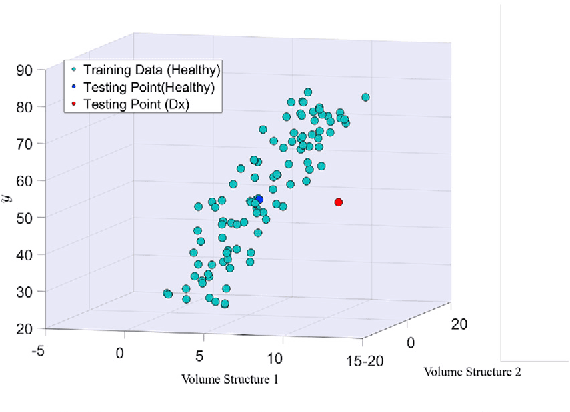
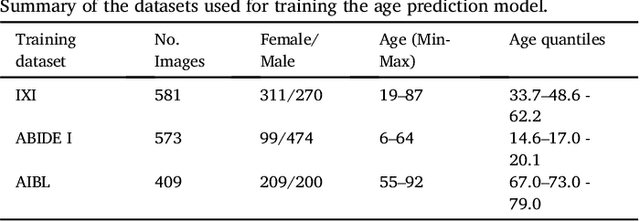
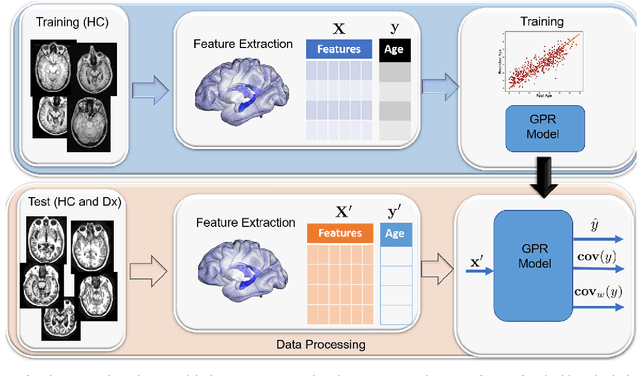
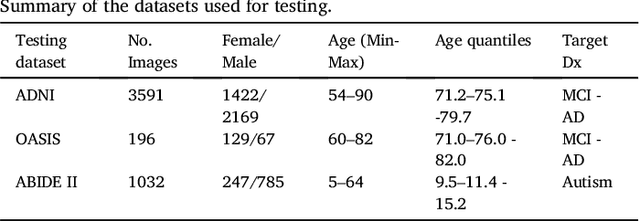
Multivariate regression models for age estimation are a powerful tool for assessing abnormal brain morphology associated to neuropathology. Age prediction models are built on cohorts of healthy subjects and are built to reflect normal aging patterns. The application of these multivariate models to diseased subjects usually results in high prediction errors, under the hypothesis that neuropathology presents a similar degenerative pattern as that of accelerated aging. In this work, we propose an alternative to the idea that pathology follows a similar trajectory than normal aging. Instead, we propose the use of metrics which measure deviations from the mean aging trajectory. We propose to measure these deviations using two different metrics: uncertainty in a Gaussian process regression model and a newly proposed age weighted uncertainty measure. Consequently, our approach assumes that pathologic brain patterns are different to those of normal aging. We present results for subjects with autism, mild cognitive impairment and Alzheimer's disease to highlight the versatility of the approach to different diseases and age ranges. We evaluate volume, thickness, and VBM features for quantifying brain morphology. Our evaluations are performed on a large number of images obtained from a variety of publicly available neuroimaging databases. Across all features, our uncertainty based measurements yield a better separation between diseased subjects and healthy individuals than the prediction error. Finally, we illustrate differences in the disease pattern to normal aging, supporting the application of uncertainty as a measure of neuropathology.