 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Confounding Bias in Neuroimaging Datasets with Causal Inference
Paper and Code
Jul 09, 2019
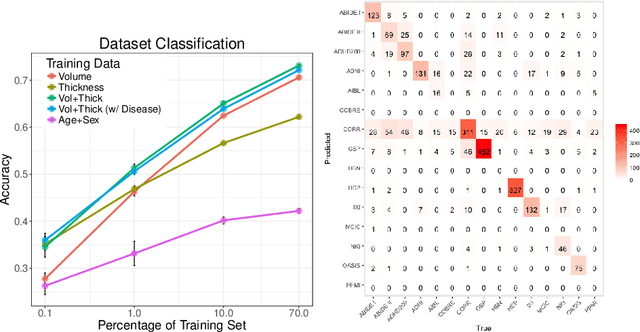
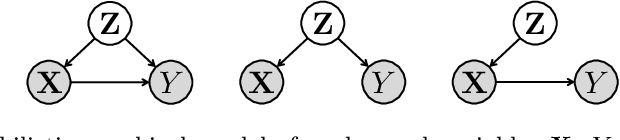
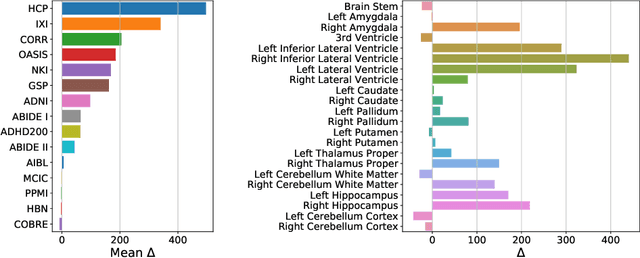
Neuroimaging datasets keep growing in size to address increasingly complex medical questions. However, even the largest datasets today alone are too small for training complex machine learning models. A potential solution is to increase sample size by pooling scans from several datasets. In this work, we combine 12,207 MRI scans from 15 studies and show that simple pooling is often ill-advised due to introducing various types of biases in the training data. First, we systematically define these biases. Second, we detect bias by experimentally showing that scans can be correctly assigned to their respective dataset with 73.3% accuracy. Finally, we propose to tell causal from confounding factors by quantifying the extent of confounding and causality in a single dataset using causal inference. We achieve this by finding the simplest graphical model in terms of Kolmogorov complexity. As Kolmogorov complexity is not directly computable, we employ the minimum description length to approximate it. We empirically show that our approach is able to estimate plausible causal relationships from real neuroimaging data.