 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Shape and Appearance Priors for Few-Shot Full Head Reconstruction
Oct 12, 2023
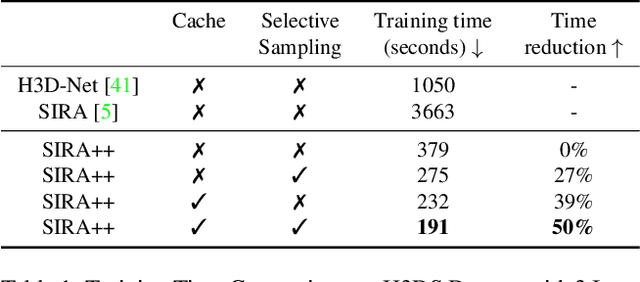
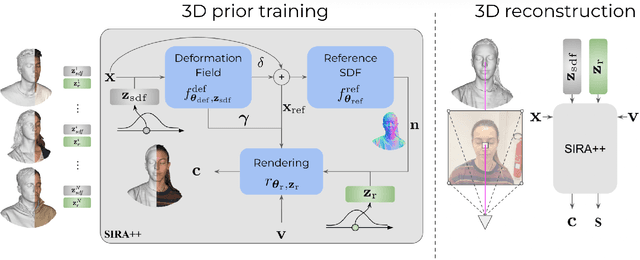
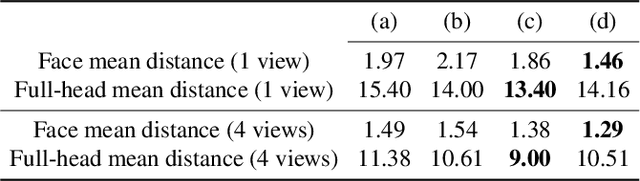
Recent advancements in learning techniques that employ coordinate-based neural representations have yielded remarkable results in multi-view 3D reconstruction tasks. However, these approaches often require a substantial number of input views (typically several tens) and computationally intensive optimization procedures to achieve their effectiveness. In this paper, we address these limitations specifically for the problem of few-shot full 3D head reconstruction. We accomplish this by incorporating a probabilistic shape and appearance prior into coordinate-based representations, enabling faster convergence and improved generalization when working with only a few input images (even as low as a single image). During testing, we leverage this prior to guide the fitting process of a signed distance function using a differentiable renderer. By incorporating the statistical prior alongside parallelizable ray tracing and dynamic caching strategies, we achieve an efficient and accurate approach to few-shot full 3D head reconstruction. Moreover, we extend the H3DS dataset, which now comprises 60 high-resolution 3D full head scans and their corresponding posed images and masks, which we use for evaluation purposes. By leveraging this dataset, we demonstrate the remarkable capabilities of our approach in achieving state-of-the-art results in geometry reconstruction while being an order of magnitude faster than previous approaches.
InstantAvatar: Efficient 3D Head Reconstruction via Surface Rendering
Aug 10, 2023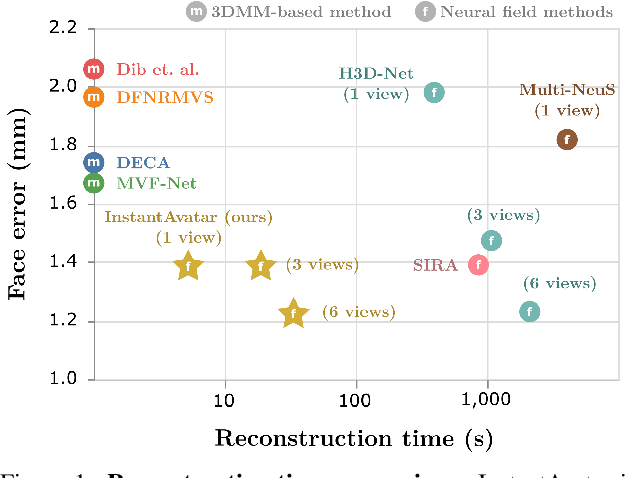
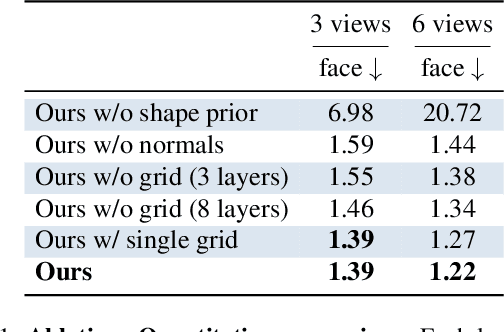
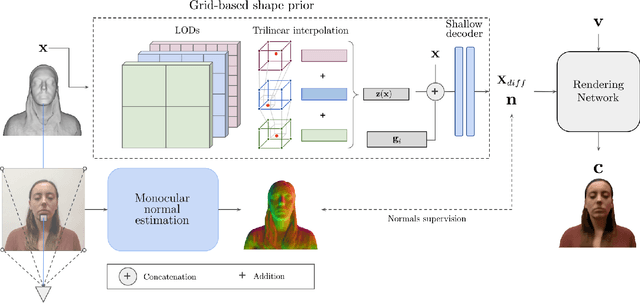
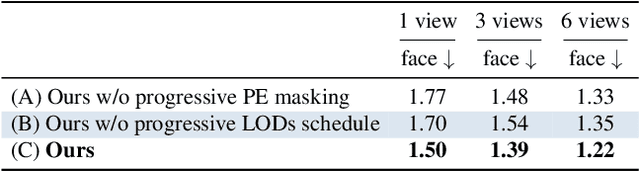
Recent advances in full-head reconstruction have been obtained by optimizing a neural field through differentiable surface or volume rendering to represent a single scene. While these techniques achieve an unprecedented accuracy, they take several minutes, or even hours, due to the expensive optimization process required. In this work, we introduce InstantAvatar, a method that recovers full-head avatars from few images (down to just one) in a few seconds on commodity hardware. In order to speed up the reconstruction process, we propose a system that combines, for the first time, a voxel-grid neural field representation with a surface renderer. Notably, a naive combination of these two techniques leads to unstable optimizations that do not converge to valid solutions. In order to overcome this limitation, we present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid based architecture. The use of this prior model, in combination with other design choices, results into a system that achieves 3D head reconstructions with comparable accuracy as the state-of-the-art with a 100x speed-up.
Photorealistic Facial Wrinkles Removal
Nov 03, 2022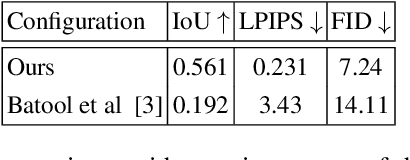

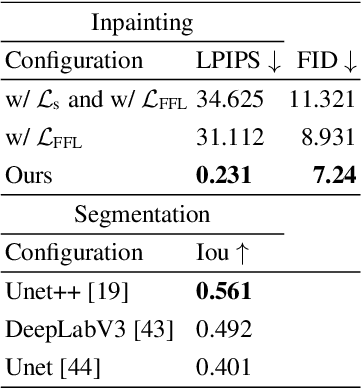
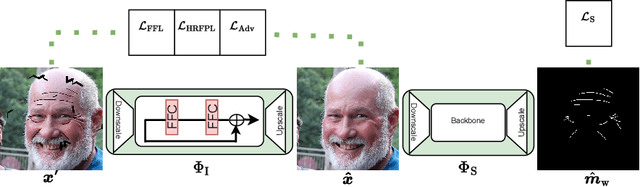
Editing and retouching facial attributes is a complex task that usually requires human artists to obtain photo-realistic results. Its applications are numerous and can be found in several contexts such as cosmetics or digital media retouching, to name a few. Recently, advancements in conditional generative modeling have shown astonishing results at modifying facial attributes in a realistic manner. However, current methods are still prone to artifacts, and focus on modifying global attributes like age and gender, or local mid-sized attributes like glasses or moustaches. In this work, we revisit a two-stage approach for retouching facial wrinkles and obtain results with unprecedented realism. First, a state of the art wrinkle segmentation network is used to detect the wrinkles within the facial region. Then, an inpainting module is used to remove the detected wrinkles, filling them in with a texture that is statistically consistent with the surrounding skin. To achieve this, we introduce a novel loss term that reuses the wrinkle segmentation network to penalize those regions that still contain wrinkles after the inpainting. We evaluate our method qualitatively and quantitatively, showing state of the art results for the task of wrinkle removal. Moreover, we introduce the first high-resolution dataset, named FFHQ-Wrinkles, to evaluate wrinkle detection methods.
SIRA: Relightable Avatars from a Single Image
Sep 07, 2022
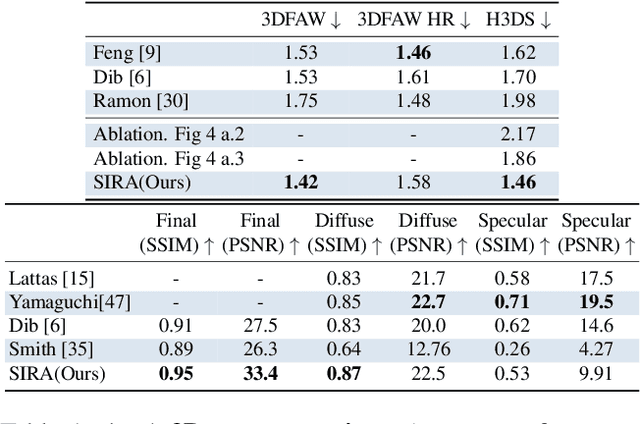


Recovering the geometry of a human head from a single image, while factorizing the materials and illumination is a severely ill-posed problem that requires prior information to be solved. Methods based on 3D Morphable Models (3DMM), and their combination with differentiable renderers, have shown promising results. However, the expressiveness of 3DMMs is limited, and they typically yield over-smoothed and identity-agnostic 3D shapes limited to the face region. Highly accurate full head reconstructions have recently been obtained with neural fields that parameterize the geometry using multilayer perceptrons. The versatility of these representations has also proved effective for disentangling geometry, materials and lighting. However, these methods require several tens of input images. In this paper, we introduce SIRA, a method which, from a single image, reconstructs human head avatars with high fidelity geometry and factorized lights and surface materials. Our key ingredients are two data-driven statistical models based on neural fields that resolve the ambiguities of single-view 3D surface reconstruction and appearance factorization. Experiments show that SIRA obtains state of the art results in 3D head reconstruction while at the same time it successfully disentangles the global illumination, and the diffuse and specular albedos. Furthermore, our reconstructions are amenable to physically-based appearance editing and head model relighting.
H3D-Net: Few-Shot High-Fidelity 3D Head Reconstruction
Jul 26, 2021
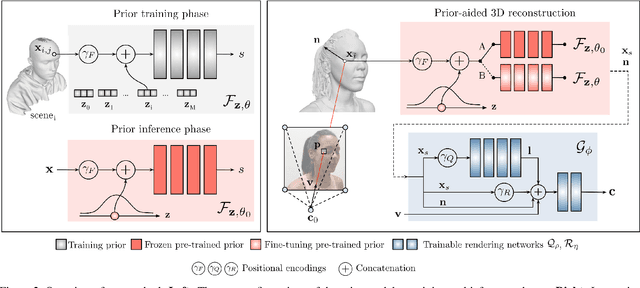


Recent learning approaches that implicitly represent surface geometry using coordinate-based neural representations have shown impressive results in the problem of multi-view 3D reconstruction. The effectiveness of these techniques is, however, subject to the availability of a large number (several tens) of input views of the scene, and computationally demanding optimizations. In this paper, we tackle these limitations for the specific problem of few-shot full 3D head reconstruction, by endowing coordinate-based representations with a probabilistic shape prior that enables faster convergence and better generalization when using few input images (down to three). First, we learn a shape model of 3D heads from thousands of incomplete raw scans using implicit representations. At test time, we jointly overfit two coordinate-based neural networks to the scene, one modeling the geometry and another estimating the surface radiance, using implicit differentiable rendering. We devise a two-stage optimization strategy in which the learned prior is used to initialize and constrain the geometry during an initial optimization phase. Then, the prior is unfrozen and fine-tuned to the scene. By doing this, we achieve high-fidelity head reconstructions, including hair and shoulders, and with a high level of detail that consistently outperforms both state-of-the-art 3D Morphable Models methods in the few-shot scenario, and non-parametric methods when large sets of views are available.
Hyperparameter-Free Losses for Model-Based Monocular Reconstruction
Aug 16, 2019
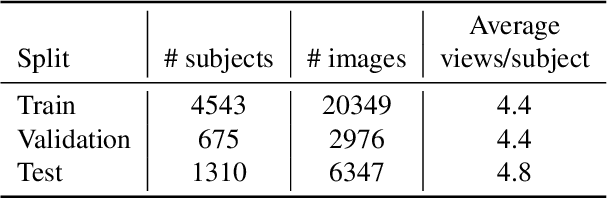

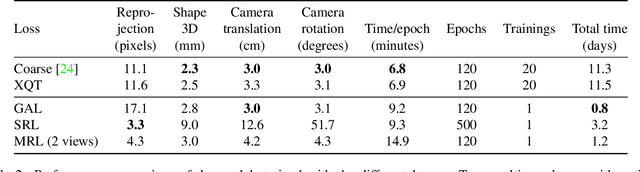
This work proposes novel hyperparameter-free losses for single view 3D reconstruction with morphable models (3DMM). We dispense with the hyperparameters used in other works by exploiting geometry, so that the shape of the object and the camera pose are jointly optimized in a sole term expression. This simplification reduces the optimization time and its complexity. Moreover, we propose a novel implicit regularization technique based on random virtual projections that does not require additional 2D or 3D annotations. Our experiments suggest that minimizing a shape reprojection error together with the proposed implicit regularization is especially suitable for applications that require precise alignment between geometry and image spaces, such as augmented reality. We evaluate our losses on a large scale dataset with 3D ground truth and publish our implementations to facilitate reproducibility and public benchmarking in this field.