 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCRScore: Image captioning metric based on V\&L Transformers, CLIP, and precision-recall
Jan 15, 2025Image captioning has become an essential Vision & Language research task. It is about predicting the most accurate caption given a specific image or video. The research community has achieved impressive results by continuously proposing new models and approaches to improve the overall model's performance. Nevertheless, despite increasing proposals, the performance metrics used to measure their advances have remained practically untouched through the years. A probe of that, nowadays metrics like BLEU, METEOR, CIDEr, and ROUGE are still very used, aside from more sophisticated metrics such as BertScore and ClipScore. Hence, it is essential to adjust how are measure the advances, limitations, and scopes of the new image captioning proposals, as well as to adapt new metrics to these new advanced image captioning approaches. This work proposes a new evaluation metric for the image captioning problem. To do that, first, it was generated a human-labeled dataset to assess to which degree the captions correlate with the image's content. Taking these human scores as ground truth, we propose a new metric, and compare it with several well-known metrics, from classical to newer ones. Outperformed results were also found, and interesting insights were presented and discussed.
Are metrics measuring what they should? An evaluation of image captioning task metrics
Jul 04, 2022

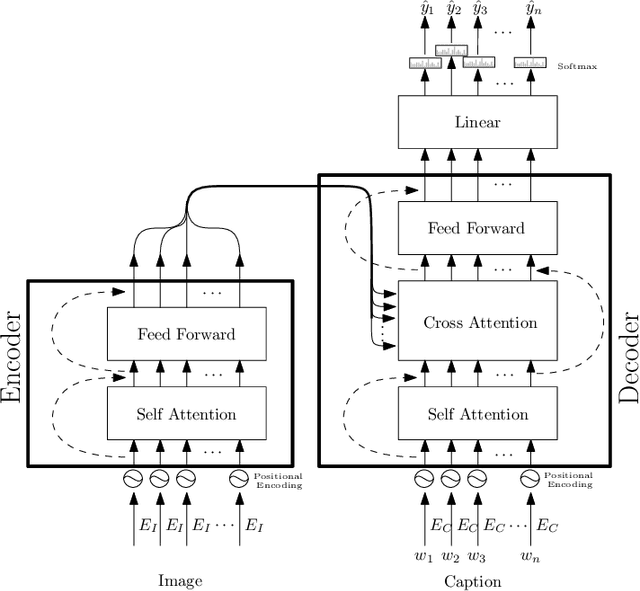

Image Captioning is a current research task to describe the image content using the objects and their relationships in the scene. To tackle this task, two important research areas are used, artificial vision, and natural language processing. In Image Captioning, as in any computational intelligence task, the performance metrics are crucial for knowing how well (or bad) a method performs. In recent years, it has been observed that classical metrics based on n-grams are insufficient to capture the semantics and the critical meaning to describe the content in an image. Looking to measure how well or not the set of current and more recent metrics are doing, in this manuscript, we present an evaluation of several kinds of Image Captioning metrics and a comparison between them using the well-known MS COCO dataset. For this, we designed two scenarios; 1) a set of artificially build captions with several quality, and 2) a comparison of some state-of-the-art Image Captioning methods. We tried to answer the questions: Are the current metrics helping to produce high quality captions? How do actual metrics compare to each other? What are the metrics really measuring?
Video Captioning: a comparative review of where we are and which could be the route
Apr 13, 2022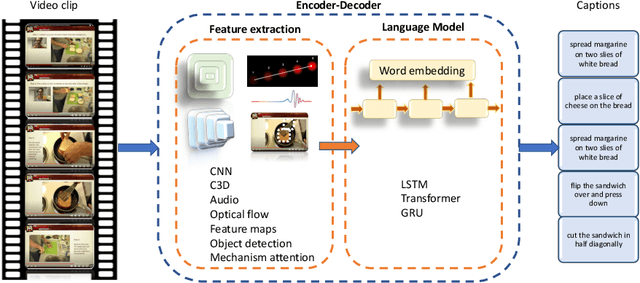
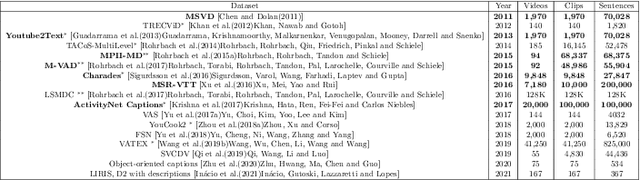
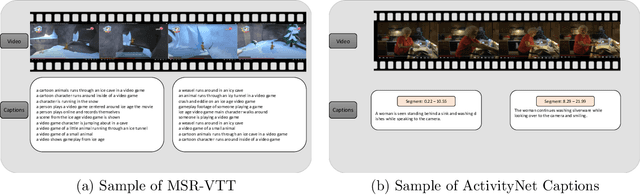

Video captioning is the process of describing the content of a sequence of images capturing its semantic relationships and meanings. Dealing with this task with a single image is arduous, not to mention how difficult it is for a video (or images sequence). The amount and relevance of the applications of video captioning are vast, mainly to deal with a significant amount of video recordings in video surveillance, or assisting people visually impaired, to mention a few. To analyze where the efforts of our community to solve the video captioning task are, as well as what route could be better to follow, this manuscript presents an extensive review of more than 105 papers for the period of 2016 to 2021. As a result, the most-used datasets and metrics are identified. Also, the main approaches used and the best ones. We compute a set of rankings based on several performance metrics to obtain, according to its performance, the best method with the best result on the video captioning task. Finally, some insights are concluded about which could be the next steps or opportunity areas to improve dealing with this complex task.
Similarity search on neighbor's graphs with automatic Pareto optimal performance and minimum expected quality setups based on hyperparameter optimization
Jan 19, 2022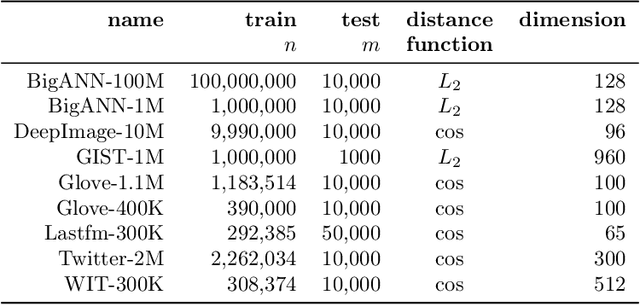
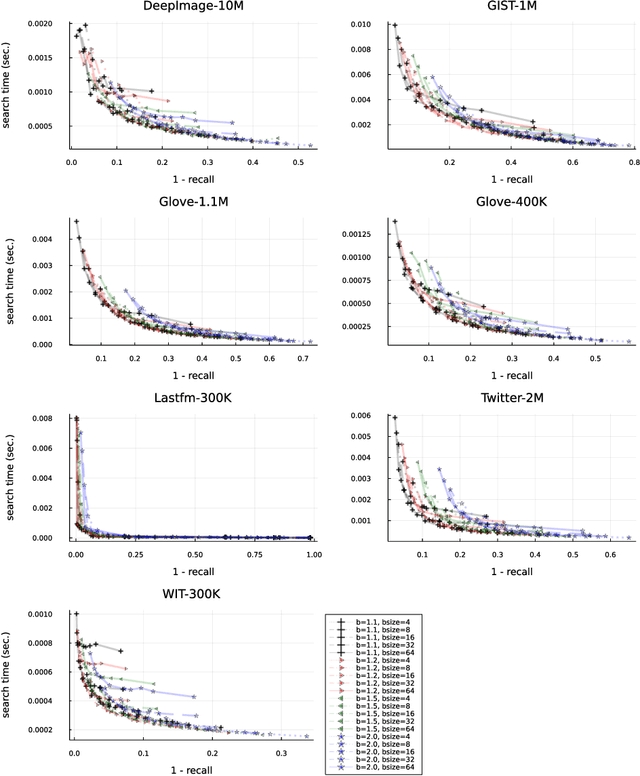

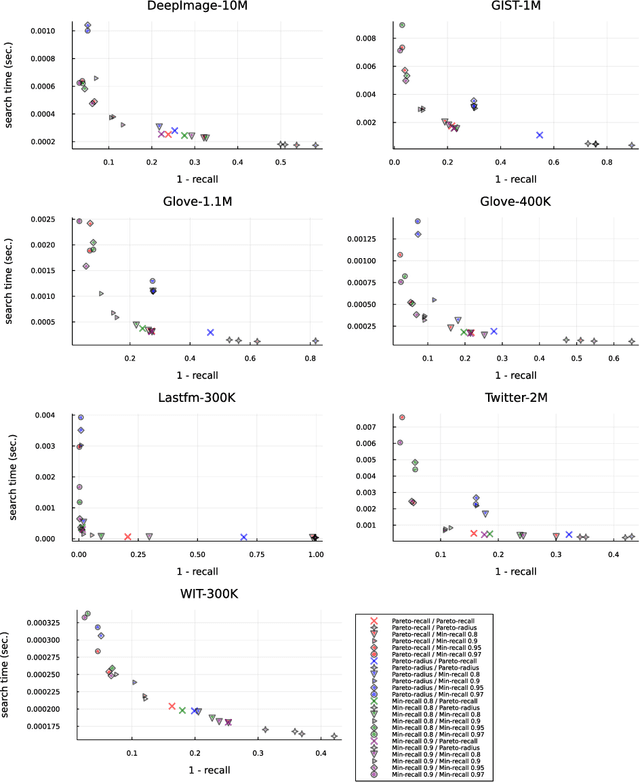
This manuscript introduces an autotuned algorithm for searching nearest neighbors based on neighbor graphs and optimization metaheuristics to produce Pareto-optimal searches for quality and search speed automatically; the same strategy is also used to produce indexes that achieve a minimum quality. Our approach is described and benchmarked with other state-of-the-art similarity search methods, showing convenience and competitiveness.
Hyperparameter-Free Losses for Model-Based Monocular Reconstruction
Aug 16, 2019
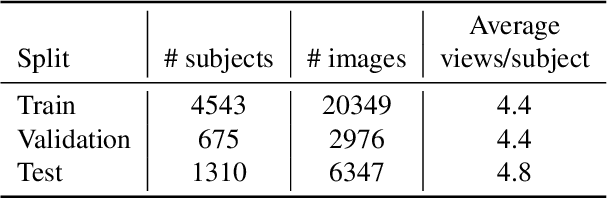

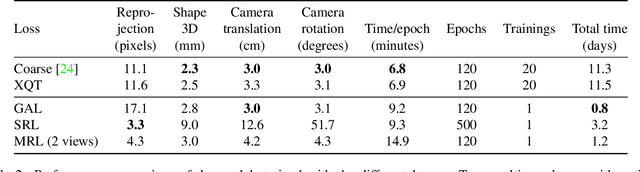
This work proposes novel hyperparameter-free losses for single view 3D reconstruction with morphable models (3DMM). We dispense with the hyperparameters used in other works by exploiting geometry, so that the shape of the object and the camera pose are jointly optimized in a sole term expression. This simplification reduces the optimization time and its complexity. Moreover, we propose a novel implicit regularization technique based on random virtual projections that does not require additional 2D or 3D annotations. Our experiments suggest that minimizing a shape reprojection error together with the proposed implicit regularization is especially suitable for applications that require precise alignment between geometry and image spaces, such as augmented reality. We evaluate our losses on a large scale dataset with 3D ground truth and publish our implementations to facilitate reproducibility and public benchmarking in this field.