 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Captioning: a comparative review of where we are and which could be the route
Apr 13, 2022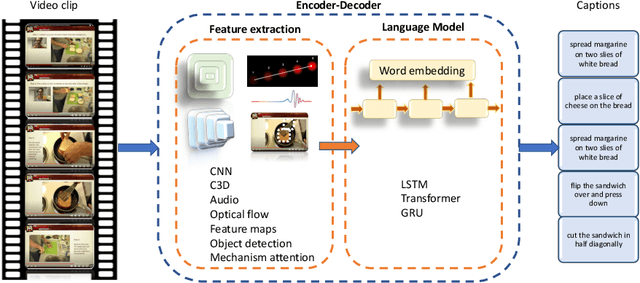
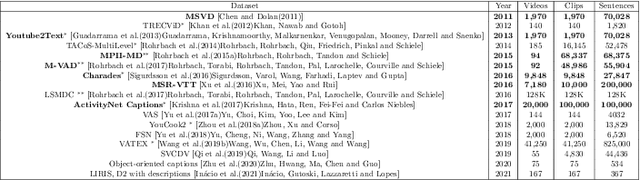
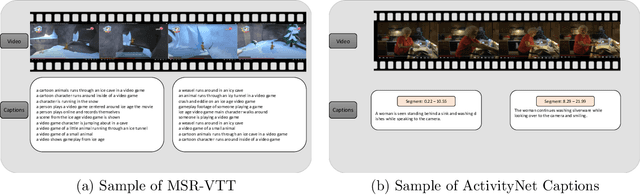

Video captioning is the process of describing the content of a sequence of images capturing its semantic relationships and meanings. Dealing with this task with a single image is arduous, not to mention how difficult it is for a video (or images sequence). The amount and relevance of the applications of video captioning are vast, mainly to deal with a significant amount of video recordings in video surveillance, or assisting people visually impaired, to mention a few. To analyze where the efforts of our community to solve the video captioning task are, as well as what route could be better to follow, this manuscript presents an extensive review of more than 105 papers for the period of 2016 to 2021. As a result, the most-used datasets and metrics are identified. Also, the main approaches used and the best ones. We compute a set of rankings based on several performance metrics to obtain, according to its performance, the best method with the best result on the video captioning task. Finally, some insights are concluded about which could be the next steps or opportunity areas to improve dealing with this complex task.