 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity search on neighbor's graphs with automatic Pareto optimal performance and minimum expected quality setups based on hyperparameter optimization
Jan 19, 2022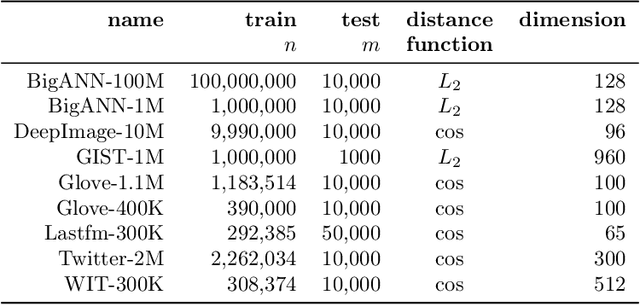
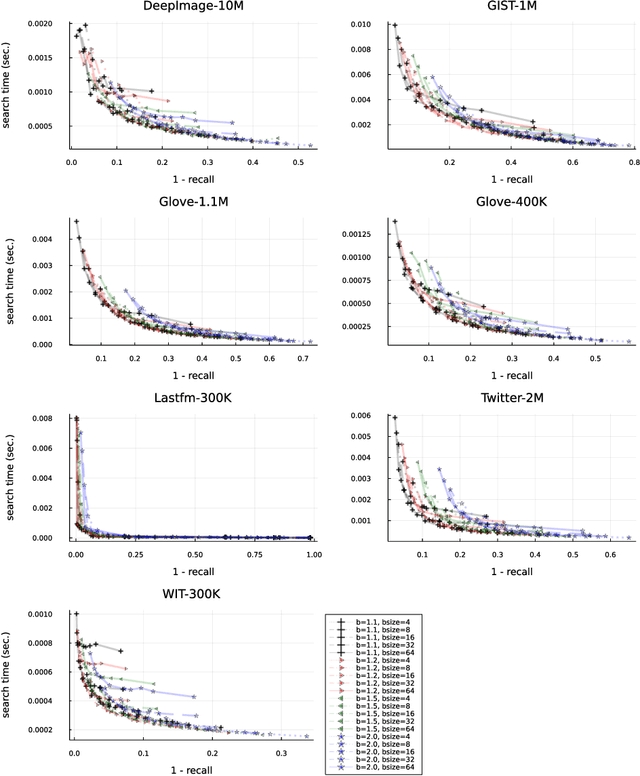

This manuscript introduces an autotuned algorithm for searching nearest neighbors based on neighbor graphs and optimization metaheuristics to produce Pareto-optimal searches for quality and search speed automatically; the same strategy is also used to produce indexes that achieve a minimum quality. Our approach is described and benchmarked with other state-of-the-art similarity search methods, showing convenience and competitiveness.
A large scale lexical and semantic analysis of Spanish language variations in Twitter
Oct 12, 2021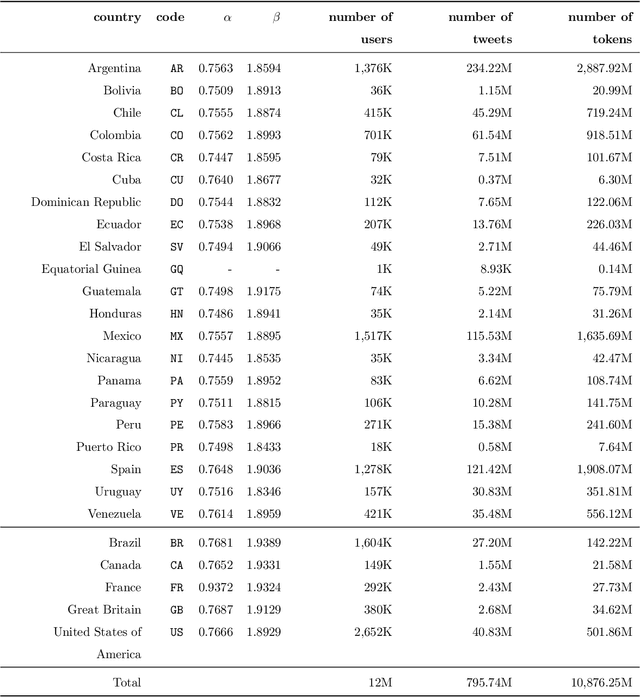
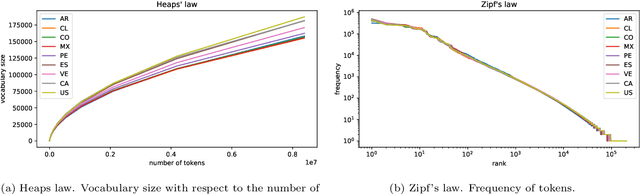
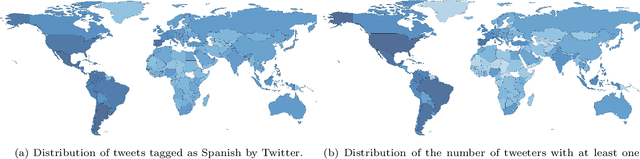
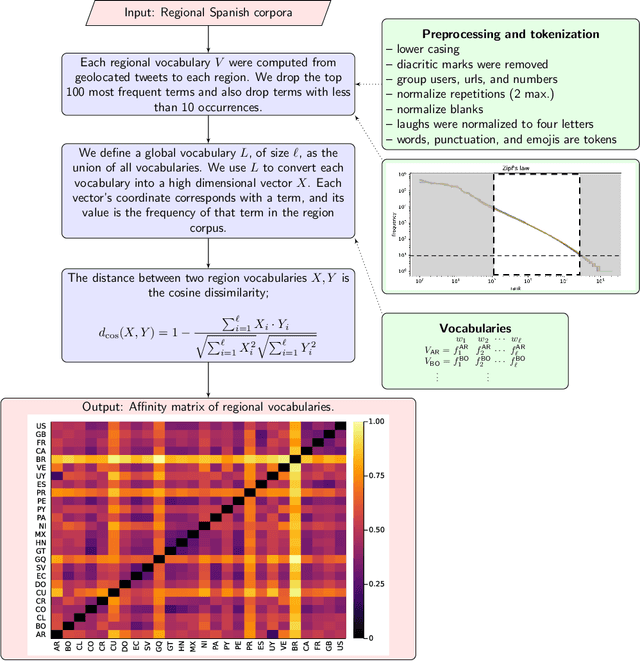
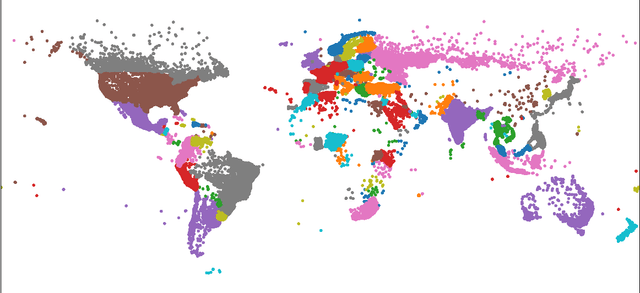
Dialectometry is a discipline devoted to studying the variations of a language around a geographical region. One of their goals is the creation of linguistic atlases capturing the similarities and differences of the language under study around the area in question. For instance, Spanish is one of the most spoken languages across the world, but not necessarily Spanish is written and spoken in the same way in different countries. This manuscript presents a broad analysis describing lexical and semantic relationships among 26 Spanish-speaking countries around the globe. For this study, we analyze four-year of the Twitter geotagged public stream to provide an extensive survey of the Spanish language vocabularies of different countries, its distributions, semantic usage of terms, and emojis. We also offer open regional word-embedding resources for Spanish Twitter to help other researchers and practitioners take advantage of regionalized models.
A Case Study of Spanish Text Transformations for Twitter Sentiment Analysis
Jun 03, 2021
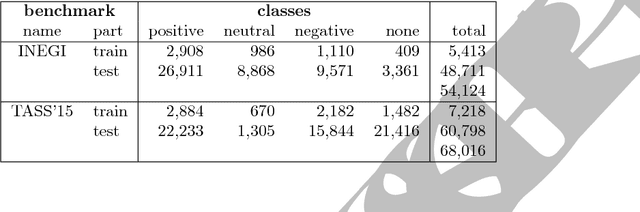
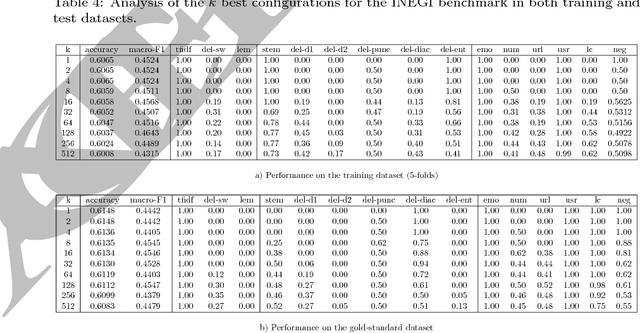
Sentiment analysis is a text mining task that determines the polarity of a given text, i.e., its positiveness or negativeness. Recently, it has received a lot of attention given the interest in opinion mining in micro-blogging platforms. These new forms of textual expressions present new challenges to analyze text given the use of slang, orthographic and grammatical errors, among others. Along with these challenges, a practical sentiment classifier should be able to handle efficiently large workloads. The aim of this research is to identify which text transformations (lemmatization, stemming, entity removal, among others), tokenizers (e.g., words $n$-grams), and tokens weighting schemes impact the most the accuracy of a classifier (Support Vector Machine) trained on two Spanish corpus. The methodology used is to exhaustively analyze all the combinations of the text transformations and their respective parameters to find out which characteristics the best performing classifiers have in common. Furthermore, among the different text transformations studied, we introduce a novel approach based on the combination of word based $n$-grams and character based $q$-grams. The results show that this novel combination of words and characters produces a classifier that outperforms the traditional word based combination by $11.17\%$ and $5.62\%$ on the INEGI and TASS'15 dataset, respectively.
A Python Library for Exploratory Data Analysis and Knowledge Discovery on Twitter Data
Sep 03, 2020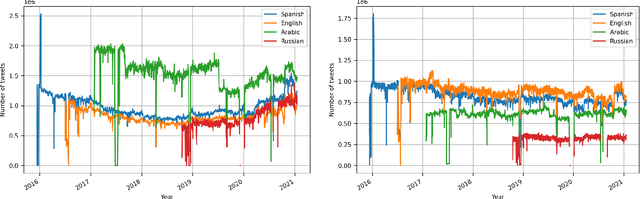
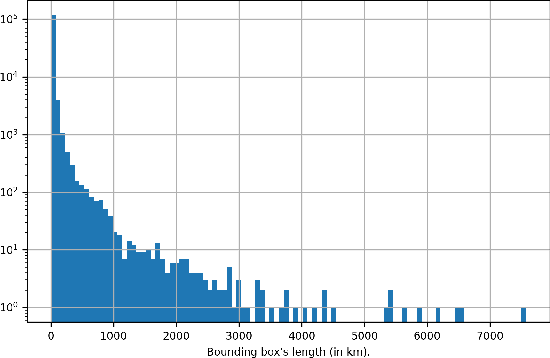
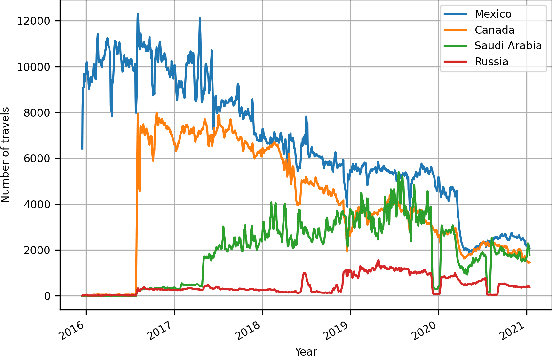
Twitter is perhaps the social media more amenable for research. It requires only a few steps to obtain information, and there are plenty of libraries that can help in this regard. Nonetheless, knowing whether a particular event is expressed on Twitter is a challenging task that requires a considerable collection of tweets. This proposal aims to facilitate, a researcher interested in Twitter data, the process of mining events on Twitter. The events could be related to natural disasters, health issues, people's mobility, among other studies that can be pursued with the library proposed. Different applications are presented in this contribution to illustrate the library's capabilities, starting from an exploratory analysis of the topics discovered in tweets, following it by studying the similarity among dialects of the Spanish language, and complementing it with a mobility report on different countries. In summary, the Python library presented retrieves a plethora of information processed from Twitter (since December 2015) in terms of words, bigrams of words, and their frequencies by day for Arabic, English, Spanish, and Russian languages. Finally, the mobility information considered is related to the number of travels among locations for more than 245 countries or territories.
Feature space transformations and model selection to improve the performance of classifiers
Jul 14, 2019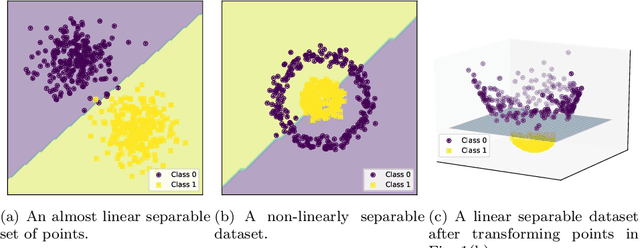

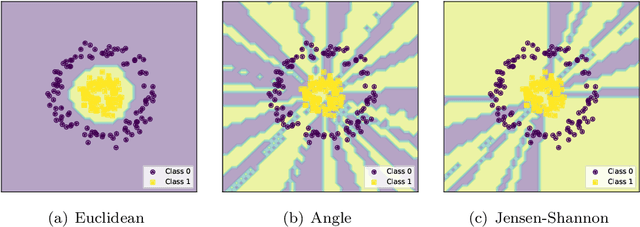
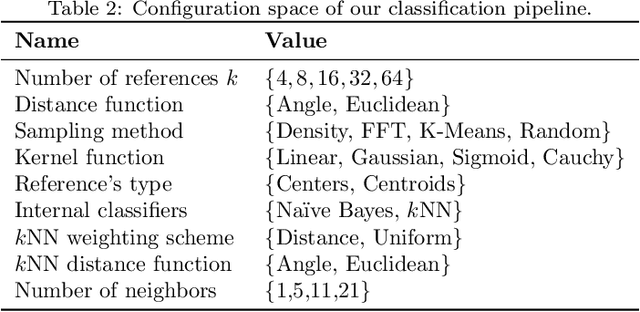
Improving the performance of classifiers is the realm of prototype selection and kernel transformations. Prototype selection has been used to reduce the space complexity of k-Nearest Neighbors classifiers and to improve its accuracy, and kernel transformations enhanced the performance of linear classifiers by converting a non-linear separable problem into a linear one in the transformed space. Our proposal combines, in a model selection scheme, these transformations with classic algorithms such as Na\"ive Bayes and k-Nearest Neighbors to produce a competitive classifier. We analyzed our approach on different classification problems and compared it to state-of-the-art classifiers. The results show that the methodology proposed is competitive, obtaining the lowest rank among the classifiers being compared.
EvoMSA: A Multilingual Evolutionary Approach for Sentiment Analysis
Nov 29, 2018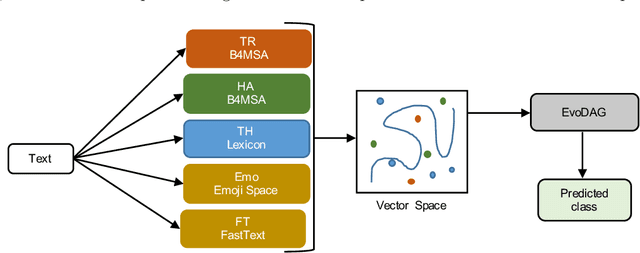
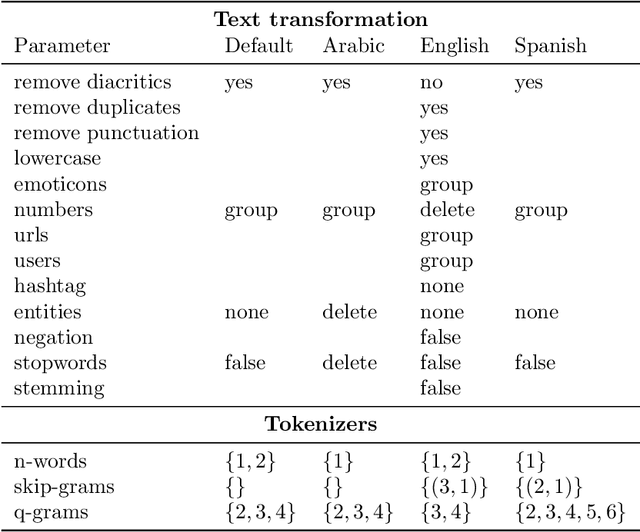

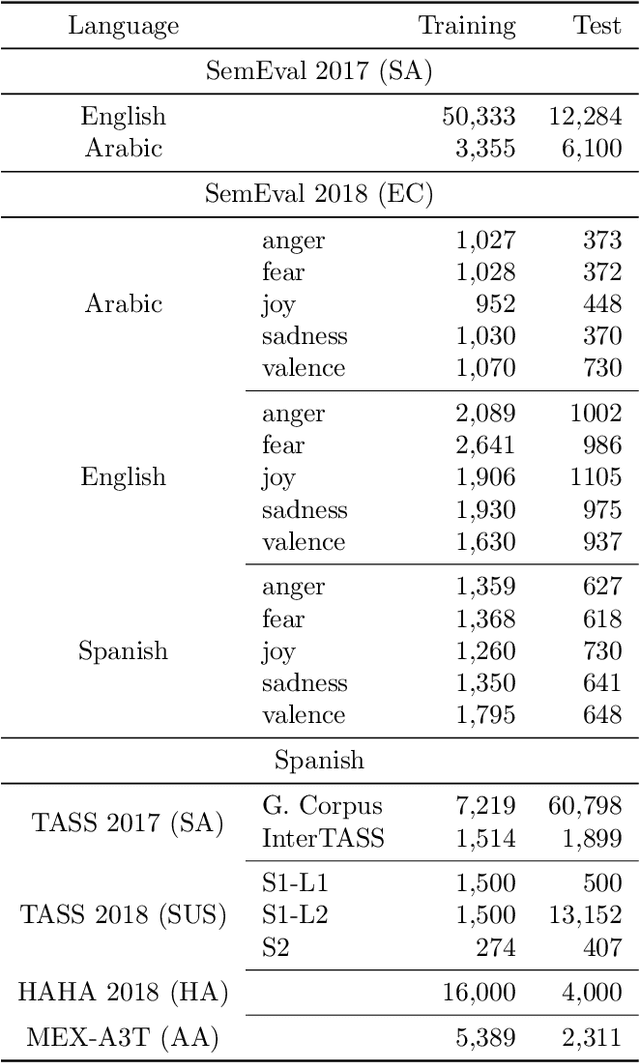
Sentiment analysis (SA) is a task related to understanding people's feelings in written text; the starting point would be to identify the polarity level (positive, neutral or negative) of a given text, moving on to identify emotions or whether a text is humorous or not. This task has been the subject of several research competitions in a number of languages, e.g., English, Spanish, and Arabic, among others. In this contribution, we propose an SA system, namely EvoMSA, that unifies our participating systems in various SA competitions, making it domain independent and multilingual by processing text using only language-independent techniques. EvoMSA is a classifier, based on Genetic Programming, that works by combining the output of different text classifiers and text models to produce the final prediction. We analyze EvoMSA, with its parameters fixed, on different SA competitions to provide a global overview of its performance, and as the results show, EvoMSA is competitive obtaining top rankings in several SA competitions. Furthermore, we performed an analysis of EvoMSA's components to measure their contribution to the performance; the idea is to facilitate a practitioner or newcomer to implement a competitive SA classifier. Finally, it is worth to mention that EvoMSA is available as open source software.
An Automated Text Categorization Framework based on Hyperparameter Optimization
Sep 14, 2017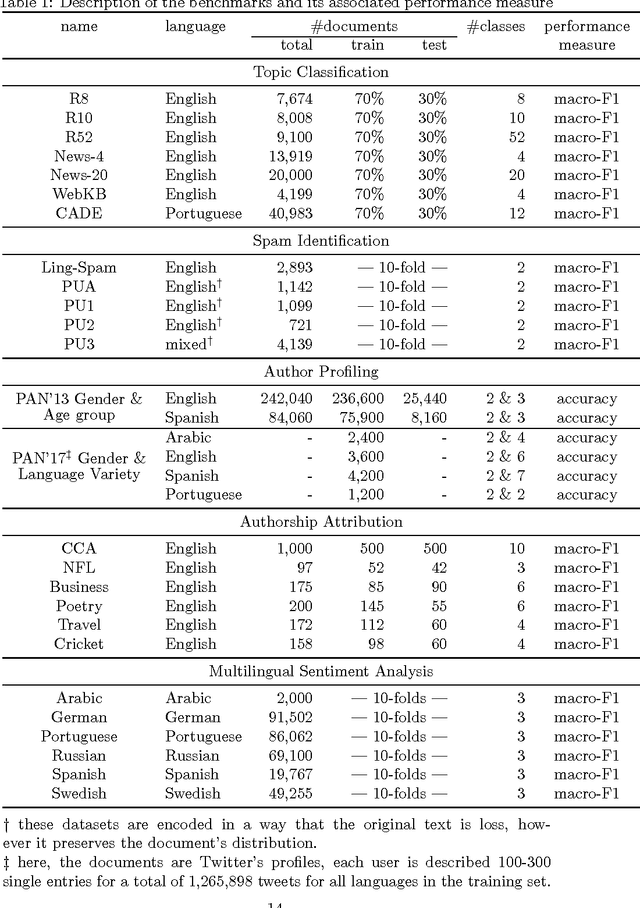
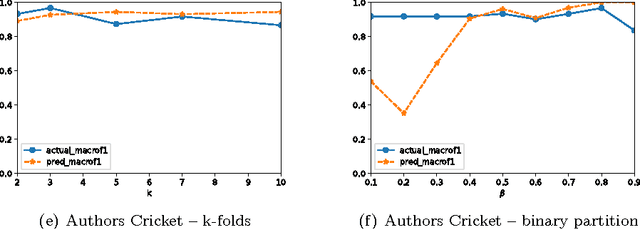
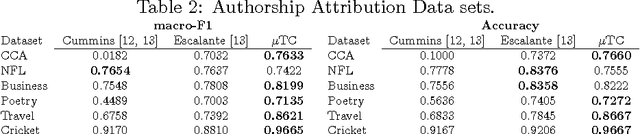
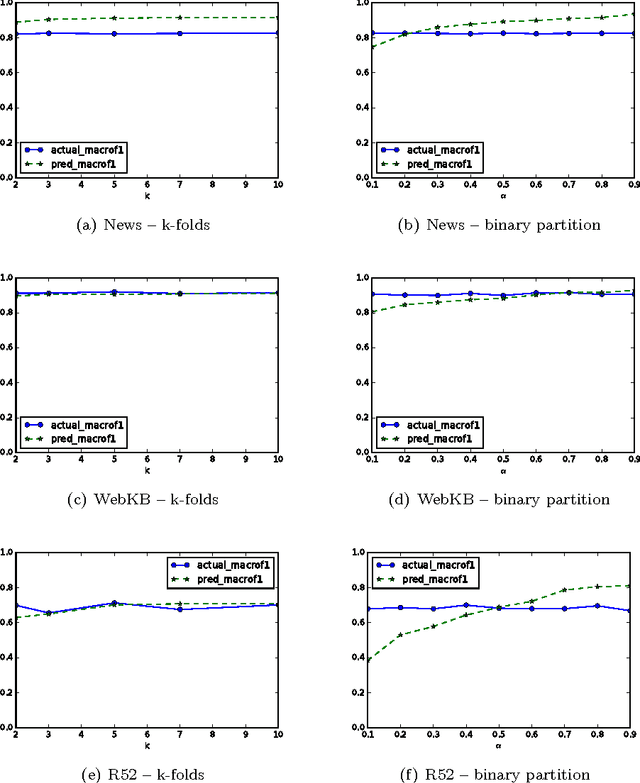
A great variety of text tasks such as topic or spam identification, user profiling, and sentiment analysis can be posed as a supervised learning problem and tackle using a text classifier. A text classifier consists of several subprocesses, some of them are general enough to be applied to any supervised learning problem, whereas others are specifically designed to tackle a particular task, using complex and computational expensive processes such as lemmatization, syntactic analysis, etc. Contrary to traditional approaches, we propose a minimalistic and wide system able to tackle text classification tasks independent of domain and language, namely microTC. It is composed by some easy to implement text transformations, text representations, and a supervised learning algorithm. These pieces produce a competitive classifier even in the domain of informally written text. We provide a detailed description of microTC along with an extensive experimental comparison with relevant state-of-the-art methods. mircoTC was compared on 30 different datasets. Regarding accuracy, microTC obtained the best performance in 20 datasets while achieves competitive results in the remaining 10. The compared datasets include several problems like topic and polarity classification, spam detection, user profiling and authorship attribution. Furthermore, it is important to state that our approach allows the usage of the technology even without knowledge of machine learning and natural language processing.
A Simple Approach to Multilingual Polarity Classification in Twitter
Dec 15, 2016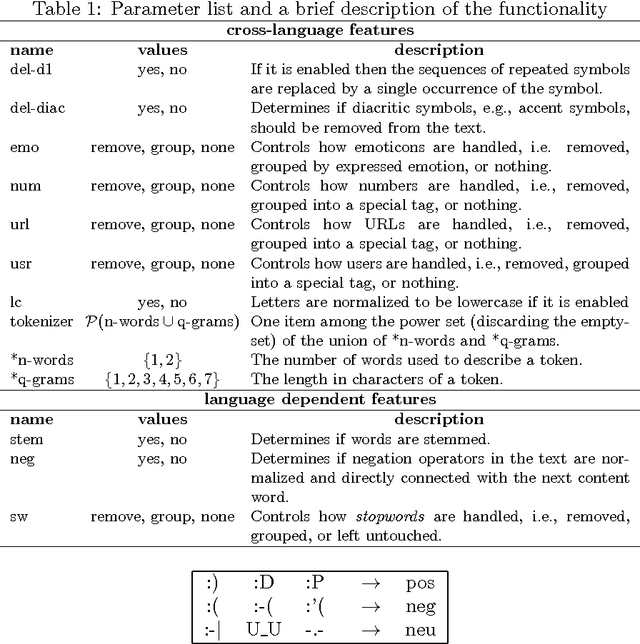
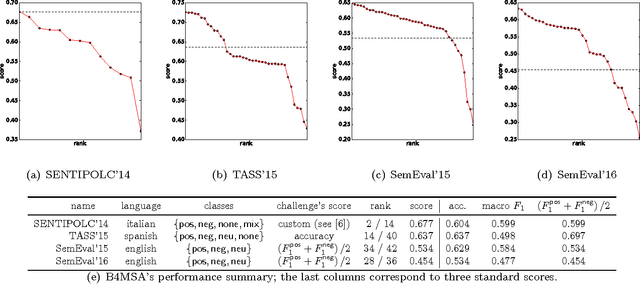
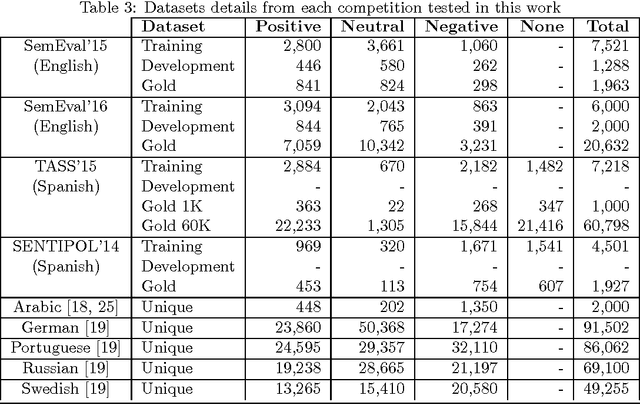

Recently, sentiment analysis has received a lot of attention due to the interest in mining opinions of social media users. Sentiment analysis consists in determining the polarity of a given text, i.e., its degree of positiveness or negativeness. Traditionally, Sentiment Analysis algorithms have been tailored to a specific language given the complexity of having a number of lexical variations and errors introduced by the people generating content. In this contribution, our aim is to provide a simple to implement and easy to use multilingual framework, that can serve as a baseline for sentiment analysis contests, and as starting point to build new sentiment analysis systems. We compare our approach in eight different languages, three of them have important international contests, namely, SemEval (English), TASS (Spanish), and SENTIPOLC (Italian). Within the competitions our approach reaches from medium to high positions in the rankings; whereas in the remaining languages our approach outperforms the reported results.