 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Python Library for Exploratory Data Analysis and Knowledge Discovery on Twitter Data
Paper and Code
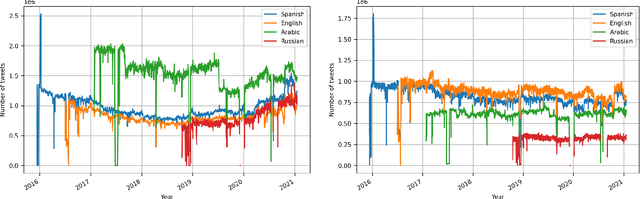
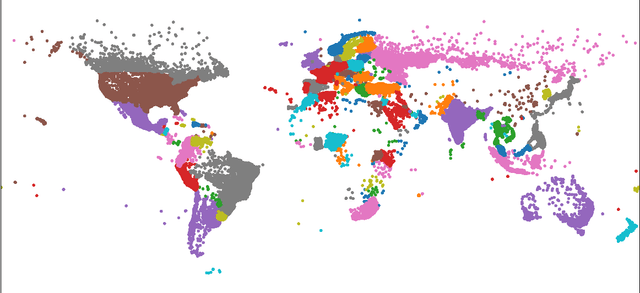
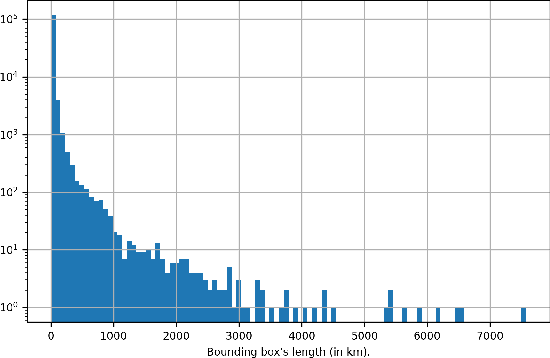
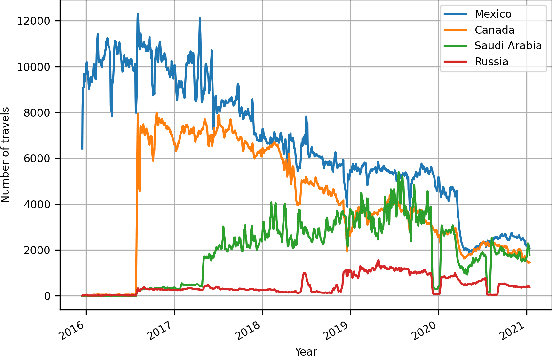
Twitter is perhaps the social media more amenable for research. It requires only a few steps to obtain information, and there are plenty of libraries that can help in this regard. Nonetheless, knowing whether a particular event is expressed on Twitter is a challenging task that requires a considerable collection of tweets. This proposal aims to facilitate, a researcher interested in Twitter data, the process of mining events on Twitter. The events could be related to natural disasters, health issues, people's mobility, among other studies that can be pursued with the library proposed. Different applications are presented in this contribution to illustrate the library's capabilities, starting from an exploratory analysis of the topics discovered in tweets, following it by studying the similarity among dialects of the Spanish language, and complementing it with a mobility report on different countries. In summary, the Python library presented retrieves a plethora of information processed from Twitter (since December 2015) in terms of words, bigrams of words, and their frequencies by day for Arabic, English, Spanish, and Russian languages. Finally, the mobility information considered is related to the number of travels among locations for more than 245 countries or territories.