 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automated Text Categorization Framework based on Hyperparameter Optimization
Paper and Code
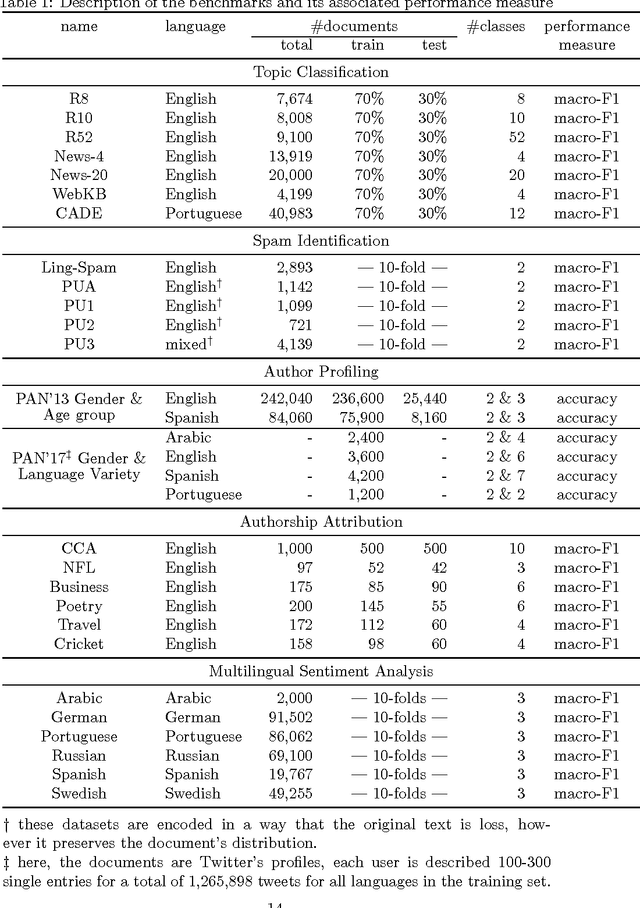
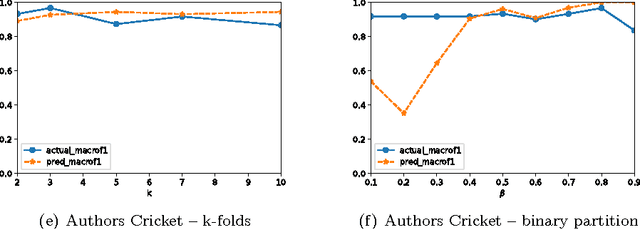
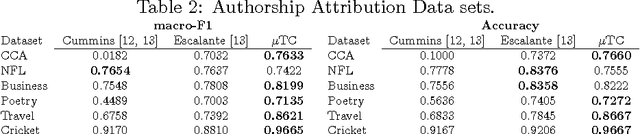
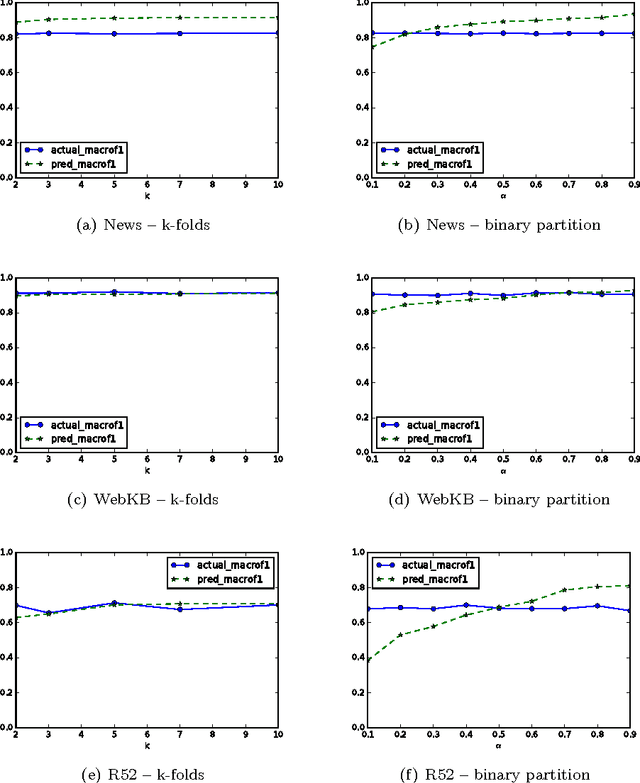
A great variety of text tasks such as topic or spam identification, user profiling, and sentiment analysis can be posed as a supervised learning problem and tackle using a text classifier. A text classifier consists of several subprocesses, some of them are general enough to be applied to any supervised learning problem, whereas others are specifically designed to tackle a particular task, using complex and computational expensive processes such as lemmatization, syntactic analysis, etc. Contrary to traditional approaches, we propose a minimalistic and wide system able to tackle text classification tasks independent of domain and language, namely microTC. It is composed by some easy to implement text transformations, text representations, and a supervised learning algorithm. These pieces produce a competitive classifier even in the domain of informally written text. We provide a detailed description of microTC along with an extensive experimental comparison with relevant state-of-the-art methods. mircoTC was compared on 30 different datasets. Regarding accuracy, microTC obtained the best performance in 20 datasets while achieves competitive results in the remaining 10. The compared datasets include several problems like topic and polarity classification, spam detection, user profiling and authorship attribution. Furthermore, it is important to state that our approach allows the usage of the technology even without knowledge of machine learning and natural language processing.