 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Approach to Multilingual Polarity Classification in Twitter
Paper and Code
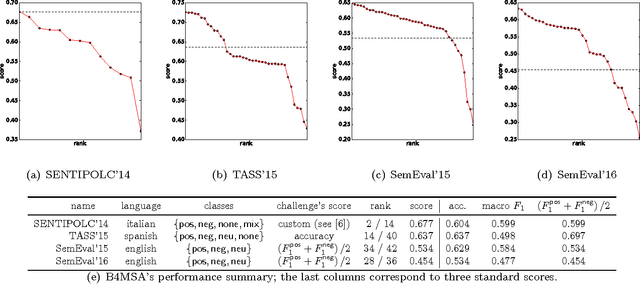
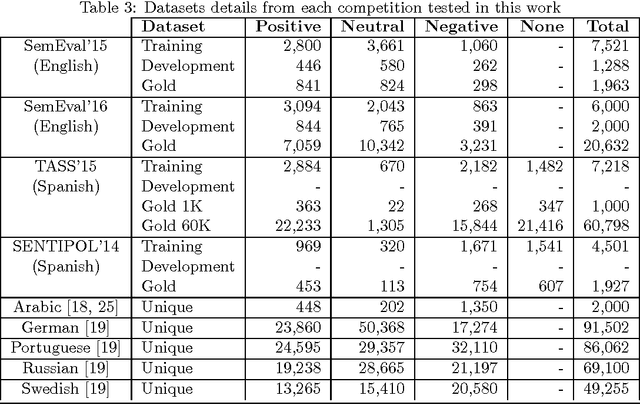

Recently, sentiment analysis has received a lot of attention due to the interest in mining opinions of social media users. Sentiment analysis consists in determining the polarity of a given text, i.e., its degree of positiveness or negativeness. Traditionally, Sentiment Analysis algorithms have been tailored to a specific language given the complexity of having a number of lexical variations and errors introduced by the people generating content. In this contribution, our aim is to provide a simple to implement and easy to use multilingual framework, that can serve as a baseline for sentiment analysis contests, and as starting point to build new sentiment analysis systems. We compare our approach in eight different languages, three of them have important international contests, namely, SemEval (English), TASS (Spanish), and SENTIPOLC (Italian). Within the competitions our approach reaches from medium to high positions in the rankings; whereas in the remaining languages our approach outperforms the reported results.