 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks
Mar 27, 2025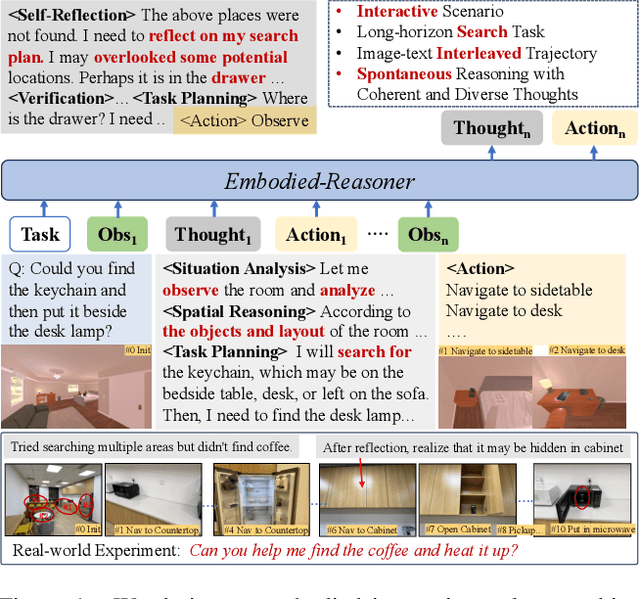

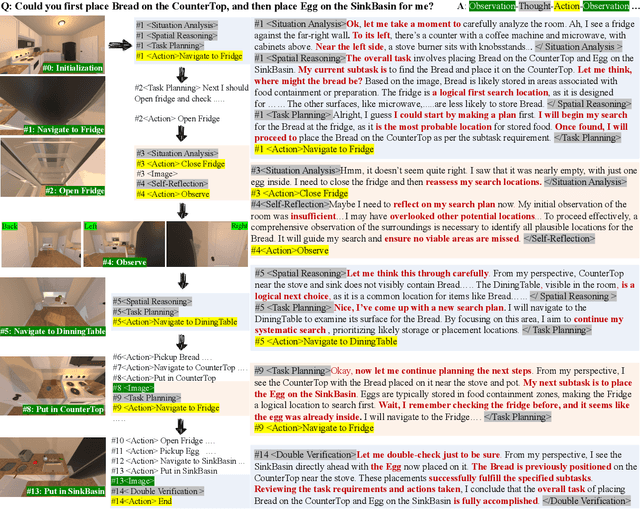
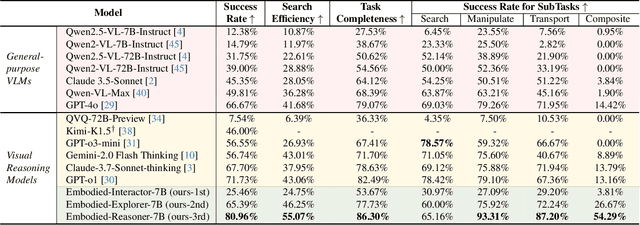
Recent advances in deep thinking models have demonstrated remarkable reasoning capabilities on mathematical and coding tasks. However, their effectiveness in embodied domains which require continuous interaction with environments through image action interleaved trajectories remains largely -unexplored. We present Embodied Reasoner, a model that extends o1 style reasoning to interactive embodied search tasks. Unlike mathematical reasoning that relies primarily on logical deduction, embodied scenarios demand spatial understanding, temporal reasoning, and ongoing self-reflection based on interaction history. To address these challenges, we synthesize 9.3k coherent Observation-Thought-Action trajectories containing 64k interactive images and 90k diverse thinking processes (analysis, spatial reasoning, reflection, planning, and verification). We develop a three-stage training pipeline that progressively enhances the model's capabilities through imitation learning, self-exploration via rejection sampling, and self-correction through reflection tuning. The evaluation shows that our model significantly outperforms those advanced visual reasoning models, e.g., it exceeds OpenAI o1, o3-mini, and Claude-3.7 by +9\%, 24\%, and +13\%. Analysis reveals our model exhibits fewer repeated searches and logical inconsistencies, with particular advantages in complex long-horizon tasks. Real-world environments also show our superiority while exhibiting fewer repeated searches and logical inconsistency cases.
Multimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model
Jul 10, 2024
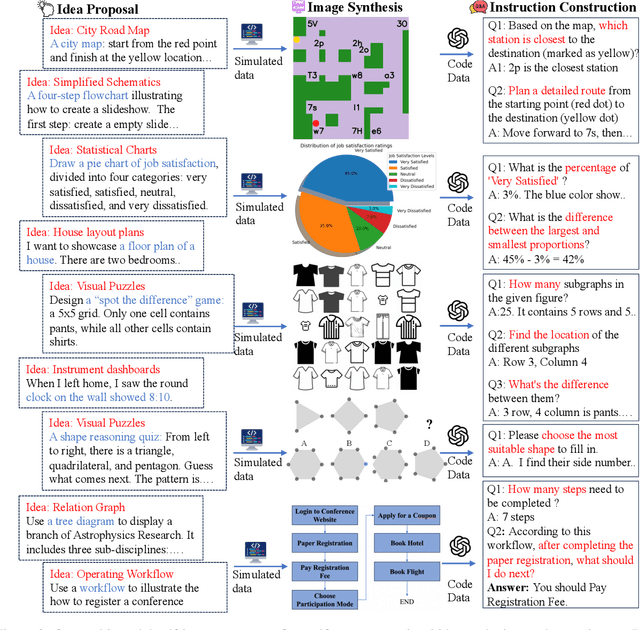
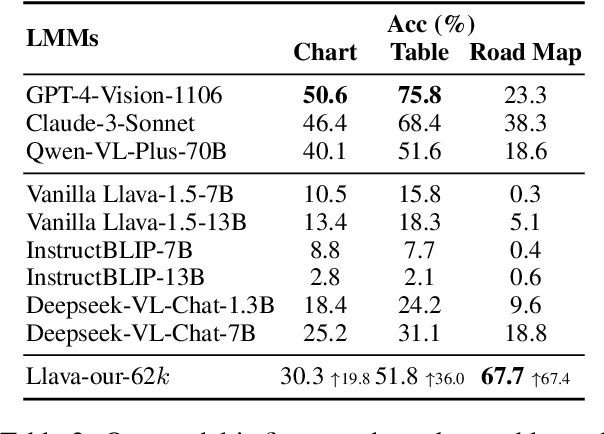
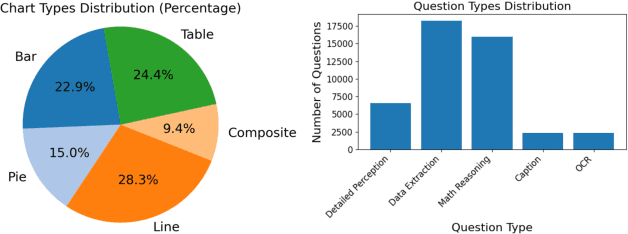
Although most current large multimodal models (LMMs) can already understand photos of natural scenes and portraits, their understanding of abstract images, e.g., charts, maps, or layouts, and visual reasoning capabilities remains quite rudimentary. They often struggle with simple daily tasks, such as reading time from a clock, understanding a flowchart, or planning a route using a road map. In light of this, we design a multi-modal self-instruct, utilizing large language models and their code capabilities to synthesize massive abstract images and visual reasoning instructions across daily scenarios. Our strategy effortlessly creates a multimodal benchmark with 11,193 instructions for eight visual scenarios: charts, tables, simulated maps, dashboards, flowcharts, relation graphs, floor plans, and visual puzzles. \textbf{This benchmark, constructed with simple lines and geometric elements, exposes the shortcomings of most advanced LMMs} like Claude-3.5-Sonnet and GPT-4o in abstract image understanding, spatial relations reasoning, and visual element induction. Besides, to verify the quality of our synthetic data, we fine-tune an LMM using 62,476 synthetic chart, table and road map instructions. The results demonstrate improved chart understanding and map navigation performance, and also demonstrate potential benefits for other visual reasoning tasks. Our code is available at: \url{https://github.com/zwq2018/Multi-modal-Self-instruct}.
Agent-Pro: Learning to Evolve via Policy-Level Reflection and Optimization
Feb 27, 2024



Large Language Models exhibit robust problem-solving capabilities for diverse tasks. However, most LLM-based agents are designed as specific task solvers with sophisticated prompt engineering, rather than agents capable of learning and evolving through interactions. These task solvers necessitate manually crafted prompts to inform task rules and regulate LLM behaviors, inherently incapacitating to address complex dynamic scenarios e.g., large interactive games. In light of this, we propose Agent-Pro: an LLM-based Agent with Policy-level Reflection and Optimization that can learn a wealth of expertise from interactive experiences and progressively elevate its behavioral policy. Specifically, it involves a dynamic belief generation and reflection process for policy evolution. Rather than action-level reflection, Agent-Pro iteratively reflects on past trajectories and beliefs, fine-tuning its irrational beliefs for a better policy. Moreover, a depth-first search is employed for policy optimization, ensuring continual enhancement in policy payoffs. Agent-Pro is evaluated across two games: Blackjack and Texas Hold'em, outperforming vanilla LLM and specialized models. Our results show Agent-Pro can learn and evolve in complex and dynamic scenes, which also benefits numerous LLM-based applications.