 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model
Jul 10, 2024
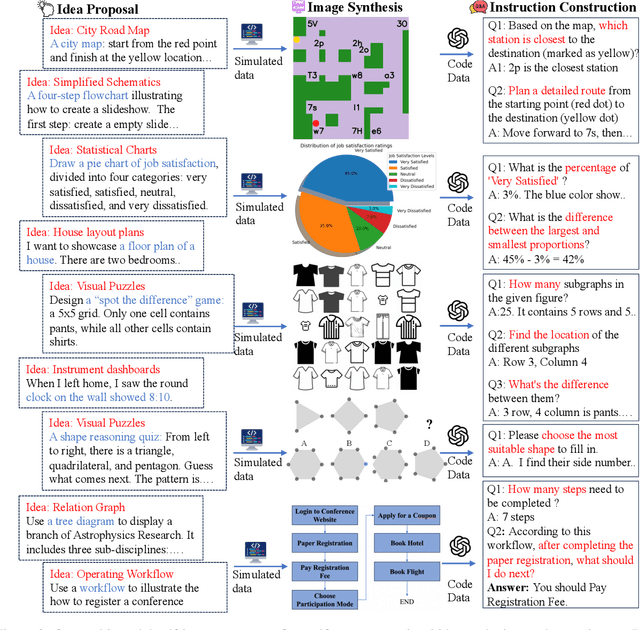
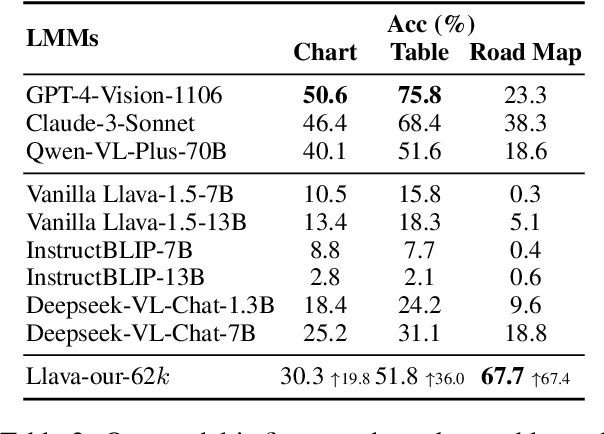
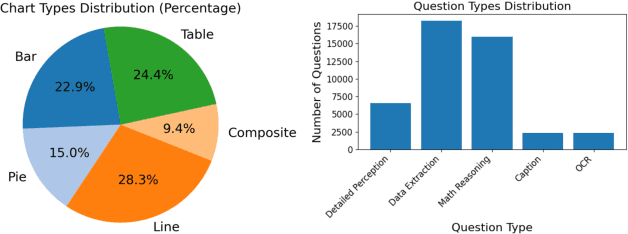
Although most current large multimodal models (LMMs) can already understand photos of natural scenes and portraits, their understanding of abstract images, e.g., charts, maps, or layouts, and visual reasoning capabilities remains quite rudimentary. They often struggle with simple daily tasks, such as reading time from a clock, understanding a flowchart, or planning a route using a road map. In light of this, we design a multi-modal self-instruct, utilizing large language models and their code capabilities to synthesize massive abstract images and visual reasoning instructions across daily scenarios. Our strategy effortlessly creates a multimodal benchmark with 11,193 instructions for eight visual scenarios: charts, tables, simulated maps, dashboards, flowcharts, relation graphs, floor plans, and visual puzzles. \textbf{This benchmark, constructed with simple lines and geometric elements, exposes the shortcomings of most advanced LMMs} like Claude-3.5-Sonnet and GPT-4o in abstract image understanding, spatial relations reasoning, and visual element induction. Besides, to verify the quality of our synthetic data, we fine-tune an LMM using 62,476 synthetic chart, table and road map instructions. The results demonstrate improved chart understanding and map navigation performance, and also demonstrate potential benefits for other visual reasoning tasks. Our code is available at: \url{https://github.com/zwq2018/Multi-modal-Self-instruct}.
An Expression Tree Decoding Strategy for Mathematical Equation Generation
Oct 18, 2023



Generating mathematical equations from natural language requires an accurate understanding of the relations among math expressions. Existing approaches can be broadly categorized into token-level and expression-level generation. The former treats equations as a mathematical language, sequentially generating math tokens. Expression-level methods generate each expression one by one. However, each expression represents a solving step, and there naturally exist parallel or dependent relations between these steps, which are ignored by current sequential methods. Therefore, we integrate tree structure into the expression-level generation and advocate an expression tree decoding strategy. To generate a tree with expression as its node, we employ a layer-wise parallel decoding strategy: we decode multiple independent expressions (leaf nodes) in parallel at each layer and repeat parallel decoding layer by layer to sequentially generate these parent node expressions that depend on others. Besides, a bipartite matching algorithm is adopted to align multiple predictions with annotations for each layer. Experiments show our method outperforms other baselines, especially for these equations with complex structures.
A Closed-Loop Perception, Decision-Making and Reasoning Mechanism for Human-Like Navigation
Jul 25, 2022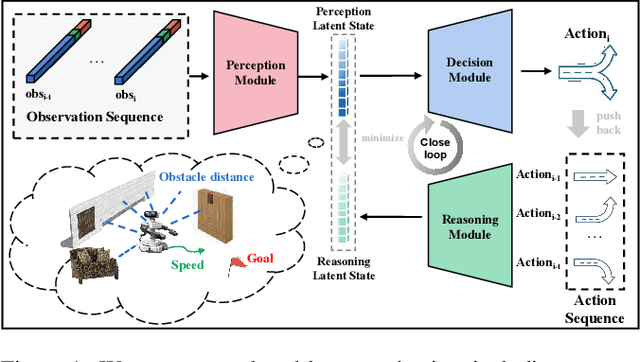
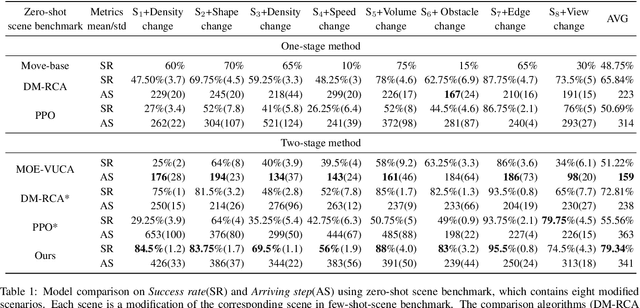
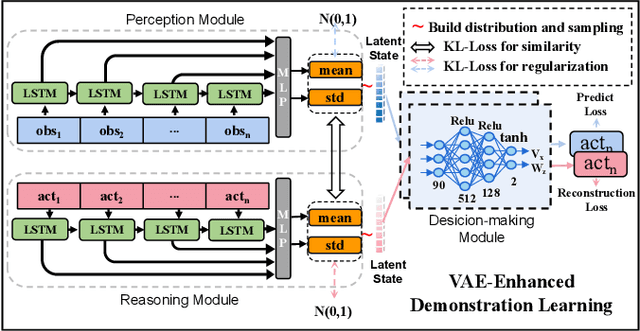

Reliable navigation systems have a wide range of applications in robotics and autonomous driving. Current approaches employ an open-loop process that converts sensor inputs directly into actions. However, these open-loop schemes are challenging to handle complex and dynamic real-world scenarios due to their poor generalization. Imitating human navigation, we add a reasoning process to convert actions back to internal latent states, forming a two-stage closed loop of perception, decision-making, and reasoning. Firstly, VAE-Enhanced Demonstration Learning endows the model with the understanding of basic navigation rules. Then, two dual processes in RL-Enhanced Interaction Learning generate reward feedback for each other and collectively enhance obstacle avoidance capability. The reasoning model can substantially promote generalization and robustness, and facilitate the deployment of the algorithm to real-world robots without elaborate transfers. Experiments show our method is more adaptable to novel scenarios compared with state-of-the-art approaches.