 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCLS++: Pushing the Boundaries of Generative Classification in LLMs Through Comprehensive SFT and RL Studies Across Diverse Datasets
Apr 28, 2025As a fundamental task in machine learning, text classification plays a crucial role in many areas. With the rapid scaling of Large Language Models (LLMs), particularly through reinforcement learning (RL), there is a growing need for more capable discriminators. Consequently, advances in classification are becoming increasingly vital for enhancing the overall capabilities of LLMs. Traditional discriminative methods map text to labels but overlook LLMs' intrinsic generative strengths. Generative classification addresses this by prompting the model to directly output labels. However, existing studies still rely on simple SFT alone, seldom probing the interplay between training and inference prompts, and no work has systematically leveraged RL for generative text classifiers and unified SFT, RL, and inference-time prompting in one framework. We bridge this gap with GenCLS++, a framework that jointly optimizes SFT and RL while systematically exploring five high-level strategy dimensions-in-context learning variants, category definitions, explicit uncertainty labels, semantically irrelevant numeric labels, and perplexity-based decoding-during both training and inference. After an SFT "policy warm-up," we apply RL with a simple rule-based reward, yielding sizable extra gains. Across seven datasets, GenCLS++ achieves an average accuracy improvement of 3.46% relative to the naive SFT baseline; on public datasets, this improvement rises to 4.00%. Notably, unlike reasoning-intensive tasks that benefit from explicit thinking processes, we find that classification tasks perform better without such reasoning steps. These insights into the role of explicit reasoning provide valuable guidance for future LLM applications.
STaR-SQL: Self-Taught Reasoner for Text-to-SQL
Feb 19, 2025



Generating step-by-step "chain-of-thought" rationales has proven effective for improving the performance of large language models on complex reasoning tasks. However, applying such techniques to structured tasks, such as text-to-SQL, remains largely unexplored. In this paper, we introduce Self-Taught Reasoner for text-to-SQL (STaR-SQL), a novel approach that reframes SQL query generation as a reasoning-driven process. Our method prompts the LLM to produce detailed reasoning steps for SQL queries and fine-tunes it on rationales that lead to correct outcomes. Unlike traditional methods, STaR-SQL dedicates additional test-time computation to reasoning, thereby positioning LLMs as spontaneous reasoners rather than mere prompt-based agents. To further scale the inference process, we incorporate an outcome-supervised reward model (ORM) as a verifier, which enhances SQL query accuracy. Experimental results on the challenging Spider benchmark demonstrate that STaR-SQL significantly improves text-to-SQL performance, achieving an execution accuracy of 86.6%. This surpasses a few-shot baseline by 31.6% and a baseline fine-tuned to predict answers directly by 18.0%. Additionally, STaR-SQL outperforms agent-like prompting methods that leverage more powerful yet closed-source models such as GPT-4. These findings underscore the potential of reasoning-augmented training for structured tasks and open the door to extending self-improving reasoning models to text-to-SQL generation and beyond.
Multimodal Self-Instruct: Synthetic Abstract Image and Visual Reasoning Instruction Using Language Model
Jul 10, 2024
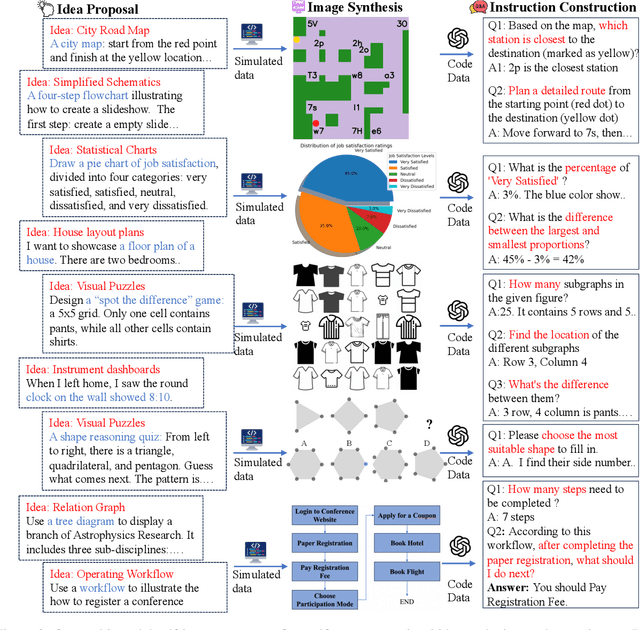
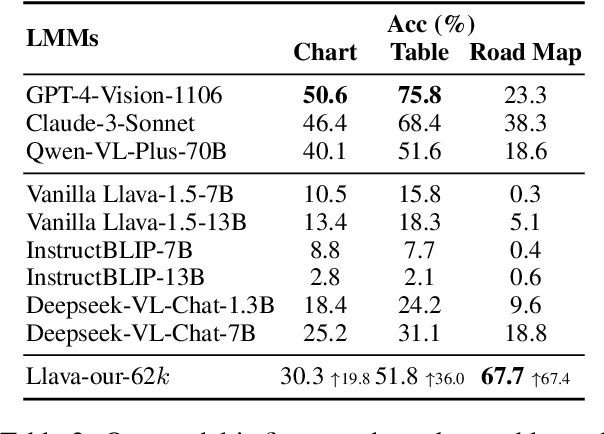
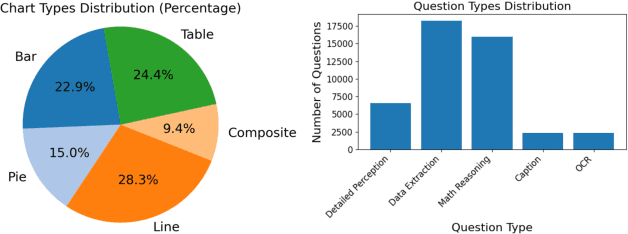
Although most current large multimodal models (LMMs) can already understand photos of natural scenes and portraits, their understanding of abstract images, e.g., charts, maps, or layouts, and visual reasoning capabilities remains quite rudimentary. They often struggle with simple daily tasks, such as reading time from a clock, understanding a flowchart, or planning a route using a road map. In light of this, we design a multi-modal self-instruct, utilizing large language models and their code capabilities to synthesize massive abstract images and visual reasoning instructions across daily scenarios. Our strategy effortlessly creates a multimodal benchmark with 11,193 instructions for eight visual scenarios: charts, tables, simulated maps, dashboards, flowcharts, relation graphs, floor plans, and visual puzzles. \textbf{This benchmark, constructed with simple lines and geometric elements, exposes the shortcomings of most advanced LMMs} like Claude-3.5-Sonnet and GPT-4o in abstract image understanding, spatial relations reasoning, and visual element induction. Besides, to verify the quality of our synthetic data, we fine-tune an LMM using 62,476 synthetic chart, table and road map instructions. The results demonstrate improved chart understanding and map navigation performance, and also demonstrate potential benefits for other visual reasoning tasks. Our code is available at: \url{https://github.com/zwq2018/Multi-modal-Self-instruct}.
Advancing Process Verification for Large Language Models via Tree-Based Preference Learning
Jun 29, 2024

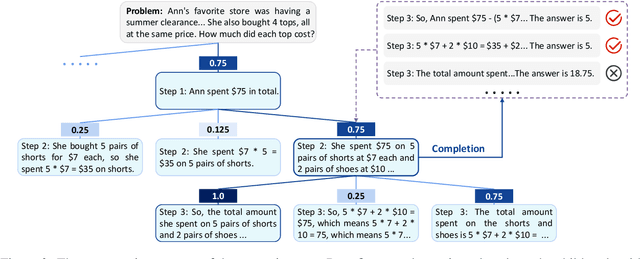

Large Language Models (LLMs) have demonstrated remarkable potential in handling complex reasoning tasks by generating step-by-step rationales.Some methods have proven effective in boosting accuracy by introducing extra verifiers to assess these paths. However, existing verifiers, typically trained on binary-labeled reasoning paths, fail to fully utilize the relative merits of intermediate steps, thereby limiting the effectiveness of the feedback provided. To overcome this limitation, we propose Tree-based Preference Learning Verifier (Tree-PLV), a novel approach that constructs reasoning trees via a best-first search algorithm and collects step-level paired data for preference training. Compared to traditional binary classification, step-level preferences more finely capture the nuances between reasoning steps, allowing for a more precise evaluation of the complete reasoning path. We empirically evaluate Tree-PLV across a range of arithmetic and commonsense reasoning tasks, where it significantly outperforms existing benchmarks. For instance, Tree-PLV achieved substantial performance gains over the Mistral-7B self-consistency baseline on GSM8K (67.55% to 82.79%), MATH (17.00% to 26.80%), CSQA (68.14% to 72.97%), and StrategyQA (82.86% to 83.25%).Additionally, our study explores the appropriate granularity for applying preference learning, revealing that step-level guidance provides feedback that better aligns with the evaluation of the reasoning process.