 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason Faithfully through Step-Level Faithfulness Maximization
Feb 03, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has markedly improved the performance of Large Language Models (LLMs) on tasks requiring multi-step reasoning. However, most RLVR pipelines rely on sparse outcome-based rewards, providing little supervision over intermediate steps and thus encouraging over-confidence and spurious reasoning, which in turn increases hallucinations. To address this, we propose FaithRL, a general reinforcement learning framework that directly optimizes reasoning faithfulness. We formalize a faithfulness-maximization objective and theoretically show that optimizing it mitigates over-confidence. To instantiate this objective, we introduce a geometric reward design and a faithfulness-aware advantage modulation mechanism that assigns step-level credit by penalizing unsupported steps while preserving valid partial derivations. Across diverse backbones and benchmarks, FaithRL consistently reduces hallucination rates while maintaining (and often improving) answer correctness. Further analysis confirms that FaithRL increases step-wise reasoning faithfulness and generalizes robustly. Our code is available at https://github.com/aintdoin/FaithRL.
Driving in Spikes: An Entropy-Guided Object Detector for Spike Cameras
Nov 19, 2025Object detection in autonomous driving suffers from motion blur and saturation under fast motion and extreme lighting. Spike cameras, offer microsecond latency and ultra high dynamic range for object detection by using per pixel asynchronous integrate and fire. However, their sparse, discrete output cannot be processed by standard image-based detectors, posing a critical challenge for end to end spike stream detection. We propose EASD, an end to end spike camera detector with a dual branch design: a Temporal Based Texture plus Feature Fusion branch for global cross slice semantics, and an Entropy Selective Attention branch for object centric details. To close the data gap, we introduce DSEC Spike, the first driving oriented simulated spike detection benchmark.
Evo-1: Lightweight Vision-Language-Action Model with Preserved Semantic Alignment
Nov 06, 2025Vision-Language-Action (VLA) models have emerged as a powerful framework that unifies perception, language, and control, enabling robots to perform diverse tasks through multimodal understanding. However, current VLA models typically contain massive parameters and rely heavily on large-scale robot data pretraining, leading to high computational costs during training, as well as limited deployability for real-time inference. Moreover, most training paradigms often degrade the perceptual representations of the vision-language backbone, resulting in overfitting and poor generalization to downstream tasks. In this work, we present Evo-1, a lightweight VLA model that reduces computation and improves deployment efficiency, while maintaining strong performance without pretraining on robot data. Evo-1 builds on a native multimodal Vision-Language model (VLM), incorporating a novel cross-modulated diffusion transformer along with an optimized integration module, together forming an effective architecture. We further introduce a two-stage training paradigm that progressively aligns action with perception, preserving the representations of the VLM. Notably, with only 0.77 billion parameters, Evo-1 achieves state-of-the-art results on the Meta-World and RoboTwin suite, surpassing the previous best models by 12.4% and 6.9%, respectively, and also attains a competitive result of 94.8% on LIBERO. In real-world evaluations, Evo-1 attains a 78% success rate with high inference frequency and low memory overhead, outperforming all baseline methods. We release code, data, and model weights to facilitate future research on lightweight and efficient VLA models.
MIND: A Multi-agent Framework for Zero-shot Harmful Meme Detection
Jul 09, 2025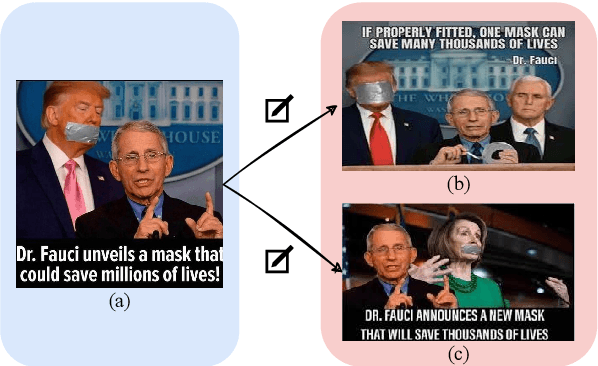
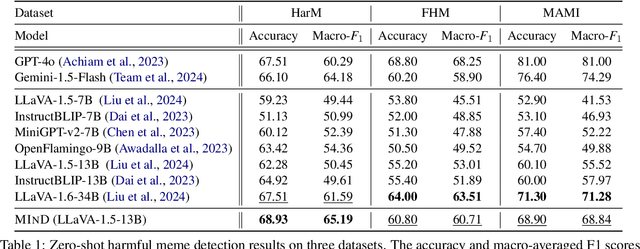
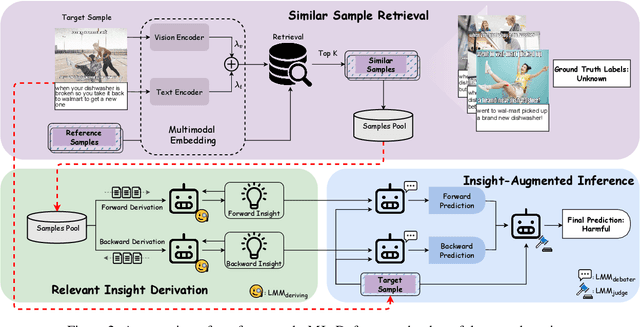
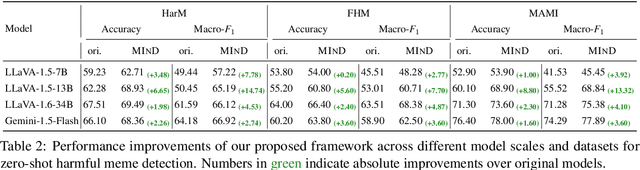
The rapid expansion of memes on social media has highlighted the urgent need for effective approaches to detect harmful content. However, traditional data-driven approaches struggle to detect new memes due to their evolving nature and the lack of up-to-date annotated data. To address this issue, we propose MIND, a multi-agent framework for zero-shot harmful meme detection that does not rely on annotated data. MIND implements three key strategies: 1) We retrieve similar memes from an unannotated reference set to provide contextual information. 2) We propose a bi-directional insight derivation mechanism to extract a comprehensive understanding of similar memes. 3) We then employ a multi-agent debate mechanism to ensure robust decision-making through reasoned arbitration. Extensive experiments on three meme datasets demonstrate that our proposed framework not only outperforms existing zero-shot approaches but also shows strong generalization across different model architectures and parameter scales, providing a scalable solution for harmful meme detection. The code is available at https://github.com/destroy-lonely/MIND.
Can Multimodal Large Language Models Understand Spatial Relations?
May 25, 2025Spatial relation reasoning is a crucial task for multimodal large language models (MLLMs) to understand the objective world. However, current benchmarks have issues like relying on bounding boxes, ignoring perspective substitutions, or allowing questions to be answered using only the model's prior knowledge without image understanding. To address these issues, we introduce SpatialMQA, a human-annotated spatial relation reasoning benchmark based on COCO2017, which enables MLLMs to focus more on understanding images in the objective world. To ensure data quality, we design a well-tailored annotation procedure, resulting in SpatialMQA consisting of 5,392 samples. Based on this benchmark, a series of closed- and open-source MLLMs are implemented and the results indicate that the current state-of-the-art MLLM achieves only 48.14% accuracy, far below the human-level accuracy of 98.40%. Extensive experimental analyses are also conducted, suggesting the future research directions. The benchmark and codes are available at https://github.com/ziyan-xiaoyu/SpatialMQA.git.
GenCLS++: Pushing the Boundaries of Generative Classification in LLMs Through Comprehensive SFT and RL Studies Across Diverse Datasets
Apr 28, 2025As a fundamental task in machine learning, text classification plays a crucial role in many areas. With the rapid scaling of Large Language Models (LLMs), particularly through reinforcement learning (RL), there is a growing need for more capable discriminators. Consequently, advances in classification are becoming increasingly vital for enhancing the overall capabilities of LLMs. Traditional discriminative methods map text to labels but overlook LLMs' intrinsic generative strengths. Generative classification addresses this by prompting the model to directly output labels. However, existing studies still rely on simple SFT alone, seldom probing the interplay between training and inference prompts, and no work has systematically leveraged RL for generative text classifiers and unified SFT, RL, and inference-time prompting in one framework. We bridge this gap with GenCLS++, a framework that jointly optimizes SFT and RL while systematically exploring five high-level strategy dimensions-in-context learning variants, category definitions, explicit uncertainty labels, semantically irrelevant numeric labels, and perplexity-based decoding-during both training and inference. After an SFT "policy warm-up," we apply RL with a simple rule-based reward, yielding sizable extra gains. Across seven datasets, GenCLS++ achieves an average accuracy improvement of 3.46% relative to the naive SFT baseline; on public datasets, this improvement rises to 4.00%. Notably, unlike reasoning-intensive tasks that benefit from explicit thinking processes, we find that classification tasks perform better without such reasoning steps. These insights into the role of explicit reasoning provide valuable guidance for future LLM applications.
VL-UR: Vision-Language-guided Universal Restoration of Images Degraded by Adverse Weather Conditions
Apr 11, 2025



Image restoration is critical for improving the quality of degraded images, which is vital for applications like autonomous driving, security surveillance, and digital content enhancement. However, existing methods are often tailored to specific degradation scenarios, limiting their adaptability to the diverse and complex challenges in real-world environments. Moreover, real-world degradations are typically non-uniform, highlighting the need for adaptive and intelligent solutions. To address these issues, we propose a novel vision-language-guided universal restoration (VL-UR) framework. VL-UR leverages a zero-shot contrastive language-image pre-training (CLIP) model to enhance image restoration by integrating visual and semantic information. A scene classifier is introduced to adapt CLIP, generating high-quality language embeddings aligned with degraded images while predicting degraded types for complex scenarios. Extensive experiments across eleven diverse degradation settings demonstrate VL-UR's state-of-the-art performance, robustness, and adaptability. This positions VL-UR as a transformative solution for modern image restoration challenges in dynamic, real-world environments.
Redefining Machine Translation on Social Network Services with Large Language Models
Apr 10, 2025The globalization of social interactions has heightened the need for machine translation (MT) on Social Network Services (SNS), yet traditional models struggle with culturally nuanced content like memes, slang, and pop culture references. While large language models (LLMs) have advanced general-purpose translation, their performance on SNS-specific content remains limited due to insufficient specialized training data and evaluation benchmarks. This paper introduces RedTrans, a 72B LLM tailored for SNS translation, trained on a novel dataset developed through three innovations: (1) Supervised Finetuning with Dual-LLM Back-Translation Sampling, an unsupervised sampling method using LLM-based back-translation to select diverse data for large-scale finetuning; (2) Rewritten Preference Optimization (RePO), an algorithm that identifies and corrects erroneous preference pairs through expert annotation, building reliable preference corpora; and (3) RedTrans-Bench, the first benchmark for SNS translation, evaluating phenomena like humor localization, emoji semantics, and meme adaptation. Experiments show RedTrans outperforms state-of-the-art LLMs. Besides, RedTrans has already been deployed in a real-world production environment, demonstrating that domain-specific adaptation, effectively bridges the gap between generic and culturally grounded translation systems.
Towards Low-Resource Harmful Meme Detection with LMM Agents
Nov 08, 2024
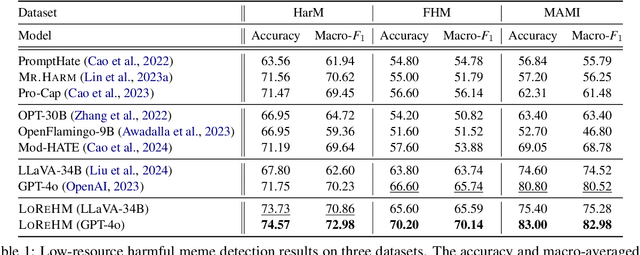


The proliferation of Internet memes in the age of social media necessitates effective identification of harmful ones. Due to the dynamic nature of memes, existing data-driven models may struggle in low-resource scenarios where only a few labeled examples are available. In this paper, we propose an agency-driven framework for low-resource harmful meme detection, employing both outward and inward analysis with few-shot annotated samples. Inspired by the powerful capacity of Large Multimodal Models (LMMs) on multimodal reasoning, we first retrieve relative memes with annotations to leverage label information as auxiliary signals for the LMM agent. Then, we elicit knowledge-revising behavior within the LMM agent to derive well-generalized insights into meme harmfulness. By combining these strategies, our approach enables dialectical reasoning over intricate and implicit harm-indicative patterns. Extensive experiments conducted on three meme datasets demonstrate that our proposed approach achieves superior performance than state-of-the-art methods on the low-resource harmful meme detection task.