 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Low-Resource Harmful Meme Detection with LMM Agents
Paper and Code

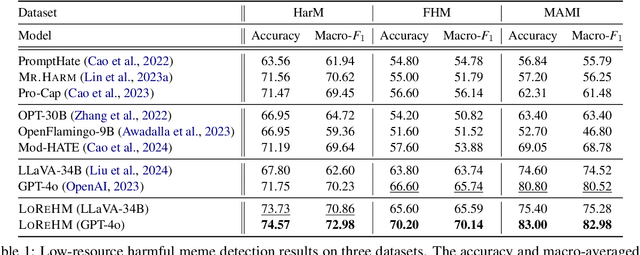


The proliferation of Internet memes in the age of social media necessitates effective identification of harmful ones. Due to the dynamic nature of memes, existing data-driven models may struggle in low-resource scenarios where only a few labeled examples are available. In this paper, we propose an agency-driven framework for low-resource harmful meme detection, employing both outward and inward analysis with few-shot annotated samples. Inspired by the powerful capacity of Large Multimodal Models (LMMs) on multimodal reasoning, we first retrieve relative memes with annotations to leverage label information as auxiliary signals for the LMM agent. Then, we elicit knowledge-revising behavior within the LMM agent to derive well-generalized insights into meme harmfulness. By combining these strategies, our approach enables dialectical reasoning over intricate and implicit harm-indicative patterns. Extensive experiments conducted on three meme datasets demonstrate that our proposed approach achieves superior performance than state-of-the-art methods on the low-resource harmful meme detection task.