 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Temporal Decoupled Adapter for Micro-gesture Online Recognition
Jun 05, 2026Micro-gesture online recognition aims to temporally localize and classify subtle gestures in untrimmed videos. Owing to their extremely short duration, low motion amplitude, and ambiguous visual cues, capturing discriminative spatiotemporal representations remains highly challenging. Existing parameter-efficient adapters typically employ a single branch to model spatial and temporal cues jointly, which may fail to capture the fine-grained patterns of micro-gestures. To address this limitation, we propose a Spatial-Temporal Decoupled Adapter that decomposes video adaptation into independent temporal and spatial branches via lightweight depthwise convolutions. In addition, to address the long-tail distribution problem in the benchmark dataset, we introduce Adaptive Soft Balanced Augmentation, which dynamically allocates augmentation intensity based on class rarity and learning difficulty, without manual thresholds. Our method achieves an F1 score of 0.43808, ranking 1st in Track 2 of the 4th EI-MiGA-IJCAI Challenge.
InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement Learning
Feb 09, 2026Large reasoning models achieve strong performance by scaling inference-time chain-of-thought, but this paradigm suffers from quadratic cost, context length limits, and degraded reasoning due to lost-in-the-middle effects. Iterative reasoning mitigates these issues by periodically summarizing intermediate thoughts, yet existing methods rely on supervised learning or fixed heuristics and fail to optimize when to summarize, what to preserve, and how to resume reasoning. We propose InftyThink+, an end-to-end reinforcement learning framework that optimizes the entire iterative reasoning trajectory, building on model-controlled iteration boundaries and explicit summarization. InftyThink+ adopts a two-stage training scheme with supervised cold-start followed by trajectory-level reinforcement learning, enabling the model to learn strategic summarization and continuation decisions. Experiments on DeepSeek-R1-Distill-Qwen-1.5B show that InftyThink+ improves accuracy by 21% on AIME24 and outperforms conventional long chain-of-thought reinforcement learning by a clear margin, while also generalizing better to out-of-distribution benchmarks. Moreover, InftyThink+ significantly reduces inference latency and accelerates reinforcement learning training, demonstrating improved reasoning efficiency alongside stronger performance.
Uni-MuMER: Unified Multi-Task Fine-Tuning of Vision-Language Model for Handwritten Mathematical Expression Recognition
May 29, 2025Handwritten Mathematical Expression Recognition (HMER) remains a persistent challenge in Optical Character Recognition (OCR) due to the inherent freedom of symbol layout and variability in handwriting styles. Prior methods have faced performance bottlenecks, proposing isolated architectural modifications that are difficult to integrate coherently into a unified framework. Meanwhile, recent advances in pretrained vision-language models (VLMs) have demonstrated strong cross-task generalization, offering a promising foundation for developing unified solutions. In this paper, we introduce Uni-MuMER, which fully fine-tunes a VLM for the HMER task without modifying its architecture, effectively injecting domain-specific knowledge into a generalist framework. Our method integrates three data-driven tasks: Tree-Aware Chain-of-Thought (Tree-CoT) for structured spatial reasoning, Error-Driven Learning (EDL) for reducing confusion among visually similar characters, and Symbol Counting (SC) for improving recognition consistency in long expressions. Experiments on the CROHME and HME100K datasets show that Uni-MuMER achieves new state-of-the-art performance, surpassing the best lightweight specialized model SSAN by 16.31% and the top-performing VLM Gemini2.5-flash by 24.42% in the zero-shot setting. Our datasets, models, and code are open-sourced at: https://github.com/BFlameSwift/Uni-MuMER
Do Large Language Models Excel in Complex Logical Reasoning with Formal Language?
May 22, 2025Large Language Models (LLMs) have been shown to achieve breakthrough performance on complex logical reasoning tasks. Nevertheless, most existing research focuses on employing formal language to guide LLMs to derive reliable reasoning paths, while systematic evaluations of these capabilities are still limited. In this paper, we aim to conduct a comprehensive evaluation of LLMs across various logical reasoning problems utilizing formal languages. From the perspective of three dimensions, i.e., spectrum of LLMs, taxonomy of tasks, and format of trajectories, our key findings are: 1) Thinking models significantly outperform Instruct models, especially when formal language is employed; 2) All LLMs exhibit limitations in inductive reasoning capability, irrespective of whether they use a formal language; 3) Data with PoT format achieves the best generalization performance across other languages. Additionally, we also curate the formal-relative training data to further enhance the small language models, and the experimental results indicate that a simple rejected fine-tuning method can better enable LLMs to generalize across formal languages and achieve the best overall performance. Our codes and reports are available at https://github.com/jiangjin1999/FormalEval.
VerifyBench: Benchmarking Reference-based Reward Systems for Large Language Models
May 21, 2025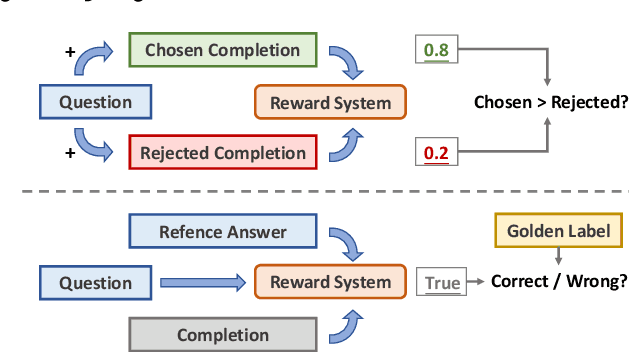
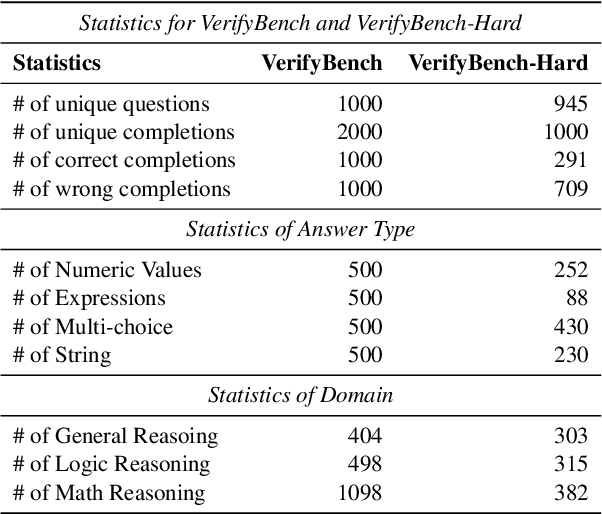
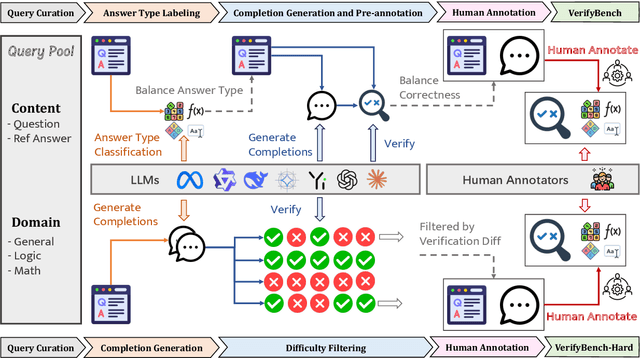
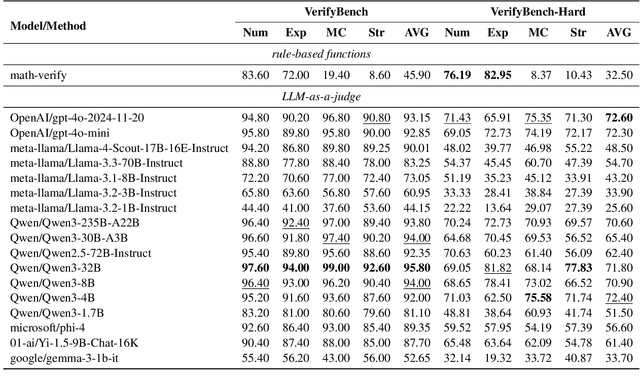
Large reasoning models such as OpenAI o1 and DeepSeek-R1 have achieved remarkable performance in the domain of reasoning. A key component of their training is the incorporation of verifiable rewards within reinforcement learning (RL). However, existing reward benchmarks do not evaluate reference-based reward systems, leaving researchers with limited understanding of the accuracy of verifiers used in RL. In this paper, we introduce two benchmarks, VerifyBench and VerifyBench-Hard, designed to assess the performance of reference-based reward systems. These benchmarks are constructed through meticulous data collection and curation, followed by careful human annotation to ensure high quality. Current models still show considerable room for improvement on both VerifyBench and VerifyBench-Hard, especially smaller-scale models. Furthermore, we conduct a thorough and comprehensive analysis of evaluation results, offering insights for understanding and developing reference-based reward systems. Our proposed benchmarks serve as effective tools for guiding the development of verifier accuracy and the reasoning capabilities of models trained via RL in reasoning tasks.
Prejudge-Before-Think: Enhancing Large Language Models at Test-Time by Process Prejudge Reasoning
Apr 18, 2025
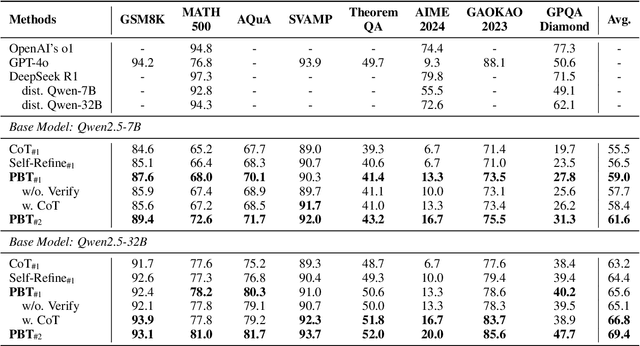

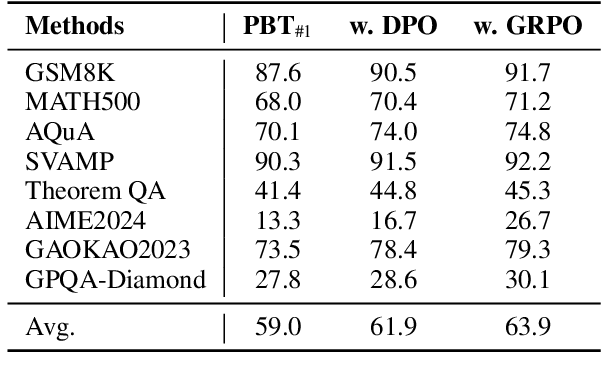
In this paper, we introduce a new \emph{process prejudge} strategy in LLM reasoning to demonstrate that bootstrapping with process prejudge allows the LLM to adaptively anticipate the errors encountered when advancing the subsequent reasoning steps, similar to people sometimes pausing to think about what mistakes may occur and how to avoid them, rather than relying solely on trial and error. Specifically, we define a prejudge node in the rationale, which represents a reasoning step, with at least one step that follows the prejudge node that has no paths toward the correct answer. To synthesize the prejudge reasoning process, we present an automated reasoning framework with a dynamic tree-searching strategy. This framework requires only one LLM to perform answer judging, response critiquing, prejudge generation, and thought completion. Furthermore, we develop a two-phase training mechanism with supervised fine-tuning (SFT) and reinforcement learning (RL) to further enhance the reasoning capabilities of LLMs. Experimental results from competition-level complex reasoning demonstrate that our method can teach the model to prejudge before thinking and significantly enhance the reasoning ability of LLMs. Code and data is released at https://github.com/wjn1996/Prejudge-Before-Think.
InftyThink: Breaking the Length Limits of Long-Context Reasoning in Large Language Models
Mar 09, 2025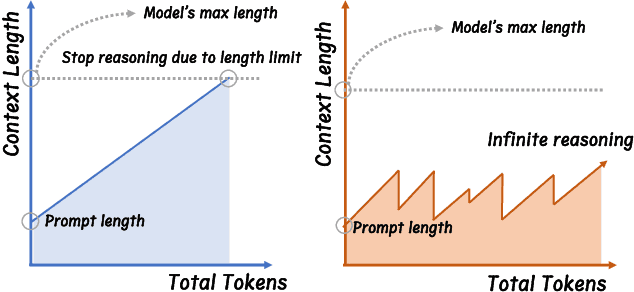



Advanced reasoning in large language models has achieved remarkable performance on challenging tasks, but the prevailing long-context reasoning paradigm faces critical limitations: quadratic computational scaling with sequence length, reasoning constrained by maximum context boundaries, and performance degradation beyond pre-training context windows. Existing approaches primarily compress reasoning chains without addressing the fundamental scaling problem. To overcome these challenges, we introduce InftyThink, a paradigm that transforms monolithic reasoning into an iterative process with intermediate summarization. By interleaving short reasoning segments with concise progress summaries, our approach enables unbounded reasoning depth while maintaining bounded computational costs. This creates a characteristic sawtooth memory pattern that significantly reduces computational complexity compared to traditional approaches. Furthermore, we develop a methodology for reconstructing long-context reasoning datasets into our iterative format, transforming OpenR1-Math into 333K training instances. Experiments across multiple model architectures demonstrate that our approach reduces computational costs while improving performance, with Qwen2.5-Math-7B showing 3-13% improvements across MATH500, AIME24, and GPQA_diamond benchmarks. Our work challenges the assumed trade-off between reasoning depth and computational efficiency, providing a more scalable approach to complex reasoning without architectural modifications.
MathFimer: Enhancing Mathematical Reasoning by Expanding Reasoning Steps through Fill-in-the-Middle Task
Feb 17, 2025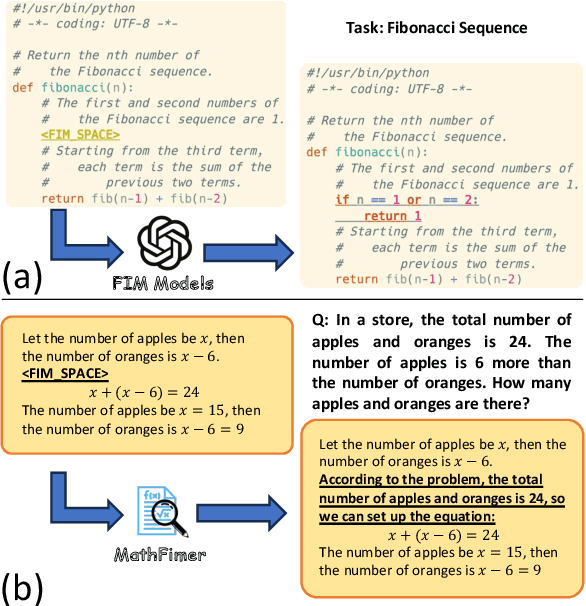
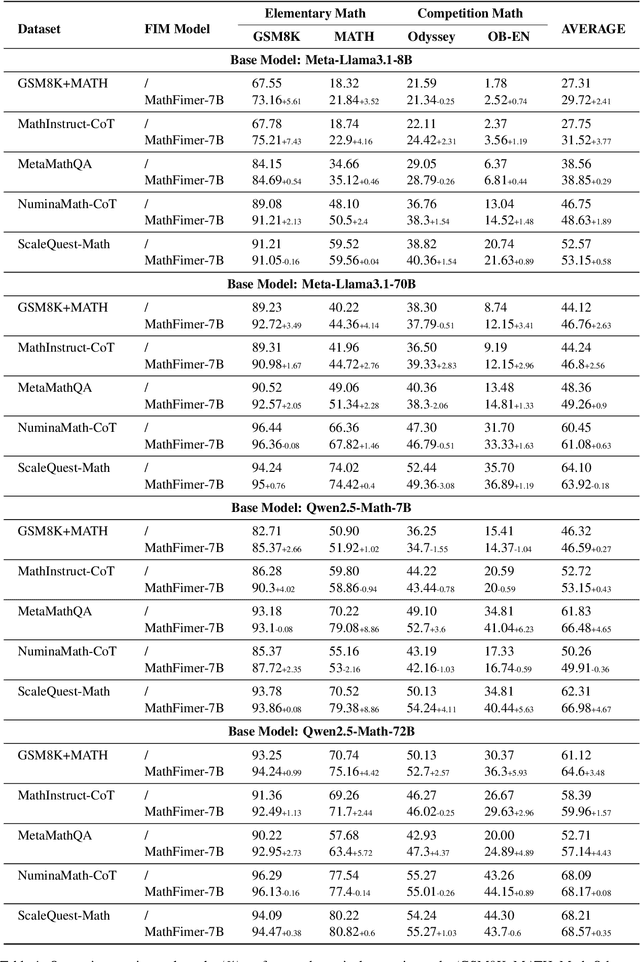
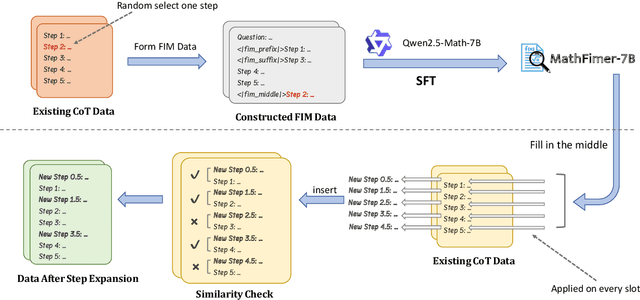
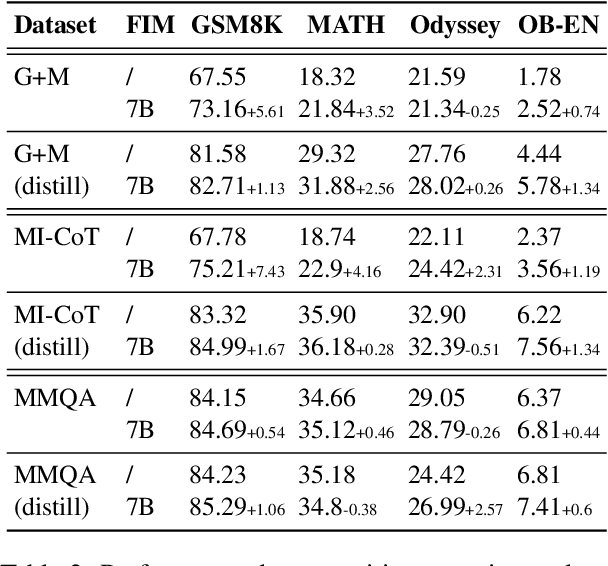
Mathematical reasoning represents a critical frontier in advancing large language models (LLMs). While step-by-step approaches have emerged as the dominant paradigm for mathematical problem-solving in LLMs, the quality of reasoning steps in training data fundamentally constrains the performance of the models. Recent studies has demonstrated that more detailed intermediate steps can enhance model performance, yet existing methods for step expansion either require more powerful external models or incur substantial computational costs. In this paper, we introduce MathFimer, a novel framework for mathematical reasoning step expansion inspired by the "Fill-in-the-middle" task from code completion. By decomposing solution chains into prefix-suffix pairs and training models to reconstruct missing intermediate steps, we develop a specialized model, MathFimer-7B, on our carefully curated NuminaMath-FIM dataset. We then apply these models to enhance existing mathematical reasoning datasets by inserting detailed intermediate steps into their solution chains, creating MathFimer-expanded versions. Through comprehensive experiments on multiple mathematical reasoning datasets, including MathInstruct, MetaMathQA and etc., we demonstrate that models trained on MathFimer-expanded data consistently outperform their counterparts trained on original data across various benchmarks such as GSM8K and MATH. Our approach offers a practical, scalable solution for enhancing mathematical reasoning capabilities in LLMs without relying on powerful external models or expensive inference procedures.
EACO: Enhancing Alignment in Multimodal LLMs via Critical Observation
Dec 06, 2024



Multimodal large language models (MLLMs) have achieved remarkable progress on various visual question answering and reasoning tasks leveraging instruction fine-tuning specific datasets. They can also learn from preference data annotated by human to enhance their reasoning ability and mitigate hallucinations. Most of preference data is generated from the model itself. However, existing methods require high-quality critical labels, which are costly and rely on human or proprietary models like GPT-4V. In this work, we propose Enhancing Alignment in MLLMs via Critical Observation (EACO), which aligns MLLMs by self-generated preference data using only 5k images economically. Our approach begins with collecting and refining a Scoring Evaluation Instruction-tuning dataset to train a critical evaluation model, termed the Critic. This Critic observes model responses across multiple dimensions, selecting preferred and non-preferred outputs for refined Direct Preference Optimization (DPO) tuning. To further enhance model performance, we employ an additional supervised fine-tuning stage after preference tuning. EACO reduces the overall hallucinations by 65.6% on HallusionBench and improves the reasoning ability by 21.8% on MME-Cognition. EACO achieves an 8.5% improvement over LLaVA-v1.6-Mistral-7B across multiple benchmarks. Remarkably, EACO also shows the potential critical ability in open-source MLLMs, demonstrating that EACO is a viable path to boost the competence of MLLMs.
StoryAgent: Customized Storytelling Video Generation via Multi-Agent Collaboration
Nov 07, 2024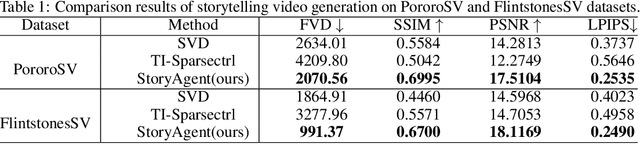
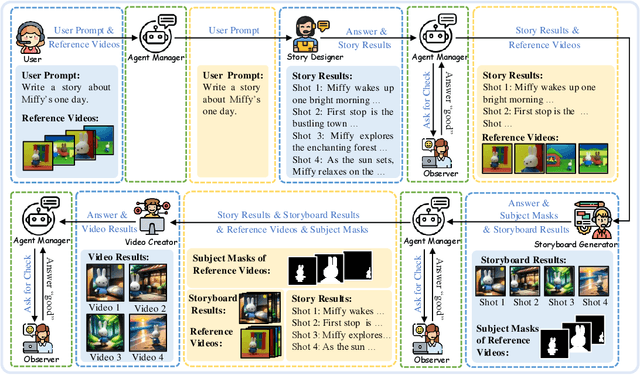


The advent of AI-Generated Content (AIGC) has spurred research into automated video generation to streamline conventional processes. However, automating storytelling video production, particularly for customized narratives, remains challenging due to the complexity of maintaining subject consistency across shots. While existing approaches like Mora and AesopAgent integrate multiple agents for Story-to-Video (S2V) generation, they fall short in preserving protagonist consistency and supporting Customized Storytelling Video Generation (CSVG). To address these limitations, we propose StoryAgent, a multi-agent framework designed for CSVG. StoryAgent decomposes CSVG into distinct subtasks assigned to specialized agents, mirroring the professional production process. Notably, our framework includes agents for story design, storyboard generation, video creation, agent coordination, and result evaluation. Leveraging the strengths of different models, StoryAgent enhances control over the generation process, significantly improving character consistency. Specifically, we introduce a customized Image-to-Video (I2V) method, LoRA-BE, to enhance intra-shot temporal consistency, while a novel storyboard generation pipeline is proposed to maintain subject consistency across shots. Extensive experiments demonstrate the effectiveness of our approach in synthesizing highly consistent storytelling videos, outperforming state-of-the-art methods. Our contributions include the introduction of StoryAgent, a versatile framework for video generation tasks, and novel techniques for preserving protagonist consistency.