 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Evaluation of Unbiased Scene Graph Generation
Aug 03, 2022
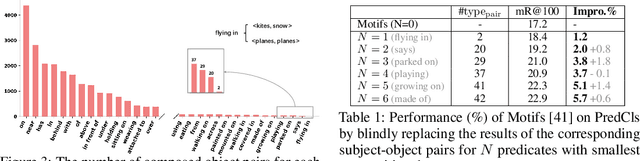
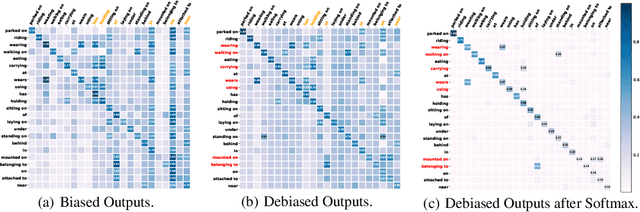
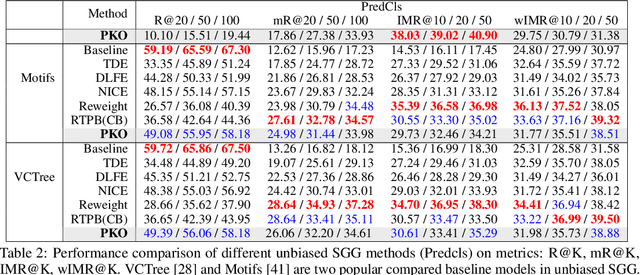
Since the severe imbalanced predicate distributions in common subject-object relations, current Scene Graph Generation (SGG) methods tend to predict frequent predicate categories and fail to recognize rare ones. To improve the robustness of SGG models on different predicate categories, recent research has focused on unbiased SGG and adopted mean Recall@K (mR@K) as the main evaluation metric. However, we discovered two overlooked issues about this de facto standard metric mR@K, which makes current unbiased SGG evaluation vulnerable and unfair: 1) mR@K neglects the correlations among predicates and unintentionally breaks category independence when ranking all the triplet predictions together regardless of the predicate categories, leading to the performance of some predicates being underestimated. 2) mR@K neglects the compositional diversity of different predicates and assigns excessively high weights to some oversimple category samples with limited composable relation triplet types. It totally conflicts with the goal of SGG task which encourages models to detect more types of visual relationship triplets. In addition, we investigate the under-explored correlation between objects and predicates, which can serve as a simple but strong baseline for unbiased SGG. In this paper, we refine mR@K and propose two complementary evaluation metrics for unbiased SGG: Independent Mean Recall (IMR) and weighted IMR (wIMR). These two metrics are designed by considering the category independence and diversity of composable relation triplets, respectively. We compare the proposed metrics with the de facto standard metrics through extensive experiments and discuss the solutions to evaluate unbiased SGG in a more trustworthy way.
Rethinking Multi-Modal Alignment in Video Question Answering from Feature and Sample Perspectives
Apr 25, 2022
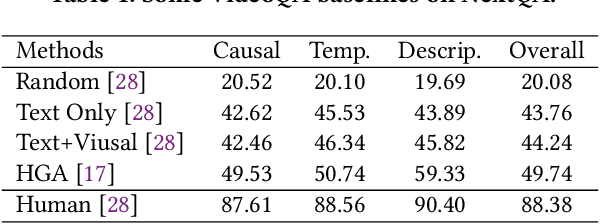
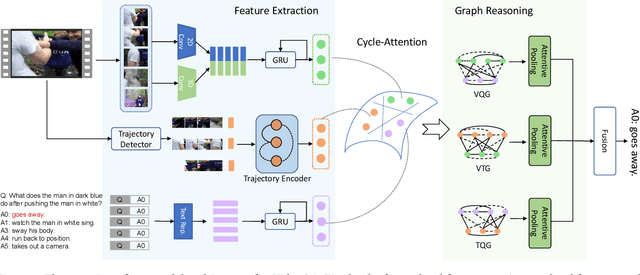
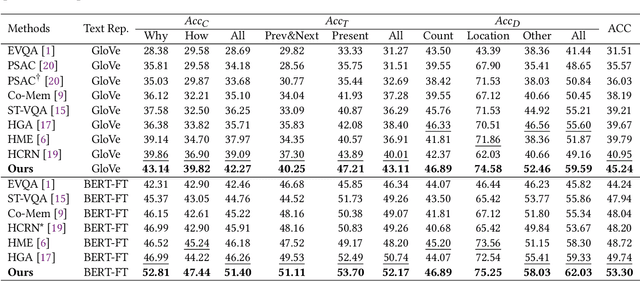
Reasoning about causal and temporal event relations in videos is a new destination of Video Question Answering (VideoQA).The major stumbling block to achieve this purpose is the semantic gap between language and video since they are at different levels of abstraction. Existing efforts mainly focus on designing sophisticated architectures while utilizing frame- or object-level visual representations. In this paper, we reconsider the multi-modal alignment problem in VideoQA from feature and sample perspectives to achieve better performance. From the view of feature,we break down the video into trajectories and first leverage trajectory feature in VideoQA to enhance the alignment between two modalities. Moreover, we adopt a heterogeneous graph architecture and design a hierarchical framework to align both trajectory-level and frame-level visual feature with language feature. In addition, we found that VideoQA models are largely dependent on language priors and always neglect visual-language interactions. Thus, two effective yet portable training augmentation strategies are designed to strengthen the cross-modal correspondence ability of our model from the view of sample. Extensive results show that our method outperforms all the state-of-the-art models on the challenging NExT-QA benchmark, which demonstrates the effectiveness of the proposed method.
Natural Language Video Localization with Learnable Moment Proposals
Sep 22, 2021
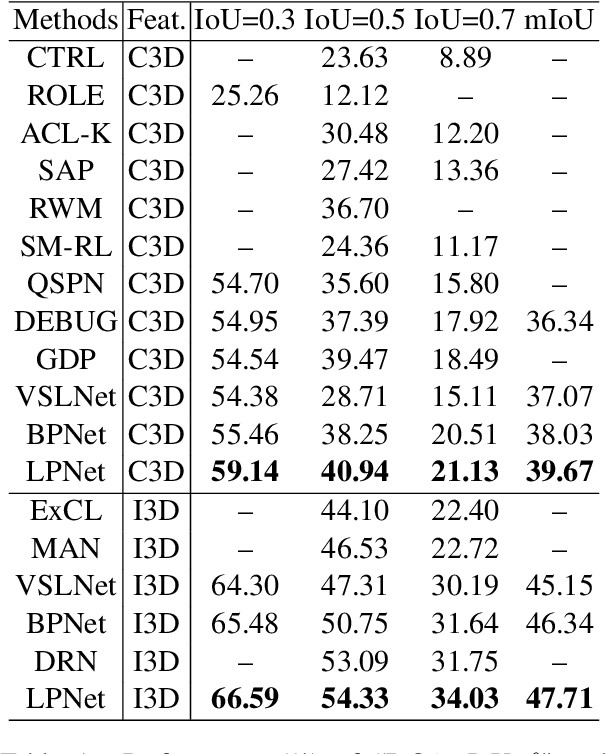
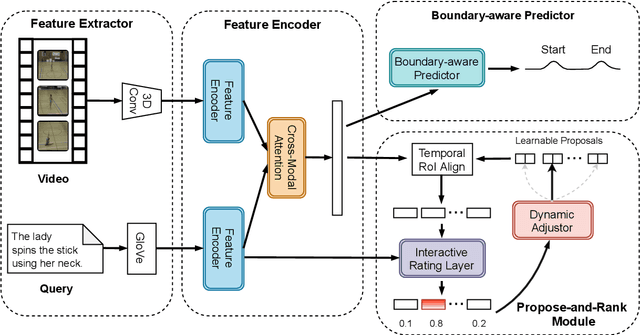
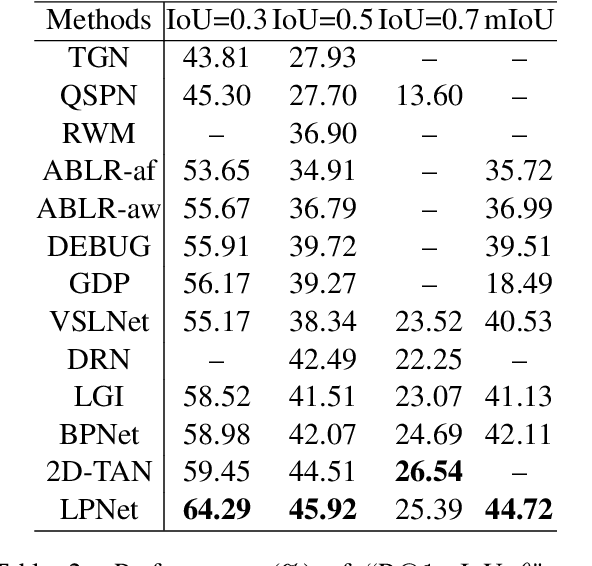
Given an untrimmed video and a natural language query, Natural Language Video Localization (NLVL) aims to identify the video moment described by the query. To address this task, existing methods can be roughly grouped into two groups: 1) propose-and-rank models first define a set of hand-designed moment candidates and then find out the best-matching one. 2) proposal-free models directly predict two temporal boundaries of the referential moment from frames. Currently, almost all the propose-and-rank methods have inferior performance than proposal-free counterparts. In this paper, we argue that propose-and-rank approach is underestimated due to the predefined manners: 1) Hand-designed rules are hard to guarantee the complete coverage of targeted segments. 2) Densely sampled candidate moments cause redundant computation and degrade the performance of ranking process. To this end, we propose a novel model termed LPNet (Learnable Proposal Network for NLVL) with a fixed set of learnable moment proposals. The position and length of these proposals are dynamically adjusted during training process. Moreover, a boundary-aware loss has been proposed to leverage frame-level information and further improve the performance. Extensive ablations on two challenging NLVL benchmarks have demonstrated the effectiveness of LPNet over existing state-of-the-art methods.
Deep Learning for Weakly-Supervised Object Detection and Object Localization: A Survey
May 26, 2021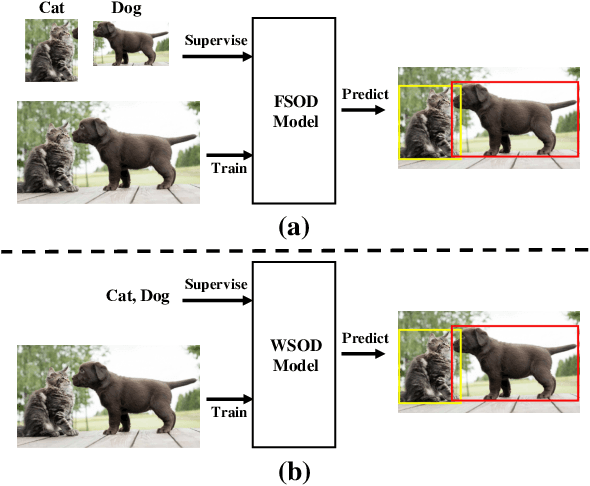
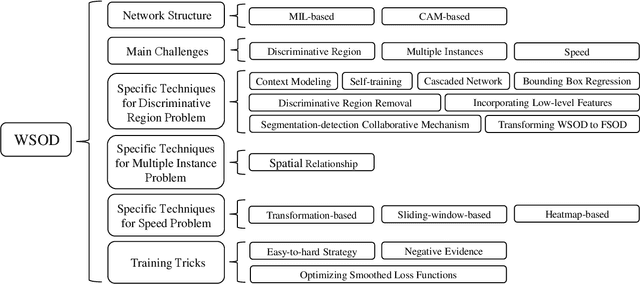

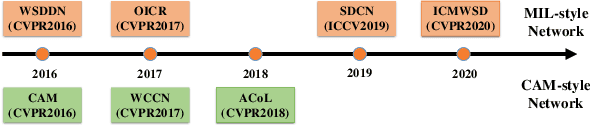
Weakly-Supervised Object Detection (WSOD) and Localization (WSOL), i.e., detecting multiple and single instances with bounding boxes in an image using image-level labels, are long-standing and challenging tasks in the CV community. With the success of deep neural networks in object detection, both WSOD and WSOL have received unprecedented attention. Hundreds of WSOD and WSOL methods and numerous techniques have been proposed in the deep learning era. To this end, in this paper, we consider WSOL is a sub-task of WSOD and provide a comprehensive survey of the recent achievements of WSOD. Specifically, we firstly describe the formulation and setting of the WSOD, including the background, challenges, basic framework. Meanwhile, we summarize and analyze all advanced techniques and training tricks for improving detection performance. Then, we introduce the widely-used datasets and evaluation metrics of WSOD. Lastly, we discuss the future directions of WSOD. We believe that these summaries can help pave a way for future research on WSOD and WSOL.
Boundary Proposal Network for Two-Stage Natural Language Video Localization
Mar 15, 2021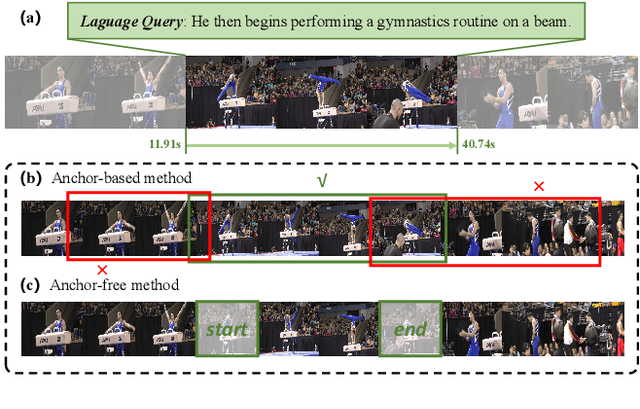
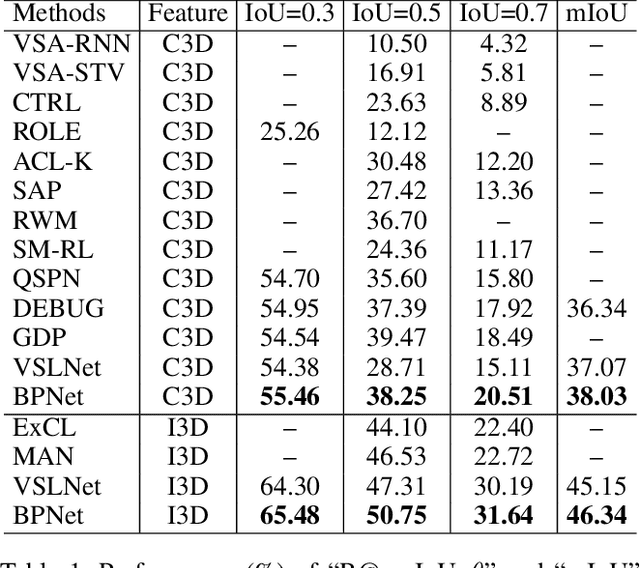
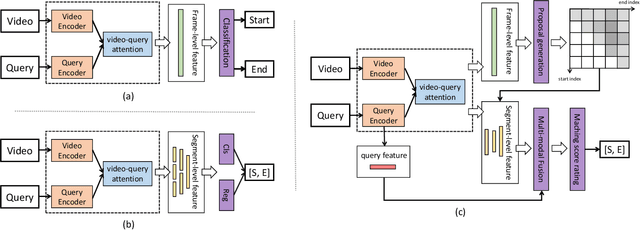
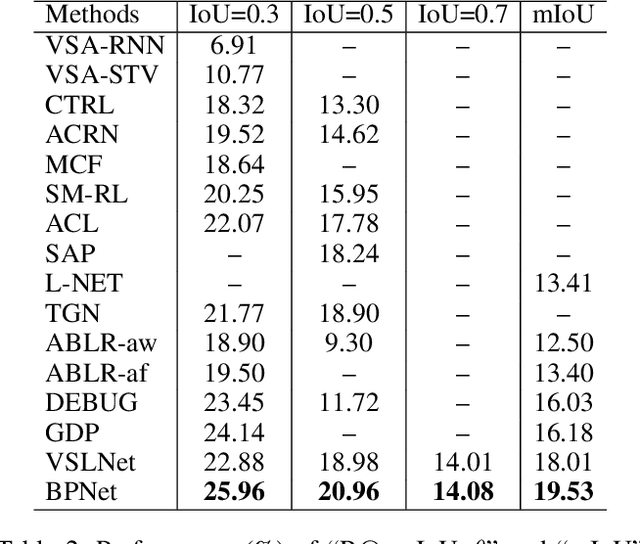
We aim to address the problem of Natural Language Video Localization (NLVL)-localizing the video segment corresponding to a natural language description in a long and untrimmed video. State-of-the-art NLVL methods are almost in one-stage fashion, which can be typically grouped into two categories: 1) anchor-based approach: it first pre-defines a series of video segment candidates (e.g., by sliding window), and then does classification for each candidate; 2) anchor-free approach: it directly predicts the probabilities for each video frame as a boundary or intermediate frame inside the positive segment. However, both kinds of one-stage approaches have inherent drawbacks: the anchor-based approach is susceptible to the heuristic rules, further limiting the capability of handling videos with variant length. While the anchor-free approach fails to exploit the segment-level interaction thus achieving inferior results. In this paper, we propose a novel Boundary Proposal Network (BPNet), a universal two-stage framework that gets rid of the issues mentioned above. Specifically, in the first stage, BPNet utilizes an anchor-free model to generate a group of high-quality candidate video segments with their boundaries. In the second stage, a visual-language fusion layer is proposed to jointly model the multi-modal interaction between the candidate and the language query, followed by a matching score rating layer that outputs the alignment score for each candidate. We evaluate our BPNet on three challenging NLVL benchmarks (i.e., Charades-STA, TACoS and ActivityNet-Captions). Extensive experiments and ablative studies on these datasets demonstrate that the BPNet outperforms the state-of-the-art methods.