 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Multi-Modal Alignment in Video Question Answering from Feature and Sample Perspectives
Paper and Code
Apr 25, 2022
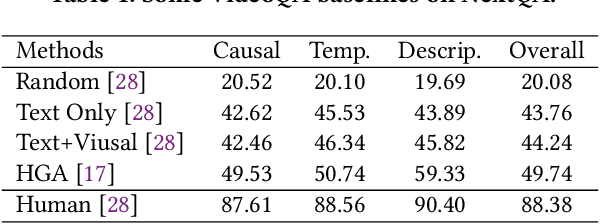
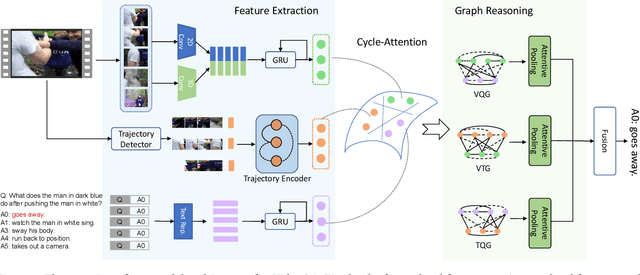
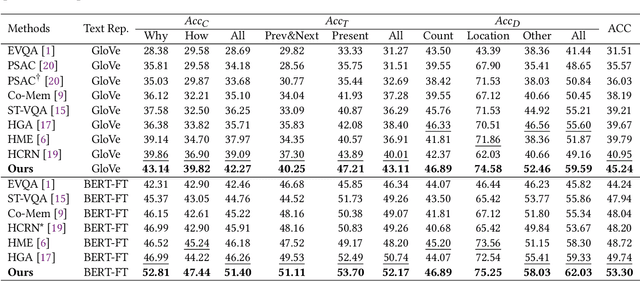
Reasoning about causal and temporal event relations in videos is a new destination of Video Question Answering (VideoQA).The major stumbling block to achieve this purpose is the semantic gap between language and video since they are at different levels of abstraction. Existing efforts mainly focus on designing sophisticated architectures while utilizing frame- or object-level visual representations. In this paper, we reconsider the multi-modal alignment problem in VideoQA from feature and sample perspectives to achieve better performance. From the view of feature,we break down the video into trajectories and first leverage trajectory feature in VideoQA to enhance the alignment between two modalities. Moreover, we adopt a heterogeneous graph architecture and design a hierarchical framework to align both trajectory-level and frame-level visual feature with language feature. In addition, we found that VideoQA models are largely dependent on language priors and always neglect visual-language interactions. Thus, two effective yet portable training augmentation strategies are designed to strengthen the cross-modal correspondence ability of our model from the view of sample. Extensive results show that our method outperforms all the state-of-the-art models on the challenging NExT-QA benchmark, which demonstrates the effectiveness of the proposed method.