 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition
Feb 23, 2024Self-attention is an essential component of large language models(LLMs) but a significant source of inference latency for long sequences. In multi-tenant LLMs serving scenarios, the compute and memory operation cost of self-attention can be optimized by using the probability that multiple LLM requests have shared system prompts in prefixes. In this paper, we introduce ChunkAttention, a prefix-aware self-attention module that can detect matching prompt prefixes across multiple requests and share their key/value tensors in memory at runtime to improve the memory utilization of KV cache. This is achieved by breaking monolithic key/value tensors into smaller chunks and structuring them into the auxiliary prefix tree. Consequently, on top of the prefix-tree based KV cache, we design an efficient self-attention kernel, where a two-phase partition algorithm is implemented to improve the data locality during self-attention computation in the presence of shared system prompts. Experiments show that ChunkAttention can speed up the self-attention kernel by 3.2-4.8$\times$ compared to the start-of-the-art implementation, with the length of the system prompt ranging from 1024 to 4096.
Deep Learning for Weakly-Supervised Object Detection and Object Localization: A Survey
May 26, 2021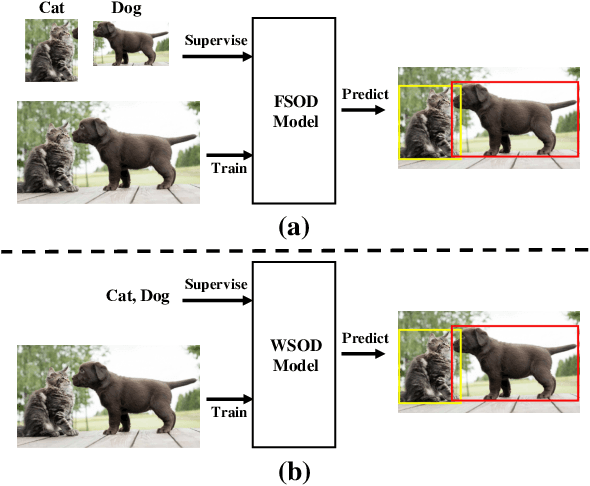
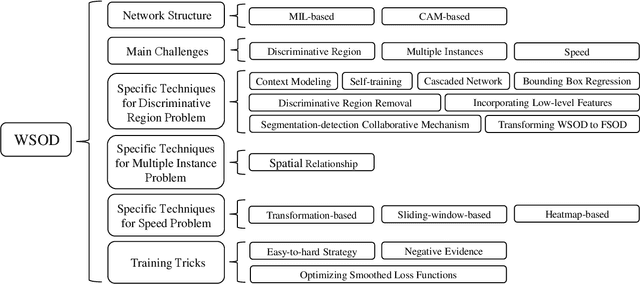

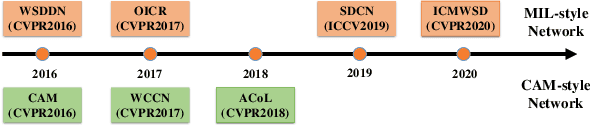
Weakly-Supervised Object Detection (WSOD) and Localization (WSOL), i.e., detecting multiple and single instances with bounding boxes in an image using image-level labels, are long-standing and challenging tasks in the CV community. With the success of deep neural networks in object detection, both WSOD and WSOL have received unprecedented attention. Hundreds of WSOD and WSOL methods and numerous techniques have been proposed in the deep learning era. To this end, in this paper, we consider WSOL is a sub-task of WSOD and provide a comprehensive survey of the recent achievements of WSOD. Specifically, we firstly describe the formulation and setting of the WSOD, including the background, challenges, basic framework. Meanwhile, we summarize and analyze all advanced techniques and training tricks for improving detection performance. Then, we introduce the widely-used datasets and evaluation metrics of WSOD. Lastly, we discuss the future directions of WSOD. We believe that these summaries can help pave a way for future research on WSOD and WSOL.
Improving Weakly-supervised Object Localization via Causal Intervention
Apr 21, 2021
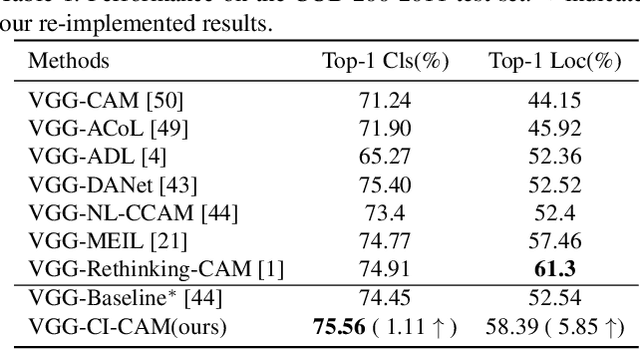
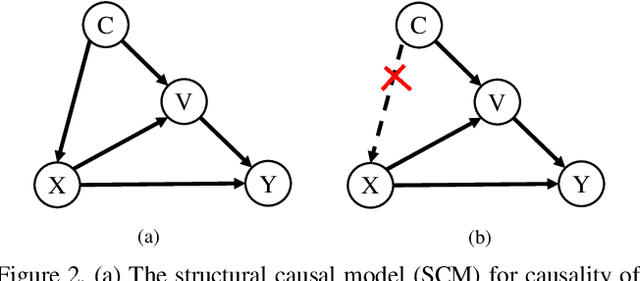
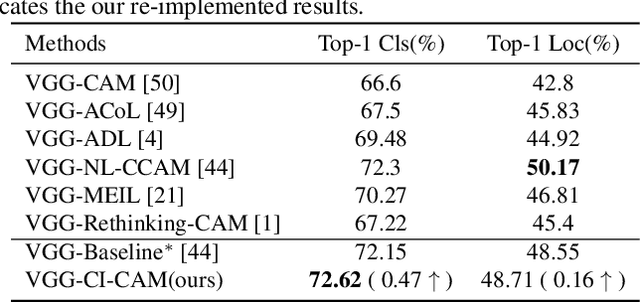
The recent emerged weakly supervised object localization (WSOL) methods can learn to localize an object in the image only using image-level labels. Previous works endeavor to perceive the interval objects from the small and sparse discriminative attention map, yet ignoring the co-occurrence confounder (e.g., bird and sky), which makes the model inspection (e.g., CAM) hard to distinguish between the object and context. In this paper, we make an early attempt to tackle this challenge via causal intervention (CI). Our proposed method, dubbed CI-CAM, explores the causalities among images, contexts, and categories to eliminate the biased co-occurrence in the class activation maps thus improving the accuracy of object localization. Extensive experiments on several benchmarks demonstrate the effectiveness of CI-CAM in learning the clear object boundaries from confounding contexts. Particularly, in CUB-200-2011 which severely suffers from the co-occurrence confounder, CI-CAM significantly outperforms the traditional CAM-based baseline (58.39% vs 52.4% in top-1 localization accuracy). While in more general scenarios such as ImageNet, CI-CAM can also perform on par with the state of the arts.
Boundary Proposal Network for Two-Stage Natural Language Video Localization
Mar 15, 2021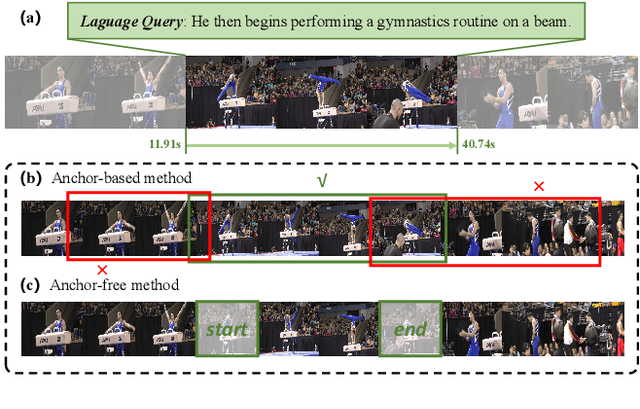
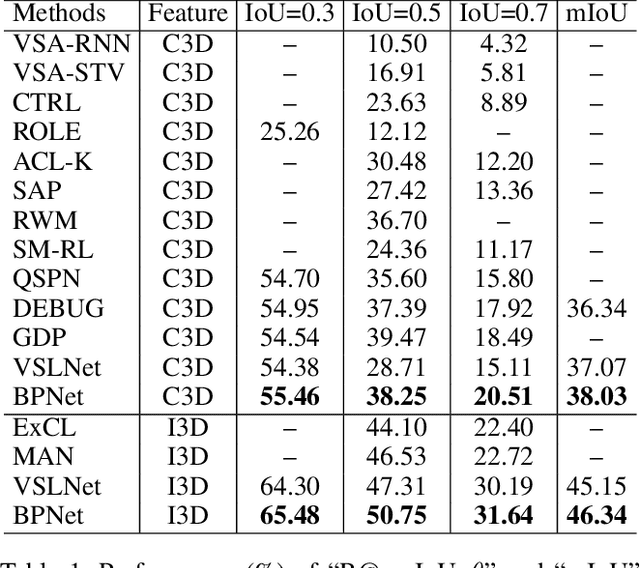
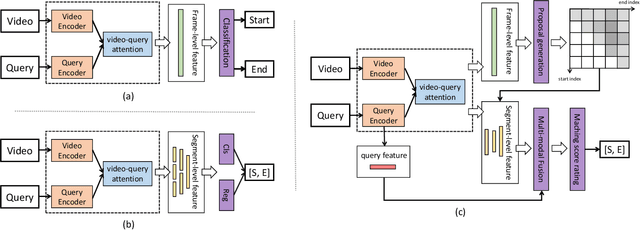
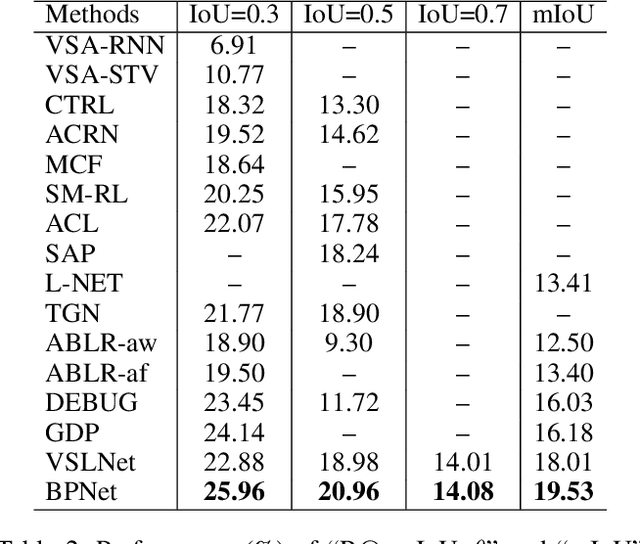
We aim to address the problem of Natural Language Video Localization (NLVL)-localizing the video segment corresponding to a natural language description in a long and untrimmed video. State-of-the-art NLVL methods are almost in one-stage fashion, which can be typically grouped into two categories: 1) anchor-based approach: it first pre-defines a series of video segment candidates (e.g., by sliding window), and then does classification for each candidate; 2) anchor-free approach: it directly predicts the probabilities for each video frame as a boundary or intermediate frame inside the positive segment. However, both kinds of one-stage approaches have inherent drawbacks: the anchor-based approach is susceptible to the heuristic rules, further limiting the capability of handling videos with variant length. While the anchor-free approach fails to exploit the segment-level interaction thus achieving inferior results. In this paper, we propose a novel Boundary Proposal Network (BPNet), a universal two-stage framework that gets rid of the issues mentioned above. Specifically, in the first stage, BPNet utilizes an anchor-free model to generate a group of high-quality candidate video segments with their boundaries. In the second stage, a visual-language fusion layer is proposed to jointly model the multi-modal interaction between the candidate and the language query, followed by a matching score rating layer that outputs the alignment score for each candidate. We evaluate our BPNet on three challenging NLVL benchmarks (i.e., Charades-STA, TACoS and ActivityNet-Captions). Extensive experiments and ablative studies on these datasets demonstrate that the BPNet outperforms the state-of-the-art methods.