 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Video Localization with Learnable Moment Proposals
Paper and Code

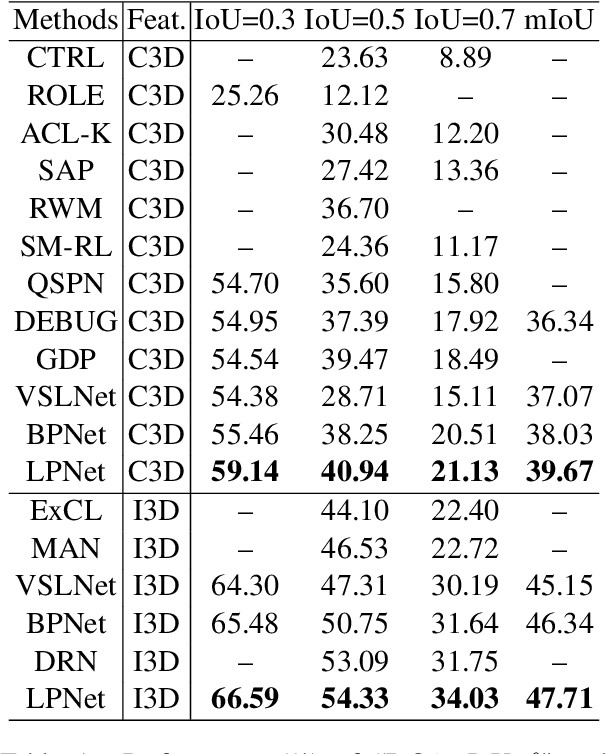
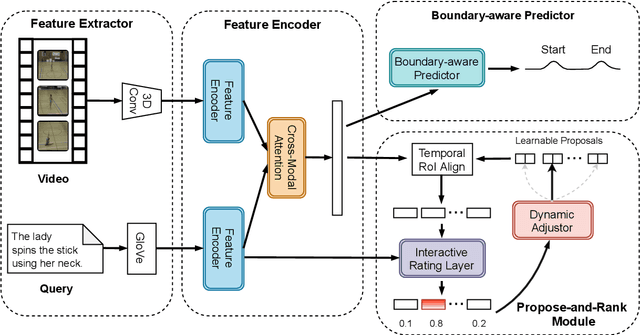
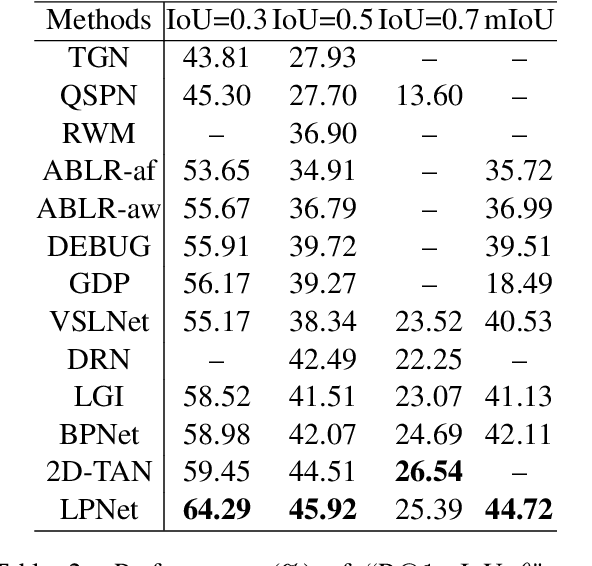
Given an untrimmed video and a natural language query, Natural Language Video Localization (NLVL) aims to identify the video moment described by the query. To address this task, existing methods can be roughly grouped into two groups: 1) propose-and-rank models first define a set of hand-designed moment candidates and then find out the best-matching one. 2) proposal-free models directly predict two temporal boundaries of the referential moment from frames. Currently, almost all the propose-and-rank methods have inferior performance than proposal-free counterparts. In this paper, we argue that propose-and-rank approach is underestimated due to the predefined manners: 1) Hand-designed rules are hard to guarantee the complete coverage of targeted segments. 2) Densely sampled candidate moments cause redundant computation and degrade the performance of ranking process. To this end, we propose a novel model termed LPNet (Learnable Proposal Network for NLVL) with a fixed set of learnable moment proposals. The position and length of these proposals are dynamically adjusted during training process. Moreover, a boundary-aware loss has been proposed to leverage frame-level information and further improve the performance. Extensive ablations on two challenging NLVL benchmarks have demonstrated the effectiveness of LPNet over existing state-of-the-art methods.