 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Robust Generative Approach for Overcoming Data Sparsity and Imbalance in Landslide Modeling with A Tabular Foundation Model
Apr 28, 2026Landslide investigation relies on sufficient and well-balanced observational data influenced by geological, hydrological, and anthropogenic factors. Available landslide inventories are often sparse and imbalanced, which limits understanding of triggering conditions and failure mechanisms. Data generation provides an effective approach to help capture feature dependencies from limited landslide observations. However, existing generation approaches for landslides often struggle to capture complex relationships among features and lack robustness across multiple scenarios and interacting factors. Here, we propose an accurate and robust approach for generating multi-feature landslide datasets by utilizing a tabular foundation model. By leveraging the capacity to learn from limited observations, the proposed approach effectively preserves the multivariate dependencies and statistical characteristics inherent in landslide occurrences. Comparative experiments on 20 landslide inventories demonstrate that the generated datasets closely align with observed distributions, maintain realistic feature dependencies, and exhibit robustness across different environmental contexts. This work provides an effective approach to overcome data sparsity and imbalance and strengthens landslide susceptibility modeling and risk assessment under limited observations.
Knowledge-Data Dually Driven Paradigm for Accurate Landslide Susceptibility Prediction under Data-Scarce Conditions Using Geomorphic Priors and Tabular Foundation Model
Apr 28, 2026Landslide susceptibility prediction is critical for geohazard risk assessment and mitigation. Conventional data-driven paradigm achieves high predictive accuracy but require sufficient conditioning factors and large-scale landslide inventories. However, in practical engineering applications across mountainous and plateau regions, data-scarce conditions are commonly observed, where such data requirements are rarely satisfied, rendering conventional data-driven paradigm inapplicable. To address this issue, we propose a knowledge-data dually driven paradigm for accurate landslide susceptibility prediction under data-scarce conditions. The essential idea behind the proposed novel paradigm is the integration of the geomorphic prior knowledge with scarce landslide data. To validate the proposed paradigm, we first applied it to a data-rich region in central Italy, where a conventional data-driven paradigm trained on the full dataset served as the baseline. By utilizing only 30% of the available landslide data, the proposed paradigm achieved comparable predictive accuracy to the baseline, demonstrating its effectiveness under data-scarce conditions. The paradigm was further evaluated in a genuinely data-scarce environment for application, the Qilian Permafrost Region of the Tibetan Plateau, where it also yielded reliable susceptibility predictions, confirming its applicability under data-scarce conditions.
Statistically Accurate and Robust Generative Prediction of Rock Discontinuities with A Tabular Foundation Model
Nov 17, 2025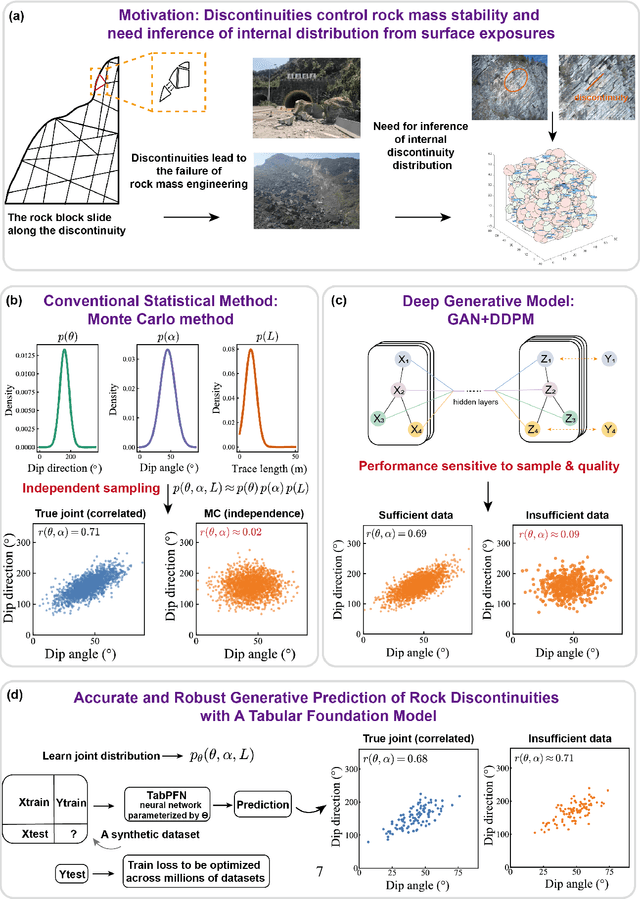



Rock discontinuities critically govern the mechanical behavior and stability of rock masses. Their internal distributions remain largely unobservable and are typically inferred from surface-exposed discontinuities using generative prediction approaches. However, surface-exposed observations are inherently sparse, and existing generative prediction approaches either fail to capture the underlying complex distribution patterns or lack robustness under data-sparse conditions. Here, we proposed a simple yet robust approach for statistically accurate generative prediction of rock discontinuities by utilizing a tabular foundation model. By leveraging the powerful sample learning capability of the foundation model specifically designed for small data, our approach can effectively capture the underlying complex distribution patterns within limited measured discontinuities. Comparative experiments on ten datasets with diverse scales and distribution patterns of discontinuities demonstrate superior accuracy and robustness over conventional statistical models and deep generative approaches. This work advances quantitative characterization of rock mass structures, supporting safer and more reliable data-driven geotechnical design.
Knowledge-infused Deep Learning Enables Interpretable Landslide Forecasting
Jul 18, 2023Forecasting how landslides will evolve over time or whether they will fail is a challenging task due to a variety of factors, both internal and external. Despite their considerable potential to address these challenges, deep learning techniques lack interpretability, undermining the credibility of the forecasts they produce. The recent development of transformer-based deep learning offers untapped possibilities for forecasting landslides with unprecedented interpretability and nonlinear feature learning capabilities. Here, we present a deep learning pipeline that is capable of predicting landslide behavior holistically, which employs a transformer-based network called LFIT to learn complex nonlinear relationships from prior knowledge and multiple source data, identifying the most relevant variables, and demonstrating a comprehensive understanding of landslide evolution and temporal patterns. By integrating prior knowledge, we provide improvement in holistic landslide forecasting, enabling us to capture diverse responses to various influencing factors in different local landslide areas. Using deformation observations as proxies for measuring the kinetics of landslides, we validate our approach by training models to forecast reservoir landslides in the Three Gorges Reservoir and creeping landslides on the Tibetan Plateau. When prior knowledge is incorporated, we show that interpretable landslide forecasting effectively identifies influential factors across various landslides. It further elucidates how local areas respond to these factors, making landslide behavior and trends more interpretable and predictable. The findings from this study will contribute to understanding landslide behavior in a new way and make the proposed approach applicable to other complex disasters influenced by internal and external factors in the future.
An Efficient Deep Learning Approach Using Improved Generative Adversarial Networks for Incomplete Information Completion of Self-driving
Sep 01, 2021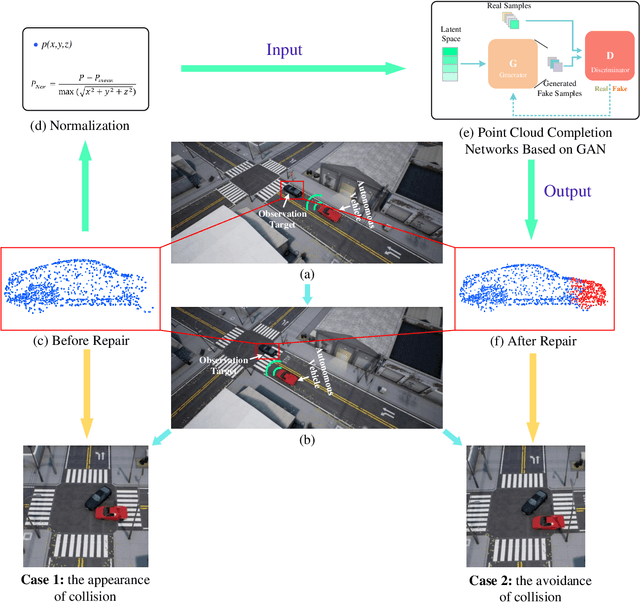
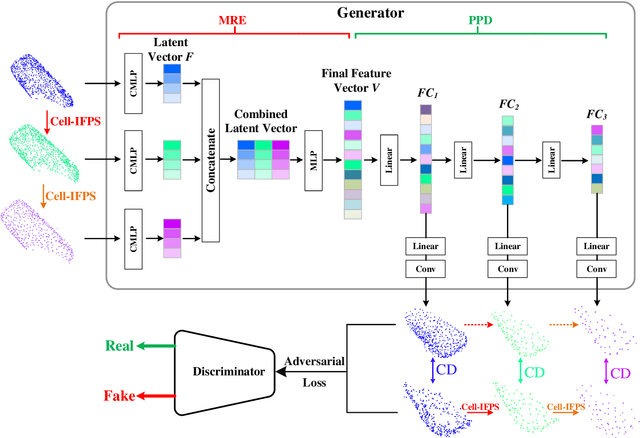
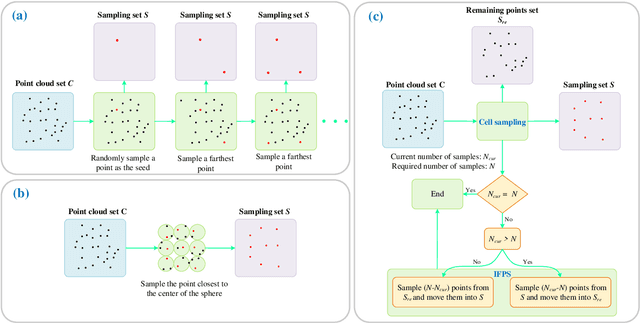
Autonomous driving is the key technology of intelligent logistics in Industrial Internet of Things (IIoT). In autonomous driving, the appearance of incomplete point clouds losing geometric and semantic information is inevitable owing to limitations of occlusion, sensor resolution, and viewing angle when the Light Detection And Ranging (LiDAR) is applied. The emergence of incomplete point clouds, especially incomplete vehicle point clouds, would lead to the reduction of the accuracy of autonomous driving vehicles in object detection, traffic alert, and collision avoidance. Existing point cloud completion networks, such as Point Fractal Network (PF-Net), focus on the accuracy of point cloud completion, without considering the efficiency of inference process, which makes it difficult for them to be deployed for vehicle point cloud repair in autonomous driving. To address the above problem, in this paper, we propose an efficient deep learning approach to repair incomplete vehicle point cloud accurately and efficiently in autonomous driving. In the proposed method, an efficient downsampling algorithm combining incremental sampling and one-time sampling is presented to improves the inference speed of the PF-Net based on Generative Adversarial Network (GAN). To evaluate the performance of the proposed method, a real dataset is used, and an autonomous driving scene is created, where three incomplete vehicle point clouds with 5 different sizes are set for three autonomous driving situations. The improved PF-Net can achieve the speedups of over 19x with almost the same accuracy when compared to the original PF-Net. Experimental results demonstrate that the improved PF-Net can be applied to efficiently complete vehicle point clouds in autonomous driving.
Deep Transfer Learning for Identifications of Slope Surface Cracks
Aug 08, 2021



Geohazards such as landslides have caused great losses to the safety of people's lives and property, which is often accompanied with surface cracks. If such surface cracks could be identified in time, it is of great significance for the monitoring and early warning of geohazards. Currently, the most common method for crack identification is manual detection, which is with low efficiency and accuracy. In this paper, a deep transfer learning framework is proposed to effectively and efficiently identify slope surface cracks for the sake of fast monitoring and early warning of geohazards such as landslides. The essential idea is to employ transfer learning by training (a) the large sample dataset of concrete cracks and (b) the small sample dataset of soil and rock masses cracks. In the proposed framework, (1) pretrained cracks identification models are constructed based on the large sample dataset of concrete cracks; (2) refined cracks identification models are further constructed based on the small sample dataset of soil and rock masses cracks. The proposed framework could be applied to conduct UAV surveys on high-steep slopes to realize the monitoring and early warning of landslides to ensure the safety of people's lives and property.
Heterogeneous Data Fusion Considering Spatial Correlations using Graph Convolutional Networks and its Application in Air Quality Prediction
May 24, 2021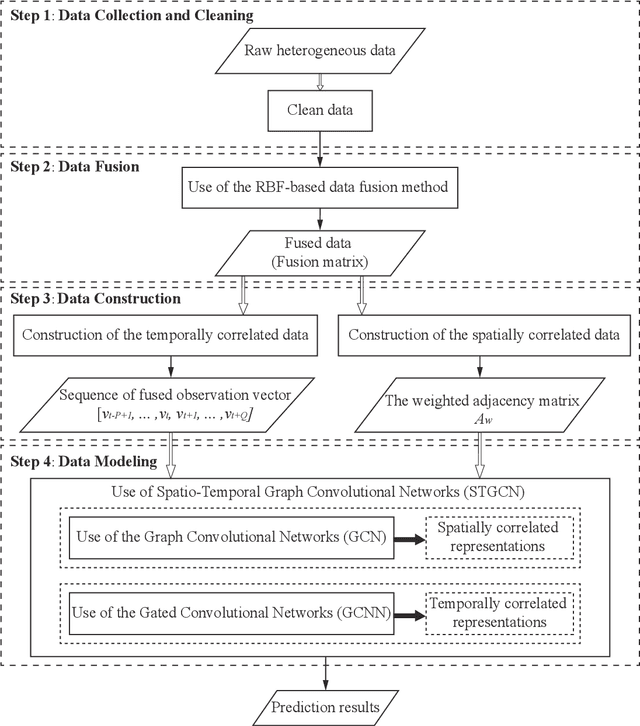
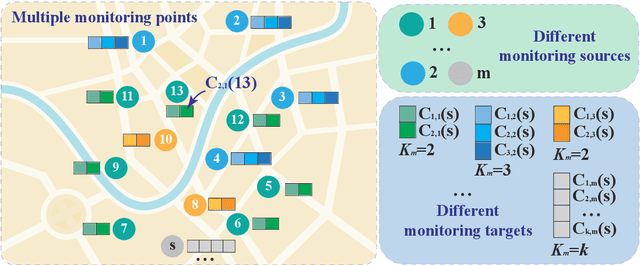

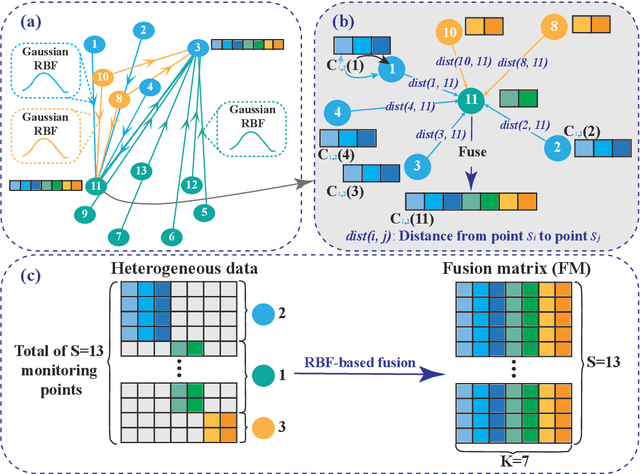
Heterogeneous data are commonly adopted as the inputs for some models that predict the future trends of some observations. Existing predictive models typically ignore the inconsistencies and imperfections in heterogeneous data while also failing to consider the (1) spatial correlations among monitoring points or (2) predictions for the entire study area. To address the above problems, this paper proposes a deep learning method for fusing heterogeneous data collected from multiple monitoring points using graph convolutional networks (GCNs) to predict the future trends of some observations and evaluates its effectiveness by applying it in an air quality predictions scenario. The essential idea behind the proposed method is to (1) fuse the collected heterogeneous data based on the locations of the monitoring points with regard to their spatial correlations and (2) perform prediction based on global information rather than local information. In the proposed method, first, we assemble a fusion matrix using the proposed RBF-based fusion approach; second, based on the fused data, we construct spatially and temporally correlated data as inputs for the predictive model; finally, we employ the spatiotemporal graph convolutional network (STGCN) to predict the future trends of some observations. In the application scenario of air quality prediction, it is observed that (1) the fused data derived from the RBF-based fusion approach achieve satisfactory consistency; (2) the performances of the prediction models based on fused data are better than those based on raw data; and (3) the STGCN model achieves the best performance when compared to those of all baseline models. The proposed method is applicable for similar scenarios where continuous heterogeneous data are collected from multiple monitoring points scattered across a study area.
KCoreMotif: An Efficient Graph Clustering Algorithm for Large Networks by Exploiting k-core Decomposition and Motifs
Aug 21, 2020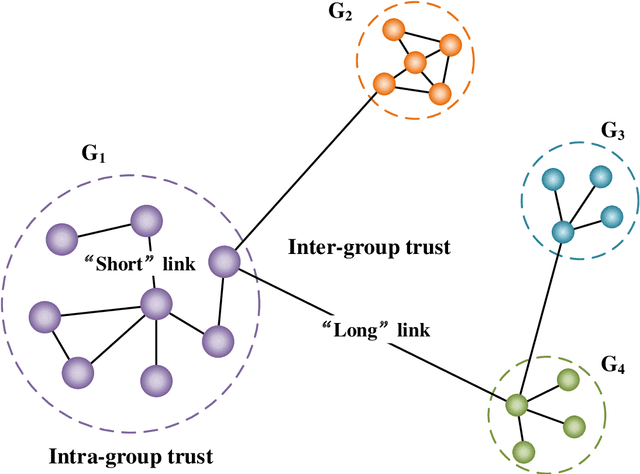
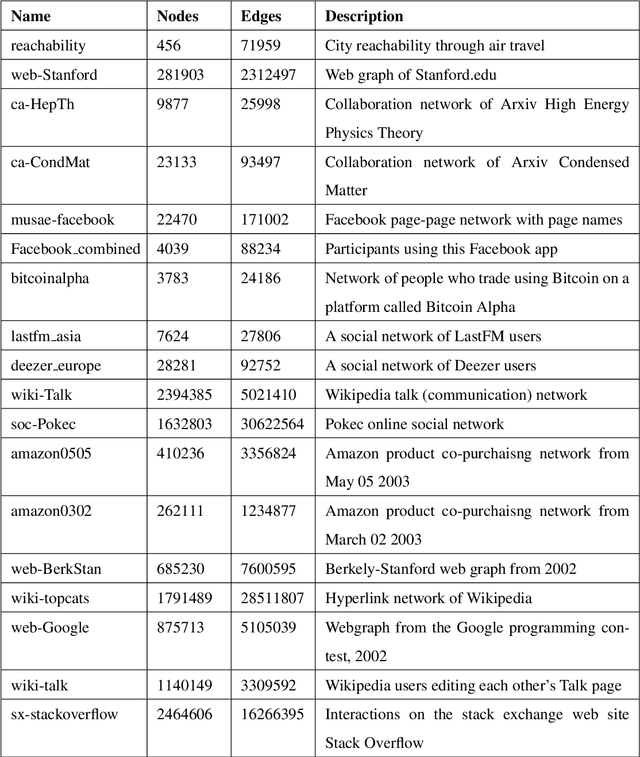
Clustering analysis has been widely used in trust evaluation on various complex networks such as wireless sensors networks and online social networks. Spectral clustering is one of the most commonly used algorithms for graph-structured data (networks). However, the conventional spectral clustering is inherently difficult to work with large-scale networks due to the fact that it needs computationally expensive matrix manipulations. To deal with large networks, in this paper, we propose an efficient graph clustering algorithm, KCoreMotif, specifically for large networks by exploiting k-core decomposition and motifs. The essential idea behind the proposed clustering algorithm is to perform the efficient motif-based spectral clustering algorithm on k-core subgraphs, rather than on the entire graph. More specifically, (1) we first conduct the k-core decomposition of the large input network; (2) we then perform the motif-based spectral clustering for the top k-core subgraphs; (3) we group the remaining vertices in the rest (k-1)-core subgraphs into previously found clusters; and finally obtain the desired clusters of the large input network. To evaluate the performance of the proposed graph clustering algorithm KCoreMotif, we use both the conventional and the motif-based spectral clustering algorithms as the baselines and compare our algorithm with them for 18 groups of real-world datasets. Comparative results demonstrate that the proposed graph clustering algorithm is accurate yet efficient for large networks, which also means that it can be further used to evaluate the intra-cluster and inter-cluster trusts on large networks.
Julia Language in Machine Learning: Algorithms, Applications, and Open Issues
Mar 23, 2020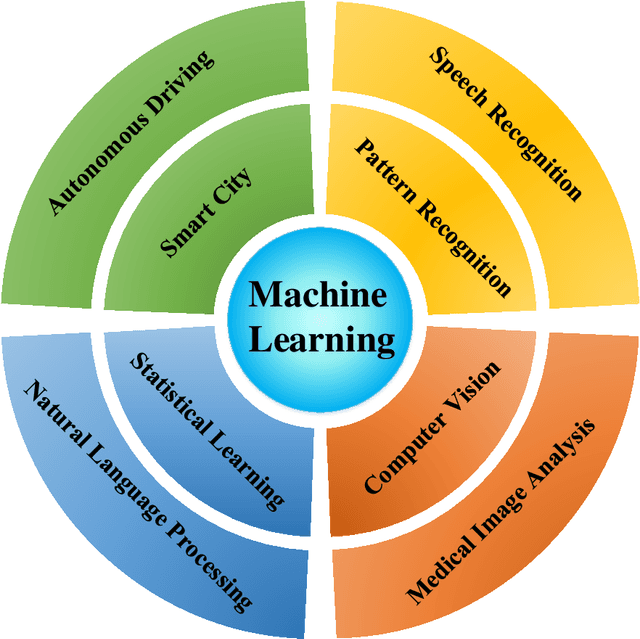
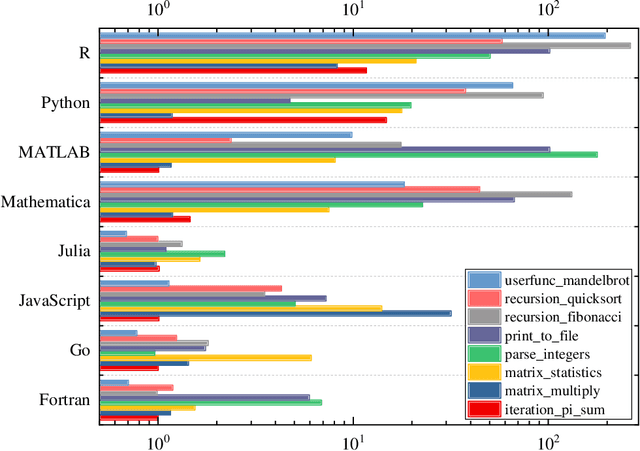
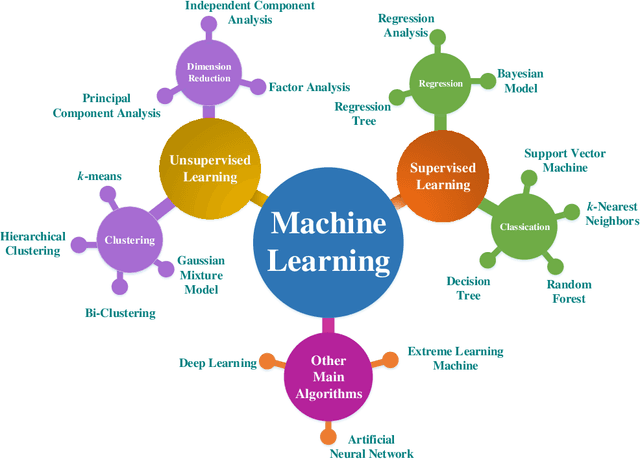
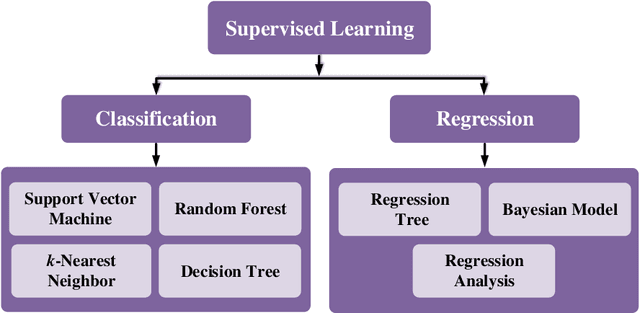
Machine learning is driving development across many fields in science and engineering. A simple and efficient programming language could accelerate applications of machine learning in various fields. Currently, the programming languages most commonly used to develop machine learning algorithms include Python, MATLAB, and C/C ++. However, none of these languages well balance both efficiency and simplicity. The Julia language is a fast, easy-to-use, and open-source programming language that was originally designed for high-performance computing, which can well balance the efficiency and simplicity. This paper summarizes the related research work and developments in the application of the Julia language in machine learning. It first surveys the popular machine learning algorithms that are developed in the Julia language. Then, it investigates applications of the machine learning algorithms implemented with the Julia language. Finally, it discusses the open issues and the potential future directions that arise in the use of the Julia language in machine learning.