 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoBind: Motion Binding for Fine-Grained IMU-Video Pose Alignment
Feb 22, 2026We aim to learn a joint representation between inertial measurement unit (IMU) signals and 2D pose sequences extracted from video, enabling accurate cross-modal retrieval, temporal synchronization, subject and body-part localization, and action recognition. To this end, we introduce MoBind, a hierarchical contrastive learning framework designed to address three challenges: (1) filtering out irrelevant visual background, (2) modeling structured multi-sensor IMU configurations, and (3) achieving fine-grained, sub-second temporal alignment. To isolate motion-relevant cues, MoBind aligns IMU signals with skeletal motion sequences rather than raw pixels. We further decompose full-body motion into local body-part trajectories, pairing each with its corresponding IMU to enable semantically grounded multi-sensor alignment. To capture detailed temporal correspondence, MoBind employs a hierarchical contrastive strategy that first aligns token-level temporal segments, then fuses local (body-part) alignment with global (body-wide) motion aggregation. Evaluated on mRi, TotalCapture, and EgoHumans, MoBind consistently outperforms strong baselines across all four tasks, demonstrating robust fine-grained temporal alignment while preserving coarse semantic consistency across modalities. Code is available at https://github.com/bbvisual/ MoBind.
Rethinking Top Probability from Multi-view for Distracted Driver Behaviour Localization
Nov 19, 2024



Naturalistic driving action localization task aims to recognize and comprehend human behaviors and actions from video data captured during real-world driving scenarios. Previous studies have shown great action localization performance by applying a recognition model followed by probability-based post-processing. Nevertheless, the probabilities provided by the recognition model frequently contain confused information causing challenge for post-processing. In this work, we adopt an action recognition model based on self-supervise learning to detect distracted activities and give potential action probabilities. Subsequently, a constraint ensemble strategy takes advantages of multi-camera views to provide robust predictions. Finally, we introduce a conditional post-processing operation to locate distracted behaviours and action temporal boundaries precisely. Experimenting on test set A2, our method obtains the sixth position on the public leaderboard of track 3 of the 2024 AI City Challenge.
Count What You Want: Exemplar Identification and Few-shot Counting of Human Actions in the Wild
Dec 28, 2023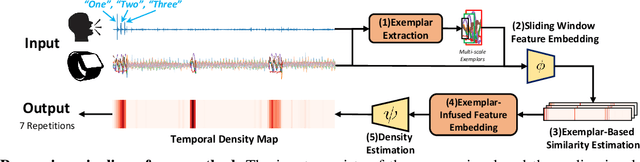
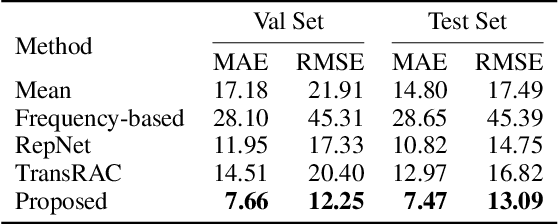
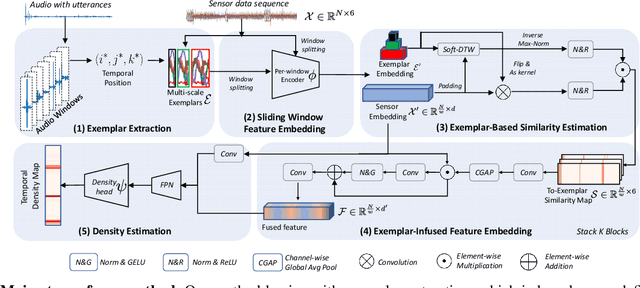

This paper addresses the task of counting human actions of interest using sensor data from wearable devices. We propose a novel exemplar-based framework, allowing users to provide exemplars of the actions they want to count by vocalizing predefined sounds ''one'', ''two'', and ''three''. Our method first localizes temporal positions of these utterances from the audio sequence. These positions serve as the basis for identifying exemplars representing the action class of interest. A similarity map is then computed between the exemplars and the entire sensor data sequence, which is further fed into a density estimation module to generate a sequence of estimated density values. Summing these density values provides the final count. To develop and evaluate our approach, we introduce a diverse and realistic dataset consisting of real-world data from 37 subjects and 50 action categories, encompassing both sensor and audio data. The experiments on this dataset demonstrate the viability of the proposed method in counting instances of actions from new classes and subjects that were not part of the training data. On average, the discrepancy between the predicted count and the ground truth value is 7.47, significantly lower than the errors of the frequency-based and transformer-based methods. Our project, code and dataset can be found at https://github.com/cvlab-stonybrook/ExRAC.
PaaS: Planning as a Service for reactive driving in CARLA Leaderboard
Apr 27, 2023End-to-end deep learning approaches has been proven to be efficient in autonomous driving and robotics. By using deep learning techniques for decision-making, those systems are often referred to as a black box, and the result is driven by data. In this paper, we propose PaaS (Planning as a Service), a vanilla module to generate local trajectory planning for autonomous driving in CARLA simulation. Our method is submitted in International CARLA Autonomous Driving Leaderboard (CADL), which is a platform to evaluate the driving proficiency of autonomous agents in realistic traffic scenarios. Our approach focuses on reactive planning in Frenet frame under complex urban street's constraints and driver's comfort. The planner generates a collection of feasible trajectories, leveraging heuristic cost functions with controllable driving style factor to choose the optimal-control path that satisfies safe travelling criteria. PaaS can provide sufficient solutions to handle well under challenging traffic situations in CADL. As the strict evaluation in CADL Map Track, our approach ranked 3rd out of 9 submissions regarding the measure of driving score. However, with the focus on minimizing the risk of maneuver and ensuring passenger safety, our figures corresponding to infraction penalty dominate the two leading submissions for 20 percent.
Geometric Graph Learning with Extended Atom-Types Features for Protein-Ligand Binding Affinity Prediction
Jan 15, 2023Understanding and accurately predicting protein-ligand binding affinity are essential in the drug design and discovery process. At present, machine learning-based methodologies are gaining popularity as a means of predicting binding affinity due to their efficiency and accuracy, as well as the increasing availability of structural and binding affinity data for protein-ligand complexes. In biomolecular studies, graph theory has been widely applied since graphs can be used to model molecules or molecular complexes in a natural manner. In the present work, we upgrade the graph-based learners for the study of protein-ligand interactions by integrating extensive atom types such as SYBYL and extended connectivity interactive features (ECIF) into multiscale weighted colored graphs (MWCG). By pairing with the gradient boosting decision tree (GBDT) machine learning algorithm, our approach results in two different methods, namely $^\text{sybyl}\text{GGL}$-Score and $^\text{ecif}\text{GGL}$-Score. Both of our models are extensively validated in their scoring power using three commonly used benchmark datasets in the drug design area, namely CASF-2007, CASF-2013, and CASF-2016. The performance of our best model $^\text{sybyl}\text{GGL}$-Score is compared with other state-of-the-art models in the binding affinity prediction for each benchmark. While both of our models achieve state-of-the-art results, the SYBYL atom-type model $^\text{sybyl}\text{GGL}$-Score outperforms other methods by a wide margin in all benchmarks.