 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Behavior Diffusion for Sequential Reaction Generation in Dyadic Setting
May 12, 2025The dyadic reaction generation task involves synthesizing responsive facial reactions that align closely with the behaviors of a conversational partner, enhancing the naturalness and effectiveness of human-like interaction simulations. This paper introduces a novel approach, the Latent Behavior Diffusion Model, comprising a context-aware autoencoder and a diffusion-based conditional generator that addresses the challenge of generating diverse and contextually relevant facial reactions from input speaker behaviors. The autoencoder compresses high-dimensional input features, capturing dynamic patterns in listener reactions while condensing complex input data into a concise latent representation, facilitating more expressive and contextually appropriate reaction synthesis. The diffusion-based conditional generator operates on the latent space generated by the autoencoder to predict realistic facial reactions in a non-autoregressive manner. This approach allows for generating diverse facial reactions that reflect subtle variations in conversational cues and emotional states. Experimental results demonstrate the effectiveness of our approach in achieving superior performance in dyadic reaction synthesis tasks compared to existing methods.
Anatomical Attention Alignment representation for Radiology Report Generation
May 12, 2025Automated Radiology report generation (RRG) aims at producing detailed descriptions of medical images, reducing radiologists' workload and improving access to high-quality diagnostic services. Existing encoder-decoder models only rely on visual features extracted from raw input images, which can limit the understanding of spatial structures and semantic relationships, often resulting in suboptimal text generation. To address this, we propose Anatomical Attention Alignment Network (A3Net), a framework that enhance visual-textual understanding by constructing hyper-visual representations. Our approach integrates a knowledge dictionary of anatomical structures with patch-level visual features, enabling the model to effectively associate image regions with their corresponding anatomical entities. This structured representation improves semantic reasoning, interpretability, and cross-modal alignment, ultimately enhancing the accuracy and clinical relevance of generated reports. Experimental results on IU X-Ray and MIMIC-CXR datasets demonstrate that A3Net significantly improves both visual perception and text generation quality. Our code is available at \href{https://github.com/Vinh-AI/A3Net}{GitHub}.
Rethinking Top Probability from Multi-view for Distracted Driver Behaviour Localization
Nov 19, 2024



Naturalistic driving action localization task aims to recognize and comprehend human behaviors and actions from video data captured during real-world driving scenarios. Previous studies have shown great action localization performance by applying a recognition model followed by probability-based post-processing. Nevertheless, the probabilities provided by the recognition model frequently contain confused information causing challenge for post-processing. In this work, we adopt an action recognition model based on self-supervise learning to detect distracted activities and give potential action probabilities. Subsequently, a constraint ensemble strategy takes advantages of multi-camera views to provide robust predictions. Finally, we introduce a conditional post-processing operation to locate distracted behaviours and action temporal boundaries precisely. Experimenting on test set A2, our method obtains the sixth position on the public leaderboard of track 3 of the 2024 AI City Challenge.
Polyp-SES: Automatic Polyp Segmentation with Self-Enriched Semantic Model
Oct 02, 2024Automatic polyp segmentation is crucial for effective diagnosis and treatment in colonoscopy images. Traditional methods encounter significant challenges in accurately delineating polyps due to limitations in feature representation and the handling of variability in polyp appearance. Deep learning techniques, including CNN and Transformer-based methods, have been explored to improve polyp segmentation accuracy. However, existing approaches often neglect additional semantics, restricting their ability to acquire adequate contexts of polyps in colonoscopy images. In this paper, we propose an innovative method named ``Automatic Polyp Segmentation with Self-Enriched Semantic Model'' to address these limitations. First, we extract a sequence of features from an input image and decode high-level features to generate an initial segmentation mask. Using the proposed self-enriched semantic module, we query potential semantics and augment deep features with additional semantics, thereby aiding the model in understanding context more effectively. Extensive experiments show superior segmentation performance of the proposed method against state-of-the-art polyp segmentation baselines across five polyp benchmarks in both superior learning and generalization capabilities.
KAN-Based Fusion of Dual-Domain for Audio-Driven Facial Landmarks Generation
Sep 09, 2024

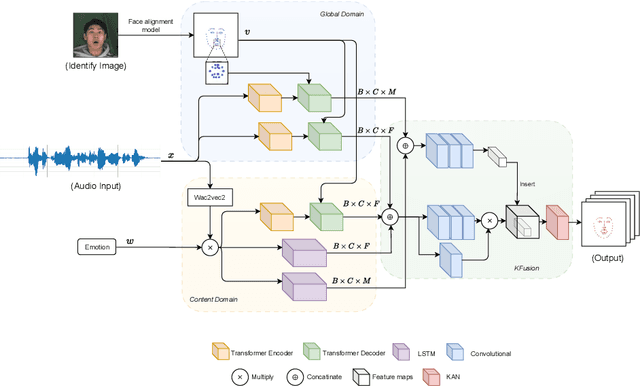

Audio-driven talking face generation is a widely researched topic due to its high applicability. Reconstructing a talking face using audio significantly contributes to fields such as education, healthcare, online conversations, virtual assistants, and virtual reality. Early studies often focused solely on changing the mouth movements, which resulted in outcomes with limited practical applications. Recently, researchers have proposed a new approach of constructing the entire face, including face pose, neck, and shoulders. To achieve this, they need to generate through landmarks. However, creating stable landmarks that align well with the audio is a challenge. In this paper, we propose the KFusion of Dual-Domain model, a robust model that generates landmarks from audio. We separate the audio into two distinct domains to learn emotional information and facial context, then use a fusion mechanism based on the KAN model. Our model demonstrates high efficiency compared to recent models. This will lay the groundwork for the development of the audio-driven talking face generation problem in the future.
Transformer with Leveraged Masked Autoencoder for video-based Pain Assessment
Sep 08, 2024Accurate pain assessment is crucial in healthcare for effective diagnosis and treatment; however, traditional methods relying on self-reporting are inadequate for populations unable to communicate their pain. Cutting-edge AI is promising for supporting clinicians in pain recognition using facial video data. In this paper, we enhance pain recognition by employing facial video analysis within a Transformer-based deep learning model. By combining a powerful Masked Autoencoder with a Transformers-based classifier, our model effectively captures pain level indicators through both expressions and micro-expressions. We conducted our experiment on the AI4Pain dataset, which produced promising results that pave the way for innovative healthcare solutions that are both comprehensive and objective.
Leveraging WaveNet for Dynamic Listening Head Modeling from Speech
Sep 08, 2024



The creation of listener facial responses aims to simulate interactive communication feedback from a listener during a face-to-face conversation. Our goal is to generate believable videos of listeners' heads that respond authentically to a single speaker by a sequence-to-sequence model with an combination of WaveNet and Long short-term memory network. Our approach focuses on capturing the subtle nuances of listener feedback, ensuring the preservation of individual listener identity while expressing appropriate attitudes and viewpoints. Experiment results show that our method surpasses the baseline models on ViCo benchmark Dataset.
Adaptation of Distinct Semantics for Uncertain Areas in Polyp Segmentation
May 13, 2024

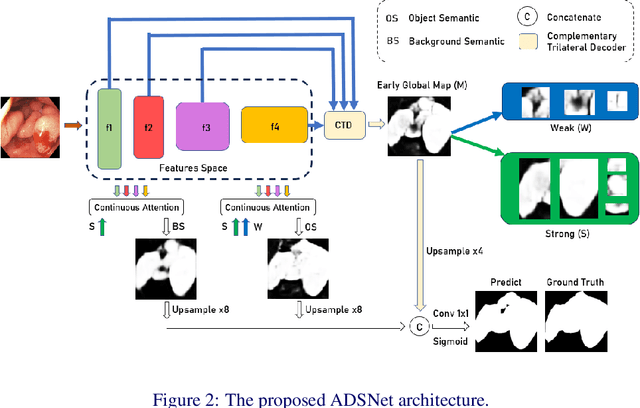

Colonoscopy is a common and practical method for detecting and treating polyps. Segmenting polyps from colonoscopy image is useful for diagnosis and surgery progress. Nevertheless, achieving excellent segmentation performance is still difficult because of polyp characteristics like shape, color, condition, and obvious non-distinction from the surrounding context. This work presents a new novel architecture namely Adaptation of Distinct Semantics for Uncertain Areas in Polyp Segmentation (ADSNet), which modifies misclassified details and recovers weak features having the ability to vanish and not be detected at the final stage. The architecture consists of a complementary trilateral decoder to produce an early global map. A continuous attention module modifies semantics of high-level features to analyze two separate semantics of the early global map. The suggested method is experienced on polyp benchmarks in learning ability and generalization ability, experimental results demonstrate the great correction and recovery ability leading to better segmentation performance compared to the other state of the art in the polyp image segmentation task. Especially, the proposed architecture could be experimented flexibly for other CNN-based encoders, Transformer-based encoders, and decoder backbones.
DCTM: Dilated Convolutional Transformer Model for Multimodal Engagement Estimation in Conversation
Jul 31, 2023



Conversational engagement estimation is posed as a regression problem, entailing the identification of the favorable attention and involvement of the participants in the conversation. This task arises as a crucial pursuit to gain insights into human's interaction dynamics and behavior patterns within a conversation. In this research, we introduce a dilated convolutional Transformer for modeling and estimating human engagement in the MULTIMEDIATE 2023 competition. Our proposed system surpasses the baseline models, exhibiting a noteworthy $7$\% improvement on test set and $4$\% on validation set. Moreover, we employ different modality fusion mechanism and show that for this type of data, a simple concatenated method with self-attention fusion gains the best performance.
Mental Workload Estimation with Electroencephalogram Signals by Combining Multi-Space Deep Models
Jul 23, 2023The human brain is in a continuous state of activity during both work and rest. Mental activity is a daily process, and when the brain is overworked, it can have negative effects on human health. In recent years, great attention has been paid to early detection of mental health problems because it can help prevent serious health problems and improve quality of life. Several signals are used to assess mental state, but the electroencephalogram (EEG) is widely used by researchers because of the large amount of information it provides about the brain. This paper aims to classify mental workload into three states and estimate continuum levels. Our method combines multiple dimensions of space to achieve the best results for mental estimation. In the time domain approach, we use Temporal Convolutional Networks, and in the frequency domain, we propose a new architecture called the Multi-Dimensional Residual Block, which combines residual blocks.