 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAN-Based Fusion of Dual-Domain for Audio-Driven Facial Landmarks Generation
Paper and Code
Sep 09, 2024

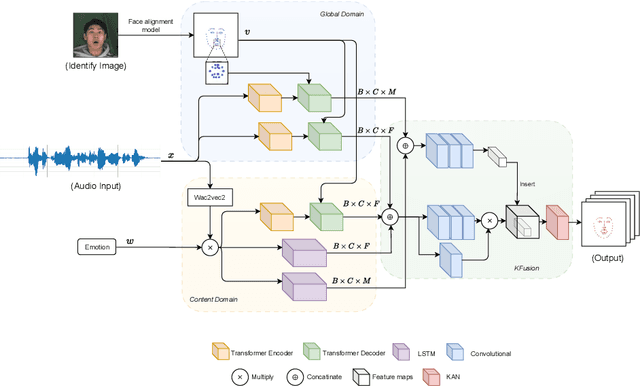

Audio-driven talking face generation is a widely researched topic due to its high applicability. Reconstructing a talking face using audio significantly contributes to fields such as education, healthcare, online conversations, virtual assistants, and virtual reality. Early studies often focused solely on changing the mouth movements, which resulted in outcomes with limited practical applications. Recently, researchers have proposed a new approach of constructing the entire face, including face pose, neck, and shoulders. To achieve this, they need to generate through landmarks. However, creating stable landmarks that align well with the audio is a challenge. In this paper, we propose the KFusion of Dual-Domain model, a robust model that generates landmarks from audio. We separate the audio into two distinct domains to learn emotional information and facial context, then use a fusion mechanism based on the KAN model. Our model demonstrates high efficiency compared to recent models. This will lay the groundwork for the development of the audio-driven talking face generation problem in the future.