 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMental Workload Estimation with Electroencephalogram Signals by Combining Multi-Space Deep Models
Jul 23, 2023The human brain is in a continuous state of activity during both work and rest. Mental activity is a daily process, and when the brain is overworked, it can have negative effects on human health. In recent years, great attention has been paid to early detection of mental health problems because it can help prevent serious health problems and improve quality of life. Several signals are used to assess mental state, but the electroencephalogram (EEG) is widely used by researchers because of the large amount of information it provides about the brain. This paper aims to classify mental workload into three states and estimate continuum levels. Our method combines multiple dimensions of space to achieve the best results for mental estimation. In the time domain approach, we use Temporal Convolutional Networks, and in the frequency domain, we propose a new architecture called the Multi-Dimensional Residual Block, which combines residual blocks.
Generic Event Boundary Detection in Video with Pyramid Features
Jan 11, 2023



Generic event boundary detection (GEBD) aims to split video into chunks at a broad and diverse set of actions as humans naturally perceive event boundaries. In this study, we present an approach that considers the correlation between neighbor frames with pyramid feature maps in both spatial and temporal dimensions to construct a framework for localizing generic events in video. The features at multiple spatial dimensions of a pre-trained ResNet-50 are exploited with different views in the temporal dimension to form a temporal pyramid feature map. Based on that, the similarity between neighbor frames is calculated and projected to build a temporal pyramid similarity feature vector. A decoder with 1D convolution operations is used to decode these similarities to a new representation that incorporates their temporal relationship for later boundary score estimation. Extensive experiments conducted on the GEBD benchmark dataset show the effectiveness of our system and its variations, in which we outperformed the state-of-the-art approaches. Additional experiments on TAPOS dataset, which contains long-form videos with Olympic sport actions, demonstrated the effectiveness of our study compared to others.
Fine-tuning Wav2vec for Vocal-burst Emotion Recognition
Oct 01, 2022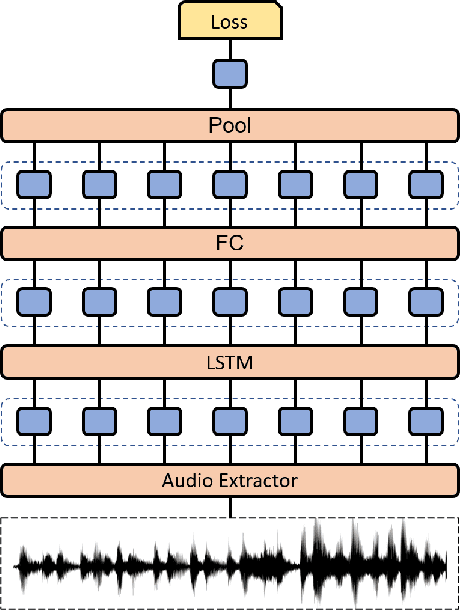
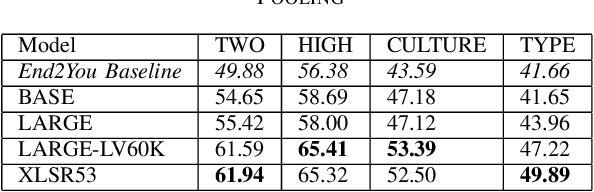
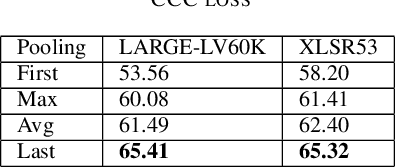
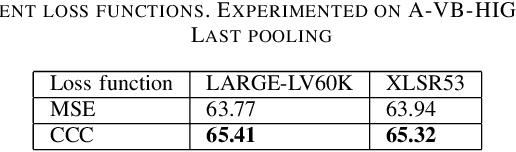
The ACII Affective Vocal Bursts (A-VB) competition introduces a new topic in affective computing, which is understanding emotional expression using the non-verbal sound of humans. We are familiar with emotion recognition via verbal vocal or facial expression. However, the vocal bursts such as laughs, cries, and signs, are not exploited even though they are very informative for behavior analysis. The A-VB competition comprises four tasks that explore non-verbal information in different spaces. This technical report describes the method and the result of SclabCNU Team for the tasks of the challenge. We achieved promising results compared to the baseline model provided by the organizers.
Self-Relation Attention and Temporal Awareness for Emotion Recognition via Vocal Burst
Sep 26, 2022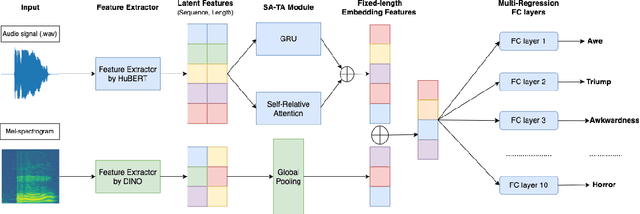

The technical report presents our emotion recognition pipeline for high-dimensional emotion task (A-VB High) in The ACII Affective Vocal Bursts (A-VB) 2022 Workshop \& Competition. Our proposed method contains three stages. Firstly, we extract the latent features from the raw audio signal and its Mel-spectrogram by self-supervised learning methods. Then, the features from the raw signal are fed to the self-relation attention and temporal awareness (SA-TA) module for learning the valuable information between these latent features. Finally, we concatenate all the features and utilize a fully-connected layer to predict each emotion's score. By empirical experiments, our proposed method achieves a mean concordance correlation coefficient (CCC) of 0.7295 on the test set, compared to 0.5686 on the baseline model. The code of our method is available at https://github.com/linhtd812/A-VB2022.
An Ensemble Approach for Multiple Emotion Descriptors Estimation Using Multi-task Learning
Jul 22, 2022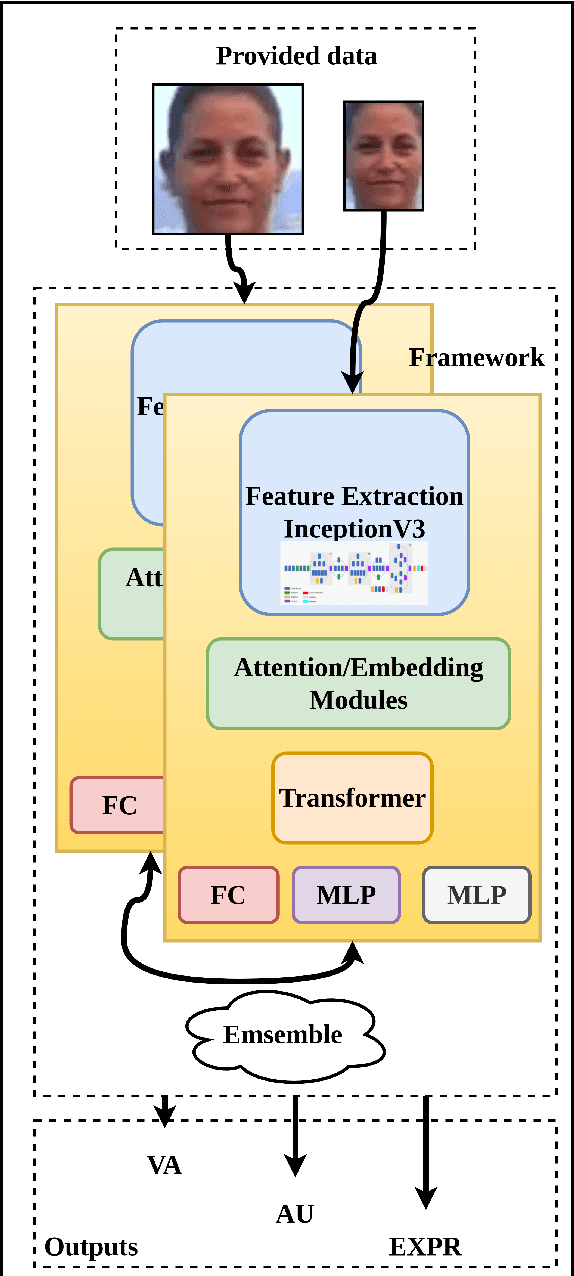


This paper illustrates our submission method to the fourth Affective Behavior Analysis in-the-Wild (ABAW) Competition. The method is used for the Multi-Task Learning Challenge. Instead of using only face information, we employ full information from a provided dataset containing face and the context around the face. We utilized the InceptionNet V3 model to extract deep features then we applied the attention mechanism to refine the features. After that, we put those features into the transformer block and multi-layer perceptron networks to get the final multiple kinds of emotion. Our model predicts arousal and valence, classifies the emotional expression and estimates the action units simultaneously. The proposed system achieves the performance of 0.917 on the MTL Challenge validation dataset.
Multi-task Cross Attention Network in Facial Behavior Analysis
Jul 21, 2022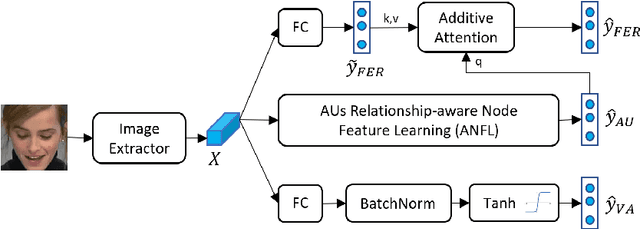

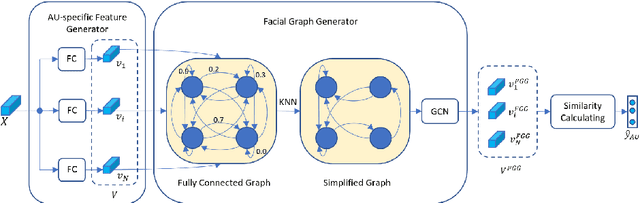
Facial behavior analysis is a broad topic with various categories such as facial emotion recognition, age and gender recognition, ... Many studies focus on individual tasks while the multi-task learning approach is still open and requires more research. In this paper, we present our solution and experiment result for the Multi-Task Learning challenge of the Affective Behavior Analysis in-the-wild competition. The challenge is a combination of three tasks: action unit detection, facial expression recognition and valance-arousal estimation. To address this challenge, we introduce a cross-attentive module to improve multi-task learning performance. Additionally, a facial graph is applied to capture the association among action units. As a result, we achieve the evaluation measure of 1.24 on the validation data provided by the organizers, which is better than the baseline result of 0.30.
An Attention-based Method for Action Unit Detection at the 3rd ABAW Competition
Mar 23, 2022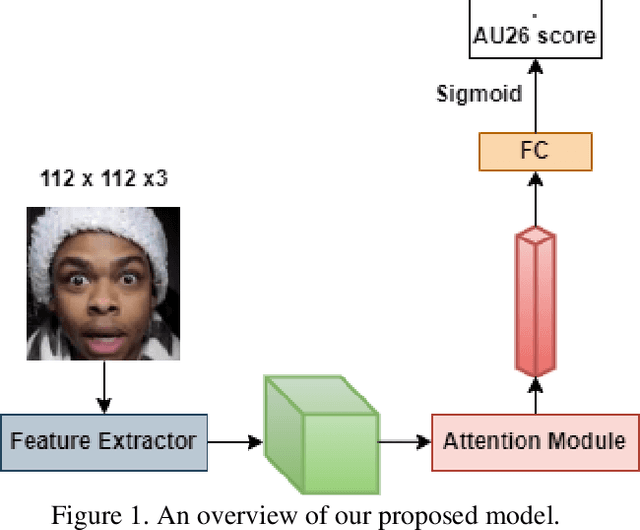
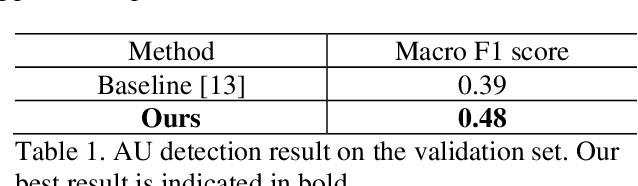
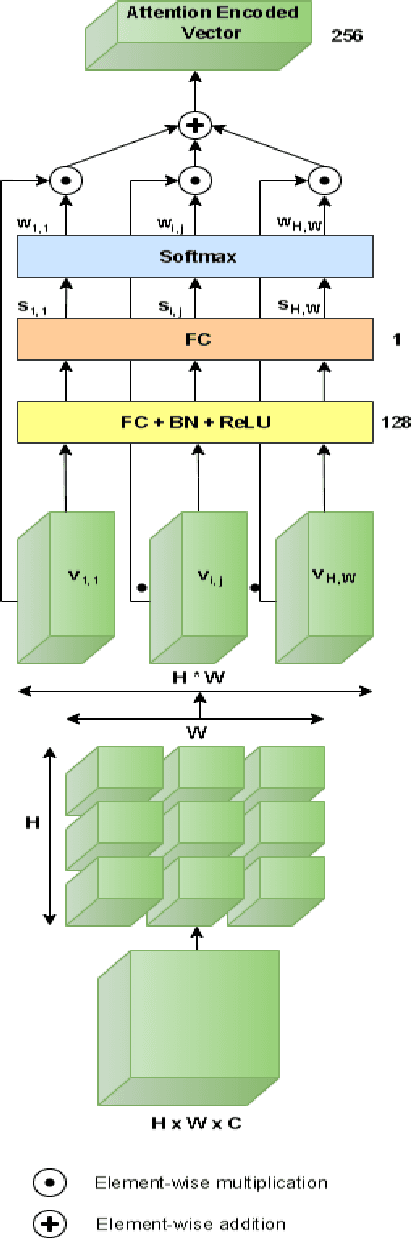
Facial Action Coding System is an approach for modeling the complexity of human emotional expression. Automatic action unit (AU) detection is a crucial research area in human-computer interaction. This paper describes our submission to the third Affective Behavior Analysis in-the-wild (ABAW) competition 2022. We proposed a method for detecting facial action units in the video. At the first stage, a lightweight CNN-based feature extractor is employed to extract the feature map from each video frame. Then, an attention module is applied to refine the attention map. The attention encoded vector is derived using a weighted sum of the feature map and the attention scores later. Finally, the sigmoid function is used at the output layer to make the prediction suitable for multi-label AUs detection. We achieved a macro F1 score of 0.48 on the ABAW challenge validation set compared to 0.39 from the baseline model.
Emotion Recognition with Incomplete Labels Using Modified Multi-task Learning Technique
Jul 09, 2021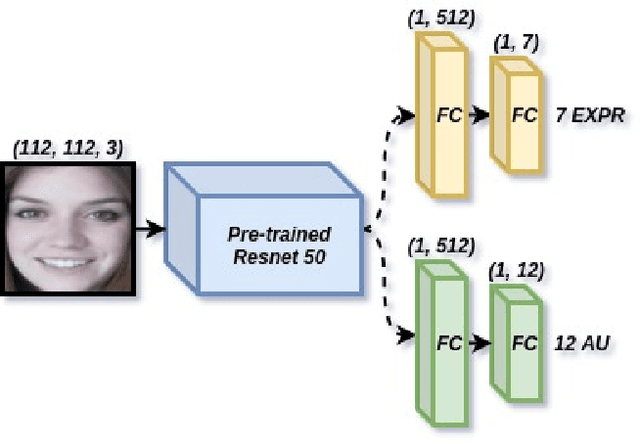
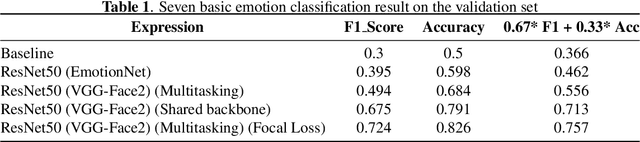
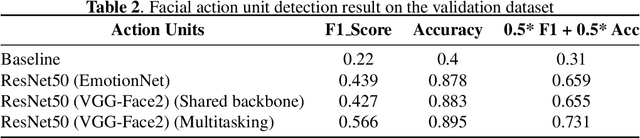
The task of predicting affective information in the wild such as seven basic emotions or action units from human faces has gradually become more interesting due to the accessibility and availability of massive annotated datasets. In this study, we propose a method that utilizes the association between seven basic emotions and twelve action units from the AffWild2 dataset. The method based on the architecture of ResNet50 involves the multi-task learning technique for the incomplete labels of the two tasks. By combining the knowledge for two correlated tasks, both performances are improved by a large margin compared to those with the model employing only one kind of label.
Temporal Convolution Networks with Positional Encoding for Evoked Expression Estimation
Jun 16, 2021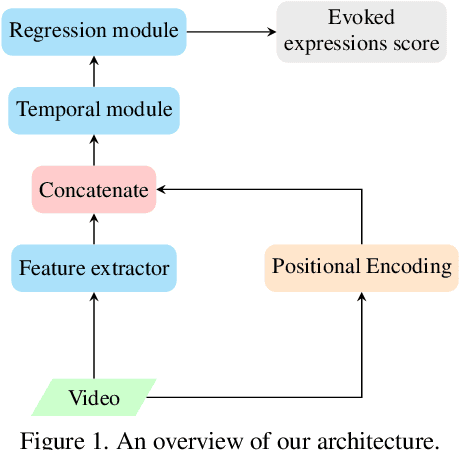
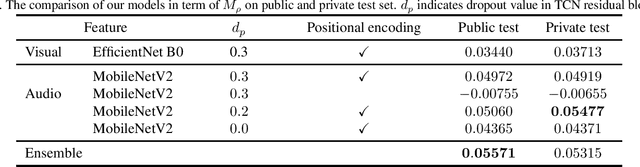
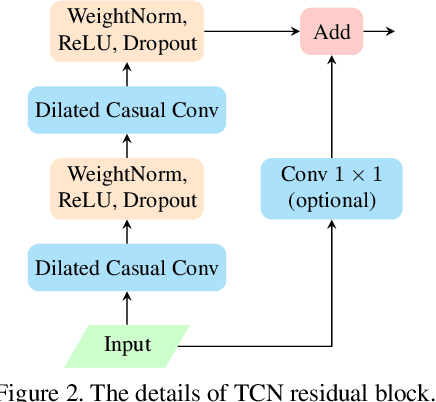
This paper presents an approach for Evoked Expressions from Videos (EEV) challenge, which aims to predict evoked facial expressions from video. We take advantage of pre-trained models on large-scale datasets in computer vision and audio signals to extract the deep representation of timestamps in the video. A temporal convolution network, rather than an RNN like architecture, is used to explore temporal relationships due to its advantage in memory consumption and parallelism. Furthermore, to address the missing annotations of some timestamps, positional encoding is employed to ensure continuity of input data when discarding these timestamps during training. We achieved state-of-the-art results on the EEV challenge with a Pearson correlation coefficient of 0.05477, the first ranked performance in the EEV 2021 challenge.
Variants of BERT, Random Forests and SVM approach for Multimodal Emotion-Target Sub-challenge
Jul 28, 2020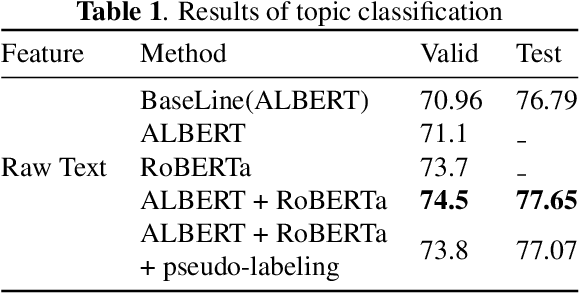
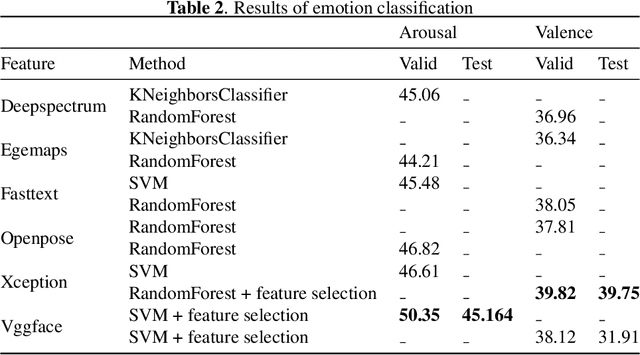
Emotion recognition has become a major problem in computer vision in recent years that made a lot of effort by researchers to overcome the difficulties in this task. In the field of affective computing, emotion recognition has a wide range of applications, such as healthcare, robotics, human-computer interaction. Due to its practical importance for other tasks, many techniques and approaches have been investigated for different problems and various data sources. Nevertheless, comprehensive fusion of the audio-visual and language modalities to get the benefits from them is still a problem to solve. In this paper, we present and discuss our classification methodology for MuSe-Topic Sub-challenge, as well as the data and results. For the topic classification, we ensemble two language models which are ALBERT and RoBERTa to predict 10 classes of topics. Moreover, for the classification of valence and arousal, SVM and Random forests are employed in conjunction with feature selection to enhance the performance.