 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomical Attention Alignment representation for Radiology Report Generation
May 12, 2025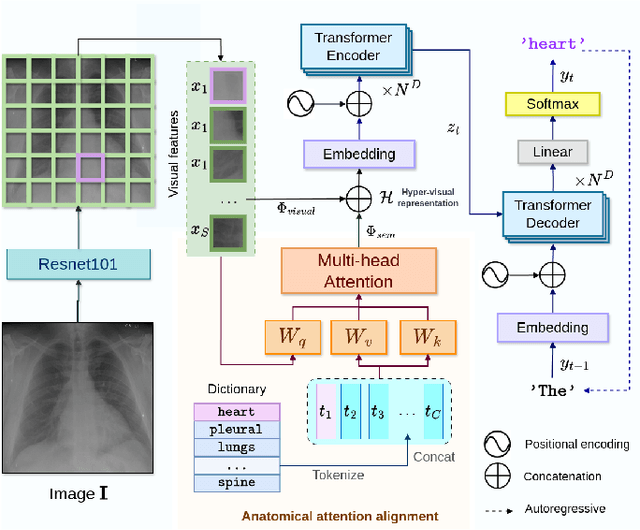
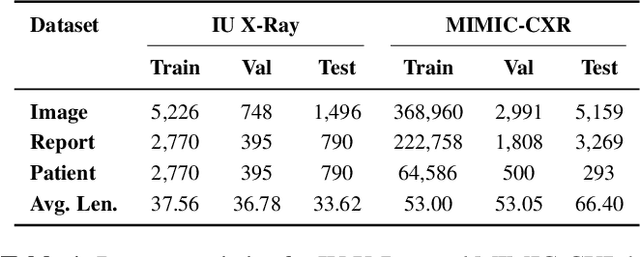
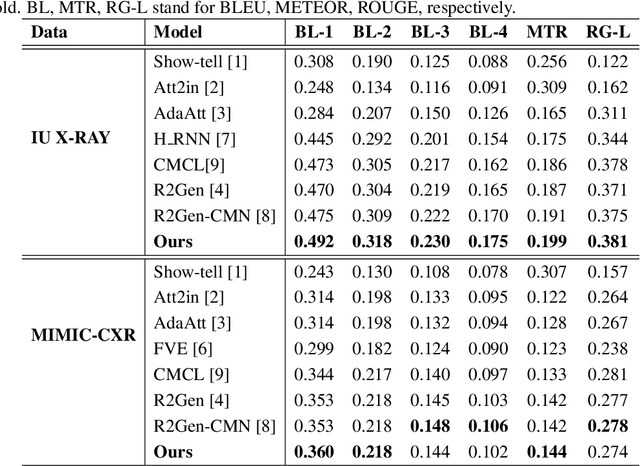

Automated Radiology report generation (RRG) aims at producing detailed descriptions of medical images, reducing radiologists' workload and improving access to high-quality diagnostic services. Existing encoder-decoder models only rely on visual features extracted from raw input images, which can limit the understanding of spatial structures and semantic relationships, often resulting in suboptimal text generation. To address this, we propose Anatomical Attention Alignment Network (A3Net), a framework that enhance visual-textual understanding by constructing hyper-visual representations. Our approach integrates a knowledge dictionary of anatomical structures with patch-level visual features, enabling the model to effectively associate image regions with their corresponding anatomical entities. This structured representation improves semantic reasoning, interpretability, and cross-modal alignment, ultimately enhancing the accuracy and clinical relevance of generated reports. Experimental results on IU X-Ray and MIMIC-CXR datasets demonstrate that A3Net significantly improves both visual perception and text generation quality. Our code is available at \href{https://github.com/Vinh-AI/A3Net}{GitHub}.
Latent Behavior Diffusion for Sequential Reaction Generation in Dyadic Setting
May 12, 2025The dyadic reaction generation task involves synthesizing responsive facial reactions that align closely with the behaviors of a conversational partner, enhancing the naturalness and effectiveness of human-like interaction simulations. This paper introduces a novel approach, the Latent Behavior Diffusion Model, comprising a context-aware autoencoder and a diffusion-based conditional generator that addresses the challenge of generating diverse and contextually relevant facial reactions from input speaker behaviors. The autoencoder compresses high-dimensional input features, capturing dynamic patterns in listener reactions while condensing complex input data into a concise latent representation, facilitating more expressive and contextually appropriate reaction synthesis. The diffusion-based conditional generator operates on the latent space generated by the autoencoder to predict realistic facial reactions in a non-autoregressive manner. This approach allows for generating diverse facial reactions that reflect subtle variations in conversational cues and emotional states. Experimental results demonstrate the effectiveness of our approach in achieving superior performance in dyadic reaction synthesis tasks compared to existing methods.
Conditional Diffusion Model for Longitudinal Medical Image Generation
Nov 07, 2024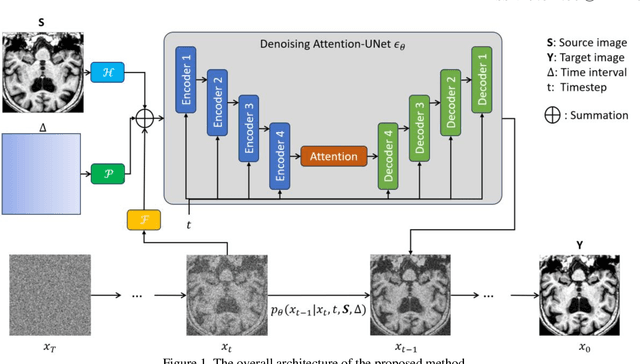
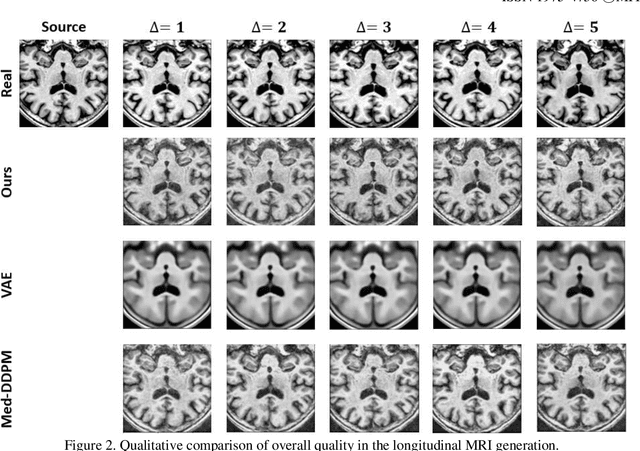
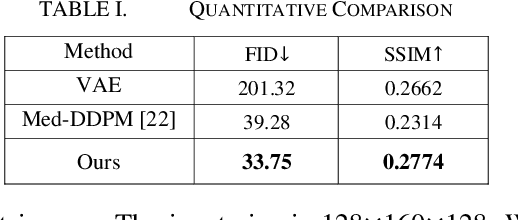
Alzheimers disease progresses slowly and involves complex interaction between various biological factors. Longitudinal medical imaging data can capture this progression over time. However, longitudinal data frequently encounter issues such as missing data due to patient dropouts, irregular follow-up intervals, and varying lengths of observation periods. To address these issues, we designed a diffusion-based model for 3D longitudinal medical imaging generation using single magnetic resonance imaging (MRI). This involves the injection of a conditioning MRI and time-visit encoding to the model, enabling control in change between source and target images. The experimental results indicate that the proposed method generates higher-quality images compared to other competing methods.
* 4 pages, 2 figures, conference
Transformer with Leveraged Masked Autoencoder for video-based Pain Assessment
Sep 08, 2024Accurate pain assessment is crucial in healthcare for effective diagnosis and treatment; however, traditional methods relying on self-reporting are inadequate for populations unable to communicate their pain. Cutting-edge AI is promising for supporting clinicians in pain recognition using facial video data. In this paper, we enhance pain recognition by employing facial video analysis within a Transformer-based deep learning model. By combining a powerful Masked Autoencoder with a Transformers-based classifier, our model effectively captures pain level indicators through both expressions and micro-expressions. We conducted our experiment on the AI4Pain dataset, which produced promising results that pave the way for innovative healthcare solutions that are both comprehensive and objective.
Leveraging WaveNet for Dynamic Listening Head Modeling from Speech
Sep 08, 2024



The creation of listener facial responses aims to simulate interactive communication feedback from a listener during a face-to-face conversation. Our goal is to generate believable videos of listeners' heads that respond authentically to a single speaker by a sequence-to-sequence model with an combination of WaveNet and Long short-term memory network. Our approach focuses on capturing the subtle nuances of listener feedback, ensuring the preservation of individual listener identity while expressing appropriate attitudes and viewpoints. Experiment results show that our method surpasses the baseline models on ViCo benchmark Dataset.
DCTM: Dilated Convolutional Transformer Model for Multimodal Engagement Estimation in Conversation
Jul 31, 2023



Conversational engagement estimation is posed as a regression problem, entailing the identification of the favorable attention and involvement of the participants in the conversation. This task arises as a crucial pursuit to gain insights into human's interaction dynamics and behavior patterns within a conversation. In this research, we introduce a dilated convolutional Transformer for modeling and estimating human engagement in the MULTIMEDIATE 2023 competition. Our proposed system surpasses the baseline models, exhibiting a noteworthy $7$\% improvement on test set and $4$\% on validation set. Moreover, we employ different modality fusion mechanism and show that for this type of data, a simple concatenated method with self-attention fusion gains the best performance.
Mental Workload Estimation with Electroencephalogram Signals by Combining Multi-Space Deep Models
Jul 23, 2023The human brain is in a continuous state of activity during both work and rest. Mental activity is a daily process, and when the brain is overworked, it can have negative effects on human health. In recent years, great attention has been paid to early detection of mental health problems because it can help prevent serious health problems and improve quality of life. Several signals are used to assess mental state, but the electroencephalogram (EEG) is widely used by researchers because of the large amount of information it provides about the brain. This paper aims to classify mental workload into three states and estimate continuum levels. Our method combines multiple dimensions of space to achieve the best results for mental estimation. In the time domain approach, we use Temporal Convolutional Networks, and in the frequency domain, we propose a new architecture called the Multi-Dimensional Residual Block, which combines residual blocks.
A transformer-based approach to video frame-level prediction in Affective Behaviour Analysis In-the-wild
Mar 19, 2023In recent years, transformer architecture has been a dominating paradigm in many applications, including affective computing. In this report, we propose our transformer-based model to handle Emotion Classification Task in the 5th Affective Behavior Analysis In-the-wild Competition. By leveraging the attentive model and the synthetic dataset, we attain a score of 0.4775 on the validation set of Aff-Wild2, the dataset provided by the organizer.
Generic Event Boundary Detection in Video with Pyramid Features
Jan 11, 2023



Generic event boundary detection (GEBD) aims to split video into chunks at a broad and diverse set of actions as humans naturally perceive event boundaries. In this study, we present an approach that considers the correlation between neighbor frames with pyramid feature maps in both spatial and temporal dimensions to construct a framework for localizing generic events in video. The features at multiple spatial dimensions of a pre-trained ResNet-50 are exploited with different views in the temporal dimension to form a temporal pyramid feature map. Based on that, the similarity between neighbor frames is calculated and projected to build a temporal pyramid similarity feature vector. A decoder with 1D convolution operations is used to decode these similarities to a new representation that incorporates their temporal relationship for later boundary score estimation. Extensive experiments conducted on the GEBD benchmark dataset show the effectiveness of our system and its variations, in which we outperformed the state-of-the-art approaches. Additional experiments on TAPOS dataset, which contains long-form videos with Olympic sport actions, demonstrated the effectiveness of our study compared to others.
Fine-tuning Wav2vec for Vocal-burst Emotion Recognition
Oct 01, 2022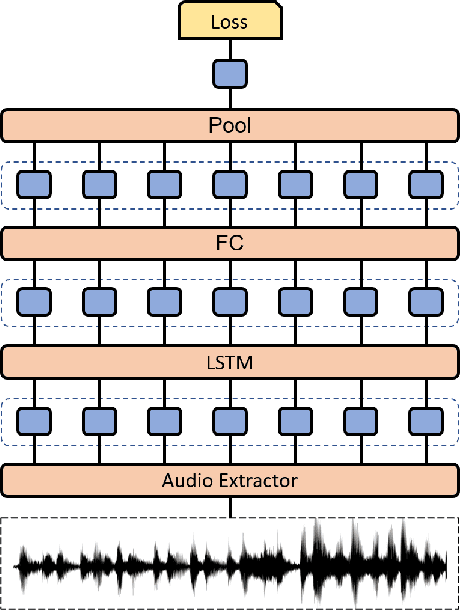
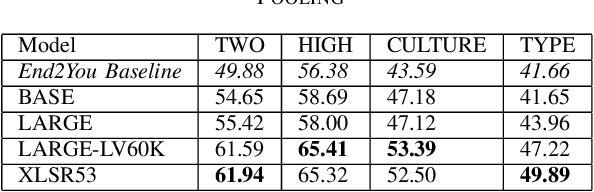
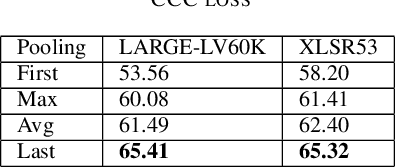
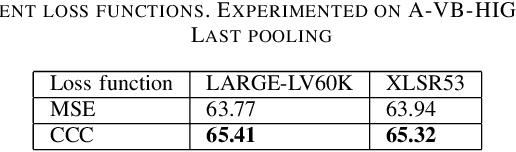
The ACII Affective Vocal Bursts (A-VB) competition introduces a new topic in affective computing, which is understanding emotional expression using the non-verbal sound of humans. We are familiar with emotion recognition via verbal vocal or facial expression. However, the vocal bursts such as laughs, cries, and signs, are not exploited even though they are very informative for behavior analysis. The A-VB competition comprises four tasks that explore non-verbal information in different spaces. This technical report describes the method and the result of SclabCNU Team for the tasks of the challenge. We achieved promising results compared to the baseline model provided by the organizers.