 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Wav2vec for Vocal-burst Emotion Recognition
Oct 01, 2022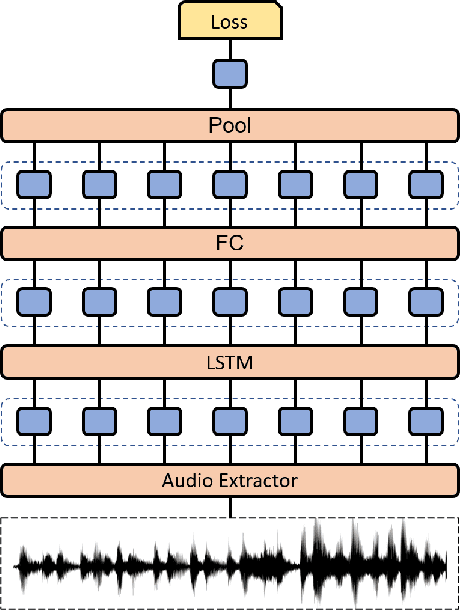
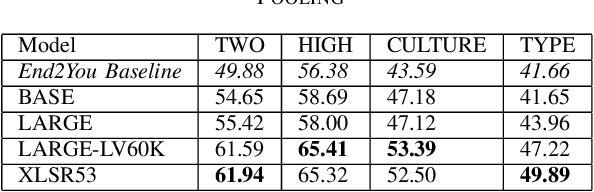
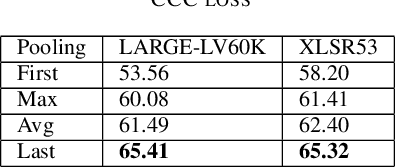
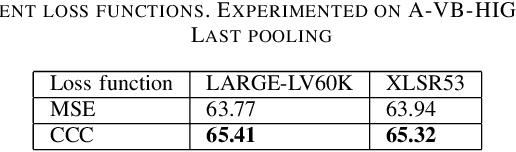
The ACII Affective Vocal Bursts (A-VB) competition introduces a new topic in affective computing, which is understanding emotional expression using the non-verbal sound of humans. We are familiar with emotion recognition via verbal vocal or facial expression. However, the vocal bursts such as laughs, cries, and signs, are not exploited even though they are very informative for behavior analysis. The A-VB competition comprises four tasks that explore non-verbal information in different spaces. This technical report describes the method and the result of SclabCNU Team for the tasks of the challenge. We achieved promising results compared to the baseline model provided by the organizers.
Multi-task Cross Attention Network in Facial Behavior Analysis
Jul 21, 2022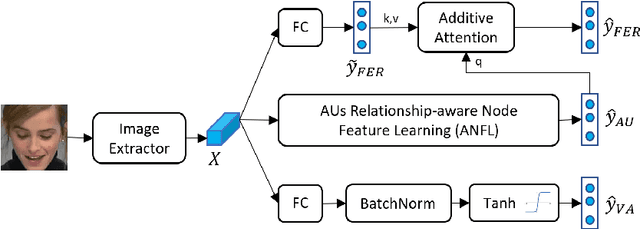

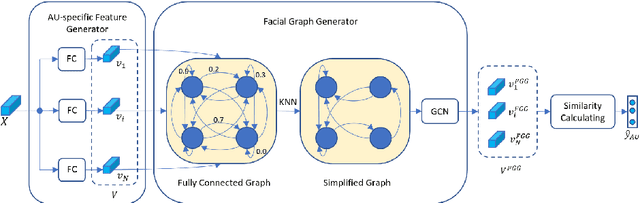
Facial behavior analysis is a broad topic with various categories such as facial emotion recognition, age and gender recognition, ... Many studies focus on individual tasks while the multi-task learning approach is still open and requires more research. In this paper, we present our solution and experiment result for the Multi-Task Learning challenge of the Affective Behavior Analysis in-the-wild competition. The challenge is a combination of three tasks: action unit detection, facial expression recognition and valance-arousal estimation. To address this challenge, we introduce a cross-attentive module to improve multi-task learning performance. Additionally, a facial graph is applied to capture the association among action units. As a result, we achieve the evaluation measure of 1.24 on the validation data provided by the organizers, which is better than the baseline result of 0.30.
An Attention-based Method for Action Unit Detection at the 3rd ABAW Competition
Mar 23, 2022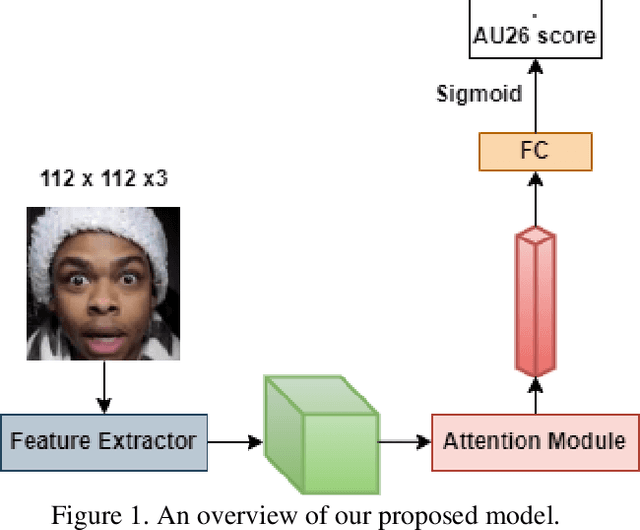
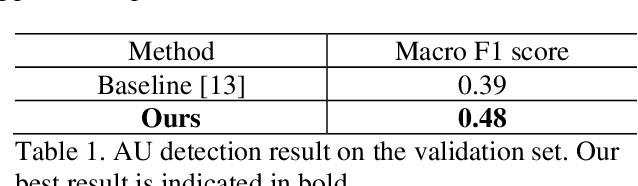
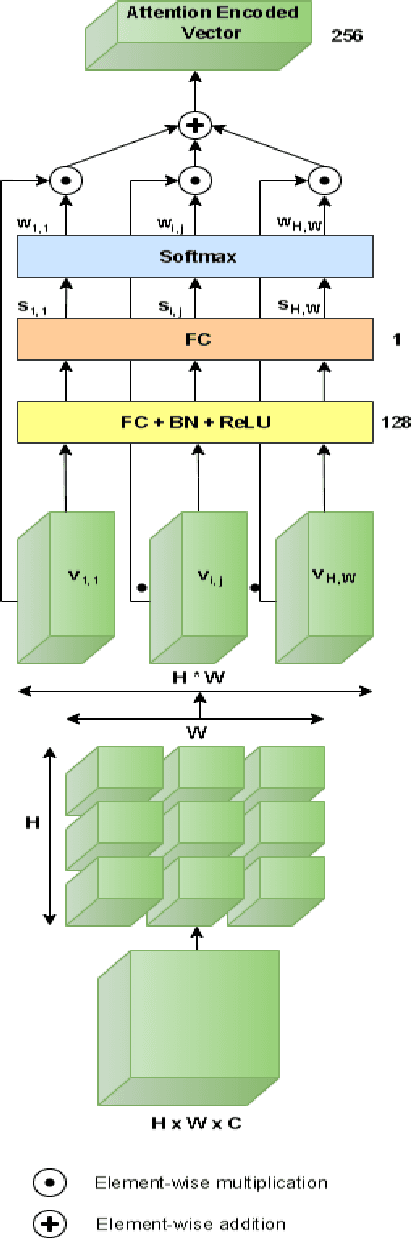
Facial Action Coding System is an approach for modeling the complexity of human emotional expression. Automatic action unit (AU) detection is a crucial research area in human-computer interaction. This paper describes our submission to the third Affective Behavior Analysis in-the-wild (ABAW) competition 2022. We proposed a method for detecting facial action units in the video. At the first stage, a lightweight CNN-based feature extractor is employed to extract the feature map from each video frame. Then, an attention module is applied to refine the attention map. The attention encoded vector is derived using a weighted sum of the feature map and the attention scores later. Finally, the sigmoid function is used at the output layer to make the prediction suitable for multi-label AUs detection. We achieved a macro F1 score of 0.48 on the ABAW challenge validation set compared to 0.39 from the baseline model.
Temporal Convolution Networks with Positional Encoding for Evoked Expression Estimation
Jun 16, 2021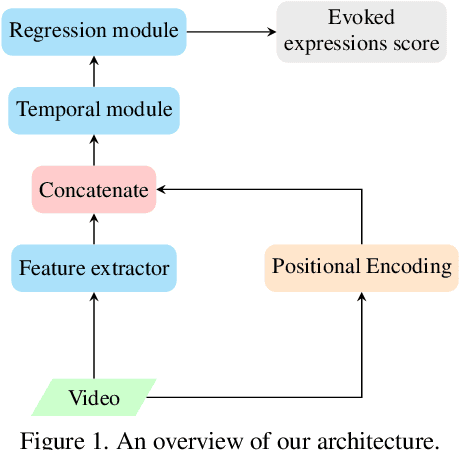
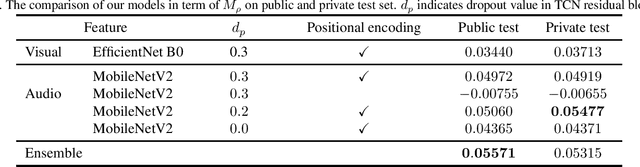
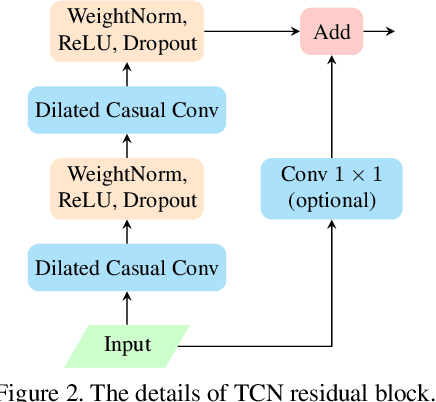
This paper presents an approach for Evoked Expressions from Videos (EEV) challenge, which aims to predict evoked facial expressions from video. We take advantage of pre-trained models on large-scale datasets in computer vision and audio signals to extract the deep representation of timestamps in the video. A temporal convolution network, rather than an RNN like architecture, is used to explore temporal relationships due to its advantage in memory consumption and parallelism. Furthermore, to address the missing annotations of some timestamps, positional encoding is employed to ensure continuity of input data when discarding these timestamps during training. We achieved state-of-the-art results on the EEV challenge with a Pearson correlation coefficient of 0.05477, the first ranked performance in the EEV 2021 challenge.