 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Convolution Networks with Positional Encoding for Evoked Expression Estimation
Jun 16, 2021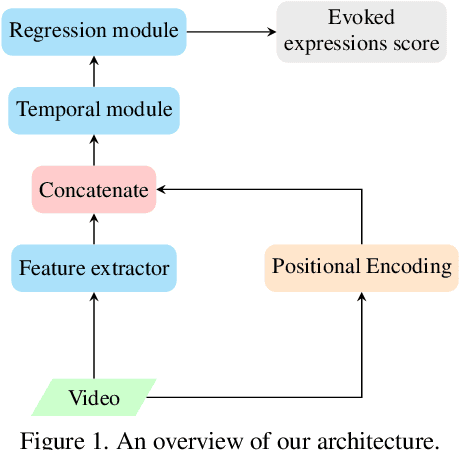
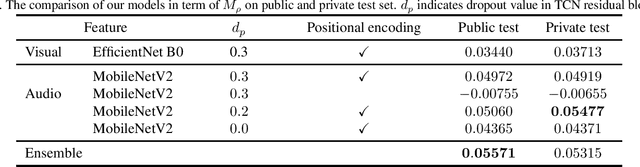
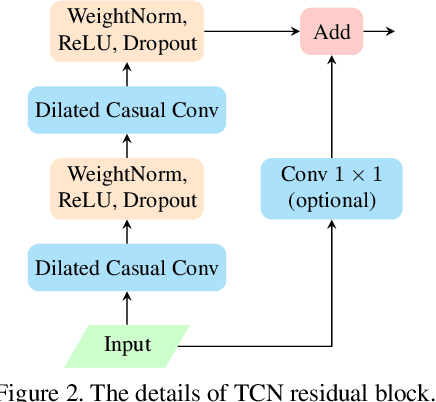
This paper presents an approach for Evoked Expressions from Videos (EEV) challenge, which aims to predict evoked facial expressions from video. We take advantage of pre-trained models on large-scale datasets in computer vision and audio signals to extract the deep representation of timestamps in the video. A temporal convolution network, rather than an RNN like architecture, is used to explore temporal relationships due to its advantage in memory consumption and parallelism. Furthermore, to address the missing annotations of some timestamps, positional encoding is employed to ensure continuity of input data when discarding these timestamps during training. We achieved state-of-the-art results on the EEV challenge with a Pearson correlation coefficient of 0.05477, the first ranked performance in the EEV 2021 challenge.