 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLG-LSQ: Learned Gradient Linear Symmetric Quantization
Feb 18, 2022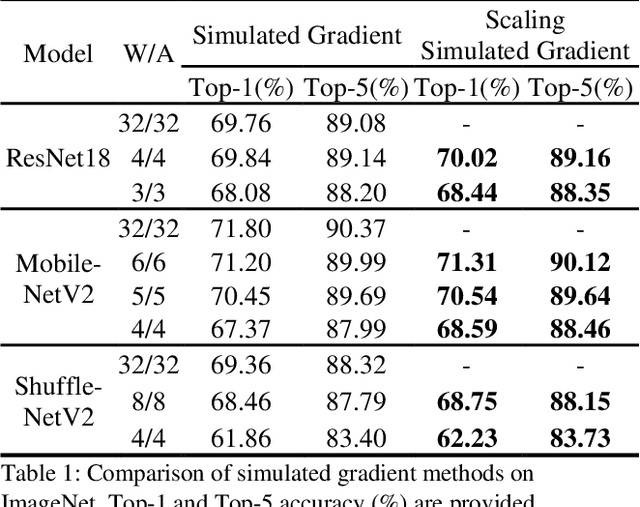
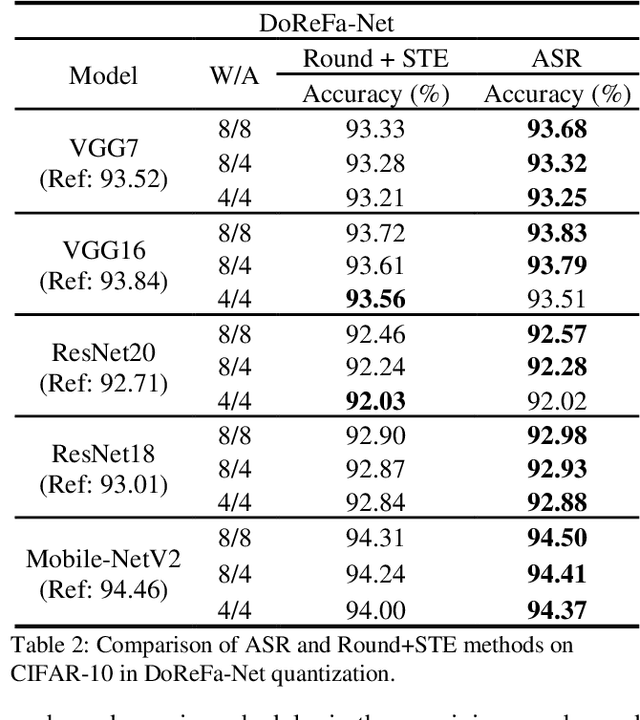
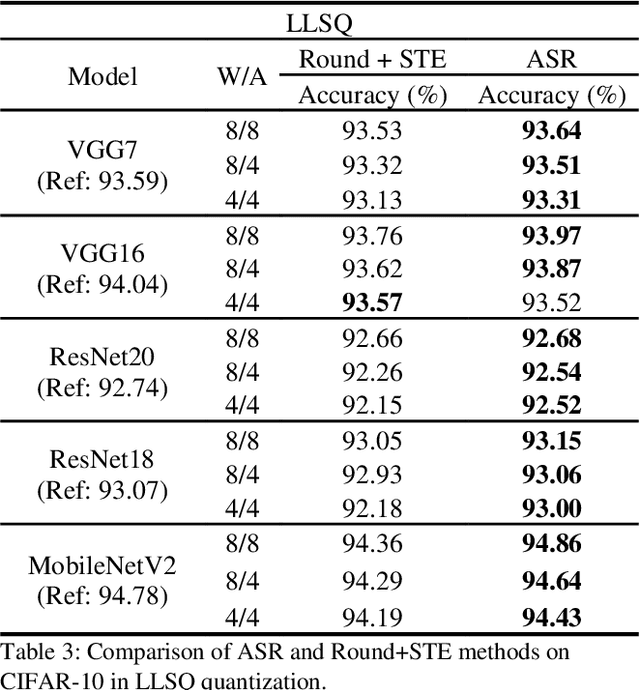
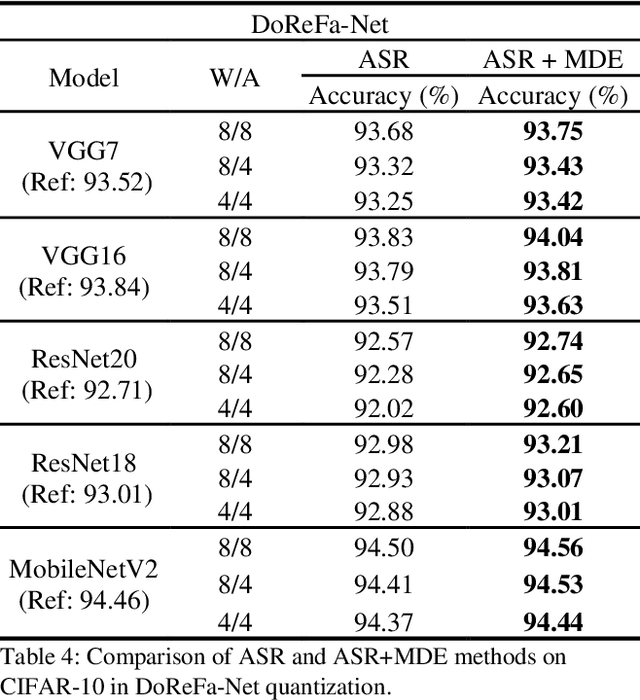
Deep neural networks with lower precision weights and operations at inference time have advantages in terms of the cost of memory space and accelerator power. The main challenge associated with the quantization algorithm is maintaining accuracy at low bit-widths. We propose learned gradient linear symmetric quantization (LG-LSQ) as a method for quantizing weights and activation functions to low bit-widths with high accuracy in integer neural network processors. First, we introduce the scaling simulated gradient (SSG) method for determining the appropriate gradient for the scaling factor of the linear quantizer during the training process. Second, we introduce the arctangent soft round (ASR) method, which differs from the straight-through estimator (STE) method in its ability to prevent the gradient from becoming zero, thereby solving the discrete problem caused by the rounding process. Finally, to bridge the gap between full-precision and low-bit quantization networks, we propose the minimize discretization error (MDE) method to determine an accurate gradient in backpropagation. The ASR+MDE method is a simple alternative to the STE method and is practical for use in different uniform quantization methods. In our evaluation, the proposed quantizer achieved full-precision baseline accuracy in various 3-bit networks, including ResNet18, ResNet34, and ResNet50, and an accuracy drop of less than 1% in the quantization of 4-bit weights and 4-bit activations in lightweight models such as MobileNetV2 and ShuffleNetV2.
Conditional Generation of Temporally-ordered Event Sequences
Dec 31, 2020
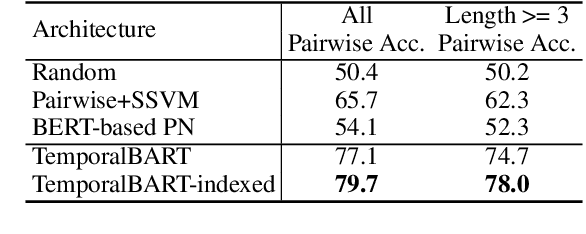
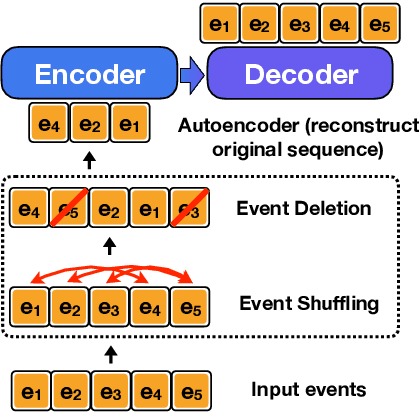

Models encapsulating narrative schema knowledge have proven to be useful for a range of event-related tasks, but these models typically do not engage with temporal relationships between events. We present a a BART-based conditional generation model capable of capturing event cooccurrence as well as temporality of event sequences. This single model can address both temporal ordering, sorting a given sequence of events into the order they occurred, and event infilling, predicting new events which fit into a temporally-ordered sequence of existing ones. Our model is trained as a denoising autoencoder: we take temporally-ordered event sequences, shuffle them, delete some events, and then attempting to recover the original event sequence. In this fashion, the model learns to make inferences given incomplete knowledge about the events in an underlying scenario. On the temporal ordering task, we show that our model is able to unscramble event sequences from existing datasets without access to explicitly labeled temporal training data, outperforming both a BERT-based pairwise model and a BERT-based pointer network. On event infilling, human evaluation shows that our model is able to generate events that fit better temporally into the input events when compared to GPT-2 story completion models.
ReadOnce Transformers: Reusable Representations of Text for Transformers
Oct 24, 2020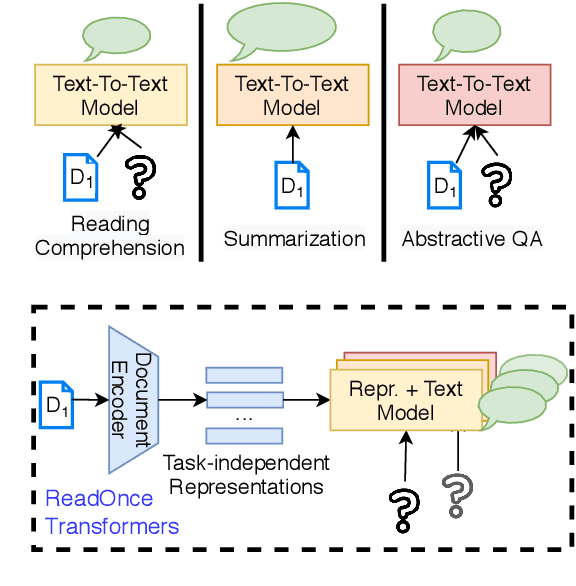
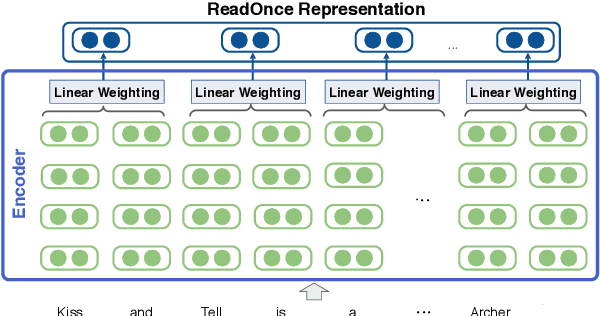
While large-scale language models are extremely effective when directly fine-tuned on many end-tasks, such models learn to extract information and solve the task simultaneously from end-task supervision. This is wasteful, as the general problem of gathering information from a document is mostly task-independent and need not be re-learned from scratch each time. Moreover, once the information has been captured in a computable representation, it can now be re-used across examples, leading to faster training and evaluation of models. We present a transformer-based approach, ReadOnce Transformers, that is trained to build such information-capturing representations of text. Our model compresses the document into a variable-length task-independent representation that can now be re-used in different examples and tasks, thereby requiring a document to only be read once. Additionally, we extend standard text-to-text models to consume our ReadOnce Representations along with text to solve multiple downstream tasks. We show our task-independent representations can be used for multi-hop QA, abstractive QA, and summarization. We observe 2x-5x speedups compared to standard text-to-text models, while also being able to handle long documents that would normally exceed the length limit of current models.
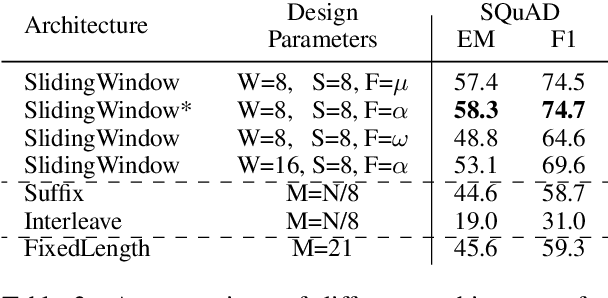
Tradeoffs in Sentence Selection Techniques for Open-Domain Question Answering
Sep 18, 2020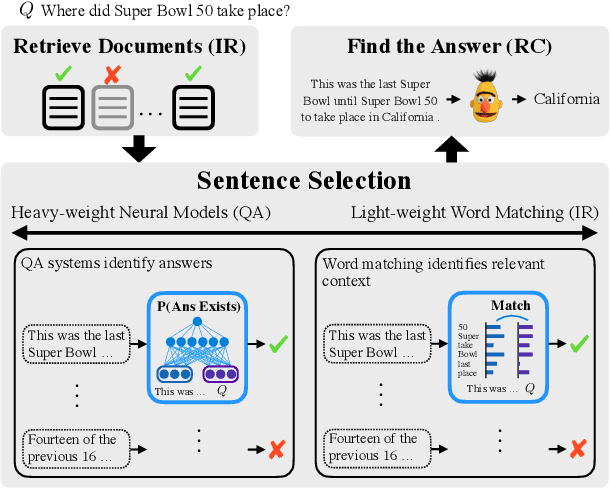
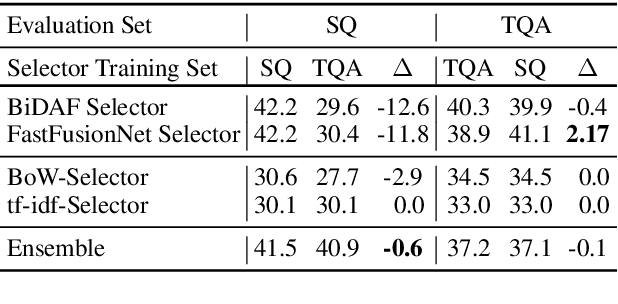
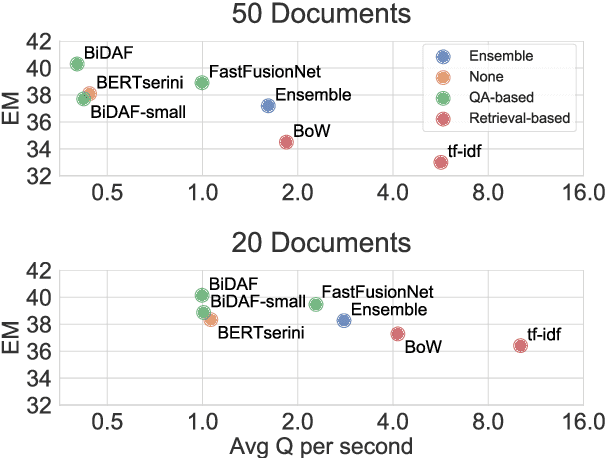
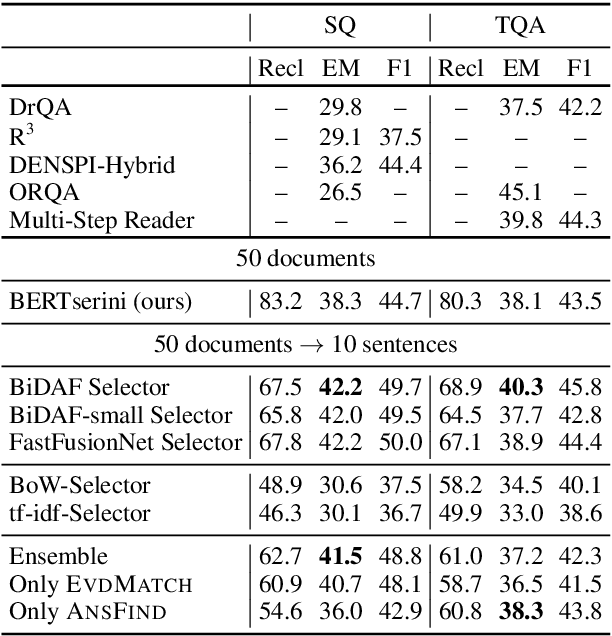
Current methods in open-domain question answering (QA) usually employ a pipeline of first retrieving relevant documents, then applying strong reading comprehension (RC) models to that retrieved text. However, modern RC models are complex and expensive to run, so techniques to prune the space of retrieved text are critical to allow this approach to scale. In this paper, we focus on approaches which apply an intermediate sentence selection step to address this issue, and investigate the best practices for this approach. We describe two groups of models for sentence selection: QA-based approaches, which run a full-fledged QA system to identify answer candidates, and retrieval-based models, which find parts of each passage specifically related to each question. We examine trade-offs between processing speed and task performance in these two approaches, and demonstrate an ensemble module that represents a hybrid of the two. From experiments on Open-SQuAD and TriviaQA, we show that very lightweight QA models can do well at this task, but retrieval-based models are faster still. An ensemble module we describe balances between the two and generalizes well cross-domain.