 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLG-LSQ: Learned Gradient Linear Symmetric Quantization
Feb 18, 2022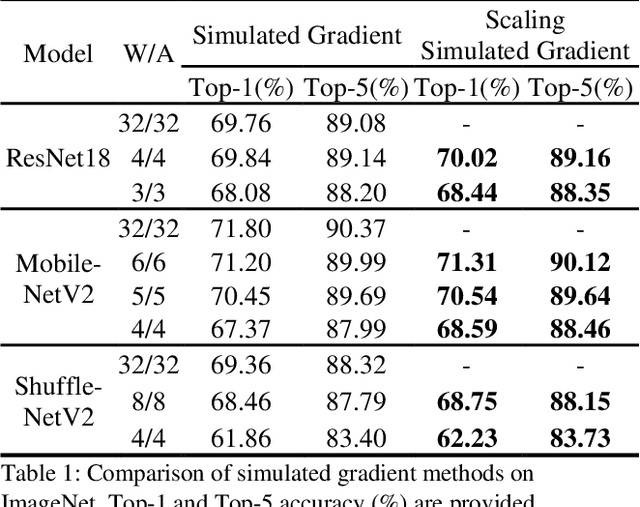
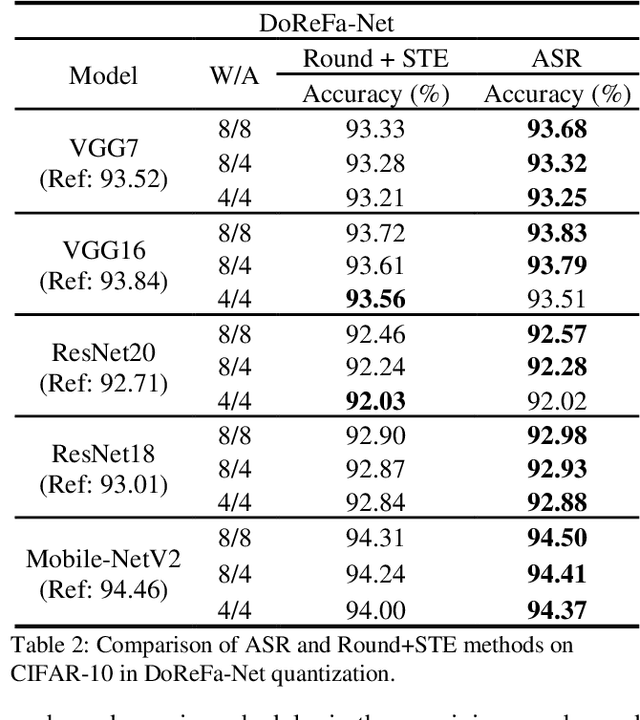
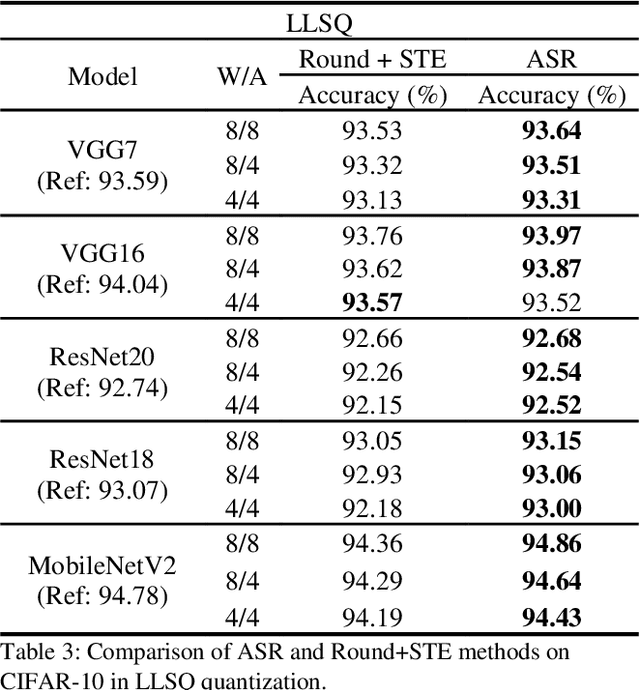
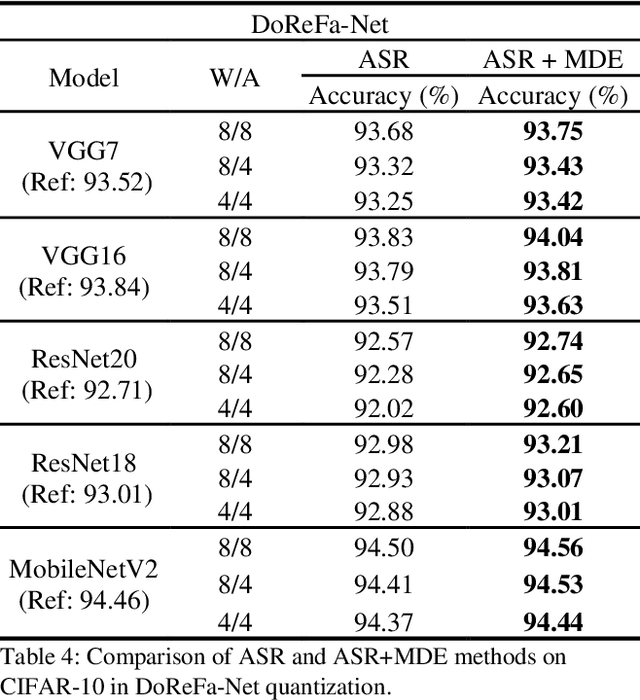
Deep neural networks with lower precision weights and operations at inference time have advantages in terms of the cost of memory space and accelerator power. The main challenge associated with the quantization algorithm is maintaining accuracy at low bit-widths. We propose learned gradient linear symmetric quantization (LG-LSQ) as a method for quantizing weights and activation functions to low bit-widths with high accuracy in integer neural network processors. First, we introduce the scaling simulated gradient (SSG) method for determining the appropriate gradient for the scaling factor of the linear quantizer during the training process. Second, we introduce the arctangent soft round (ASR) method, which differs from the straight-through estimator (STE) method in its ability to prevent the gradient from becoming zero, thereby solving the discrete problem caused by the rounding process. Finally, to bridge the gap between full-precision and low-bit quantization networks, we propose the minimize discretization error (MDE) method to determine an accurate gradient in backpropagation. The ASR+MDE method is a simple alternative to the STE method and is practical for use in different uniform quantization methods. In our evaluation, the proposed quantizer achieved full-precision baseline accuracy in various 3-bit networks, including ResNet18, ResNet34, and ResNet50, and an accuracy drop of less than 1% in the quantization of 4-bit weights and 4-bit activations in lightweight models such as MobileNetV2 and ShuffleNetV2.