 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLG-LSQ: Learned Gradient Linear Symmetric Quantization
Feb 18, 2022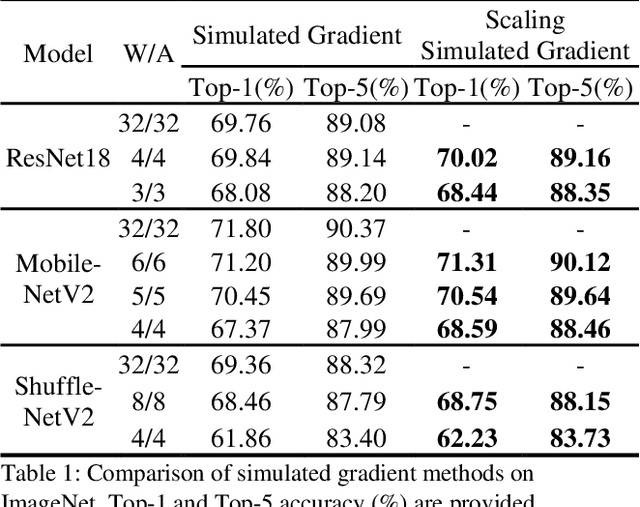
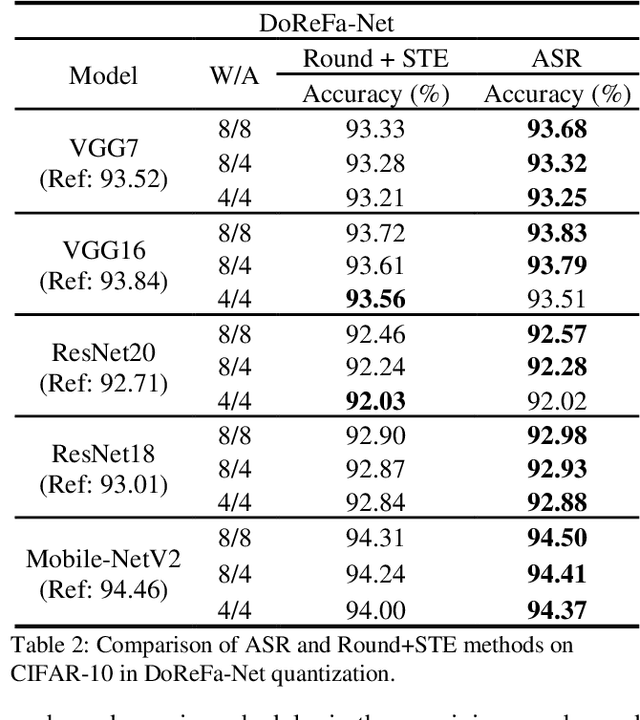
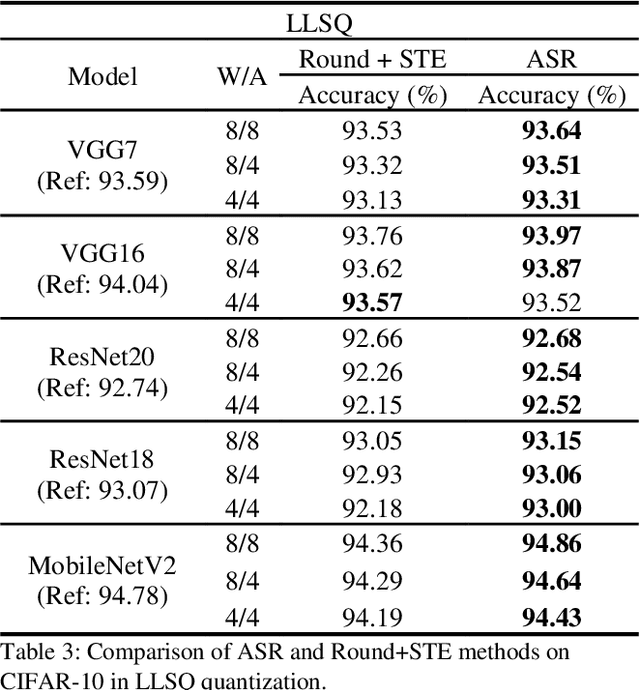
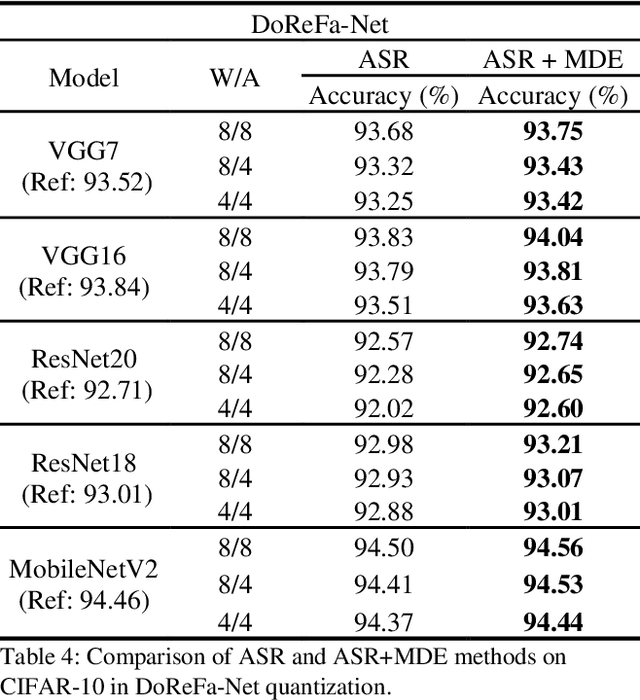
Deep neural networks with lower precision weights and operations at inference time have advantages in terms of the cost of memory space and accelerator power. The main challenge associated with the quantization algorithm is maintaining accuracy at low bit-widths. We propose learned gradient linear symmetric quantization (LG-LSQ) as a method for quantizing weights and activation functions to low bit-widths with high accuracy in integer neural network processors. First, we introduce the scaling simulated gradient (SSG) method for determining the appropriate gradient for the scaling factor of the linear quantizer during the training process. Second, we introduce the arctangent soft round (ASR) method, which differs from the straight-through estimator (STE) method in its ability to prevent the gradient from becoming zero, thereby solving the discrete problem caused by the rounding process. Finally, to bridge the gap between full-precision and low-bit quantization networks, we propose the minimize discretization error (MDE) method to determine an accurate gradient in backpropagation. The ASR+MDE method is a simple alternative to the STE method and is practical for use in different uniform quantization methods. In our evaluation, the proposed quantizer achieved full-precision baseline accuracy in various 3-bit networks, including ResNet18, ResNet34, and ResNet50, and an accuracy drop of less than 1% in the quantization of 4-bit weights and 4-bit activations in lightweight models such as MobileNetV2 and ShuffleNetV2.
POPPINS : A Population-Based Digital Spiking Neuromorphic Processor with Integer Quadratic Integrate-and-Fire Neurons
Jan 19, 2022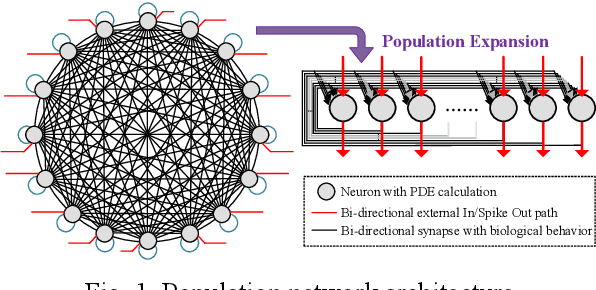
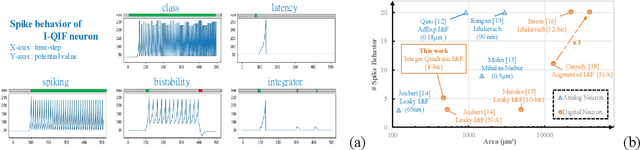
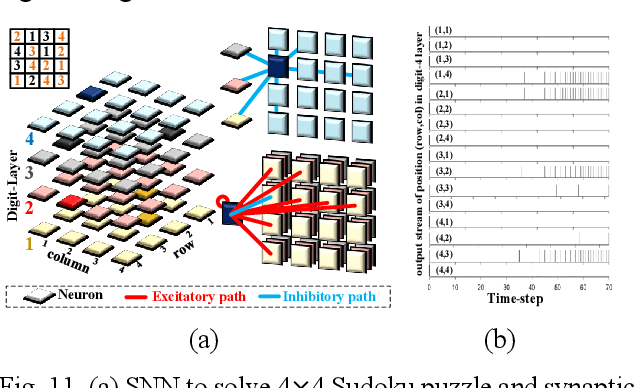
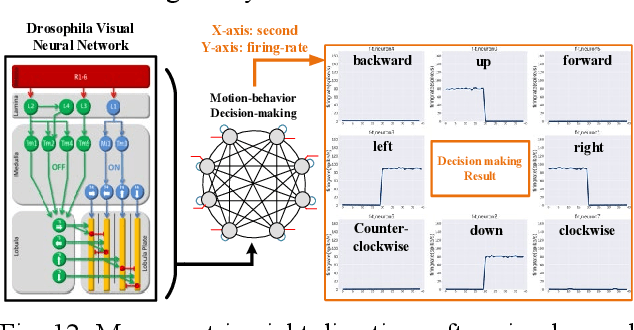
The inner operations of the human brain as a biological processing system remain largely a mystery. Inspired by the function of the human brain and based on the analysis of simple neural network systems in other species, such as Drosophila, neuromorphic computing systems have attracted considerable interest. In cellular-level connectomics research, we can identify the characteristics of biological neural network, called population, which constitute not only recurrent fullyconnection in network, also an external-stimulus and selfconnection in each neuron. Relying on low data bandwidth of spike transmission in network and input data, Spiking Neural Networks exhibit low-latency and low-power design. In this study, we proposed a configurable population-based digital spiking neuromorphic processor in 180nm process technology with two configurable hierarchy populations. Also, these neurons in the processor can be configured as novel models, integer quadratic integrate-and-fire neuron models, which contain an unsigned 8-bit membrane potential value. The processor can implement intelligent decision making for avoidance in real-time. Moreover, the proposed approach enables the developments of biomimetic neuromorphic system and various low-power, and low-latency inference processing applications.
MARS: Multi-macro Architecture SRAM CIM-Based Accelerator with Co-designed Compressed Neural Networks
Oct 24, 2020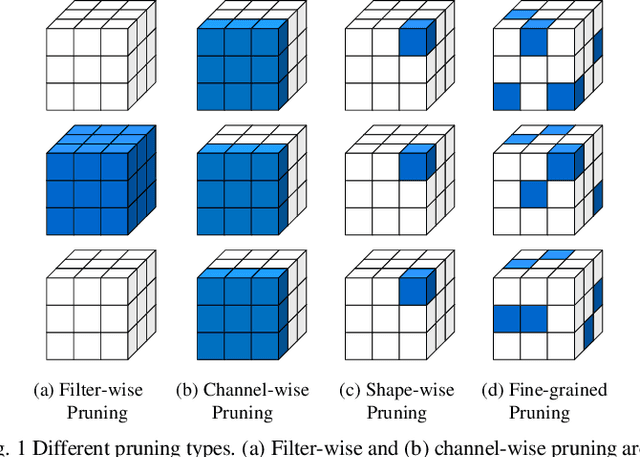
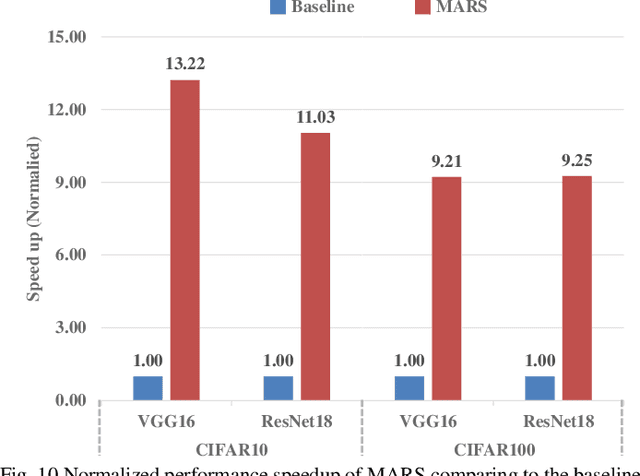
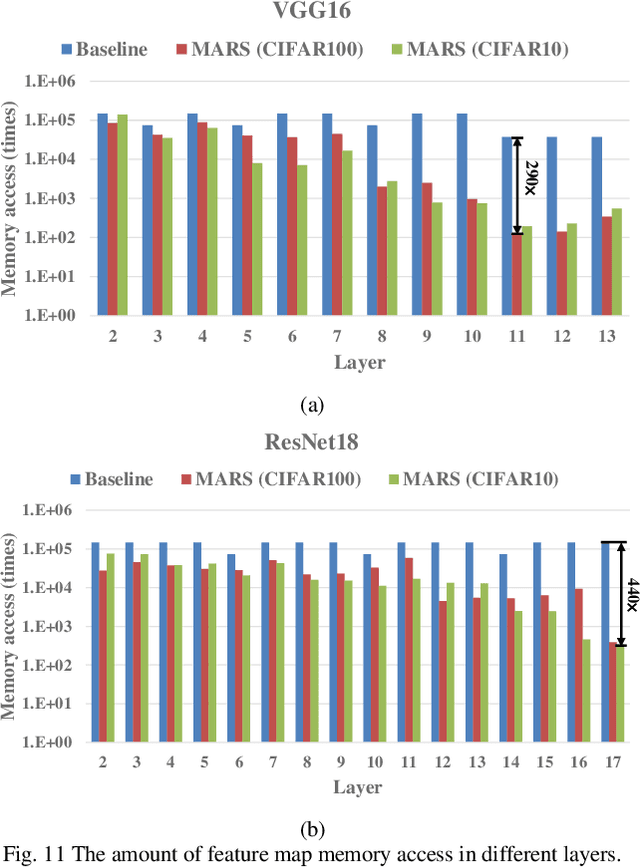
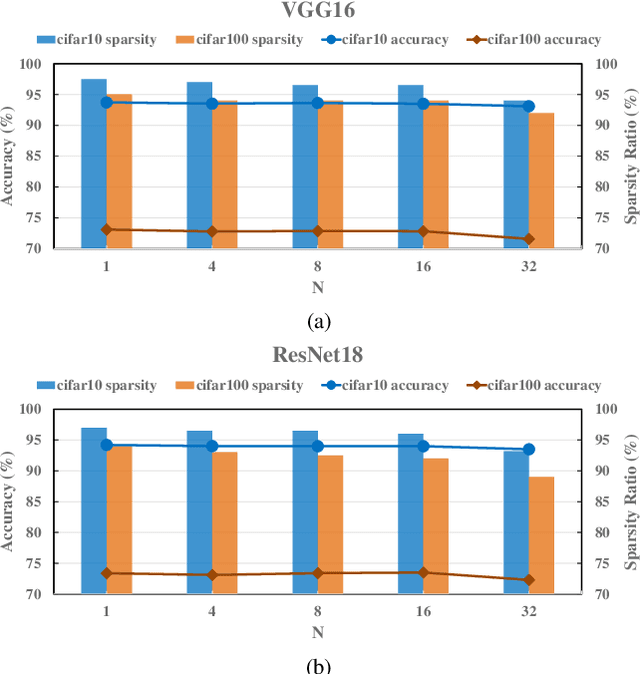
Convolutional neural networks (CNNs) play a key role in deep learning applications. However, the large storage overheads and the substantial computation cost of CNNs are problematic in hardware accelerators. Computing-in-memory (CIM) architecture has demonstrated great potential to effectively compute large-scale matrix-vector multiplication. However, the intensive multiply and accumulation (MAC) operations executed at the crossbar array and the limited capacity of CIM macros remain bottlenecks for further improvement of energy efficiency and throughput. To reduce computation costs, network pruning and quantization are two widely studied compression methods to shrink the model size. However, most of the model compression algorithms can only be implemented in digital-based CNN accelerators. For implementation in a static random access memory (SRAM) CIM-based accelerator, the model compression algorithm must consider the hardware limitations of CIM macros, such as the number of word lines and bit lines that can be turned on at the same time, as well as how to map the weight to the SRAM CIM macro. In this study, a software and hardware co-design approach is proposed to design an SRAM CIM-based CNN accelerator and an SRAM CIM-aware model compression algorithm. To lessen the high-precision MAC required by batch normalization (BN), a quantization algorithm that can fuse BN into the weights is proposed. Furthermore, to reduce the number of network parameters, a sparsity algorithm that considers a CIM architecture is proposed. Last, MARS, a CIM-based CNN accelerator that can utilize multiple SRAM CIM macros as processing units and support a sparsity neural network, is proposed.