 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Multi-macro Architecture SRAM CIM-Based Accelerator with Co-designed Compressed Neural Networks
Paper and Code
Oct 24, 2020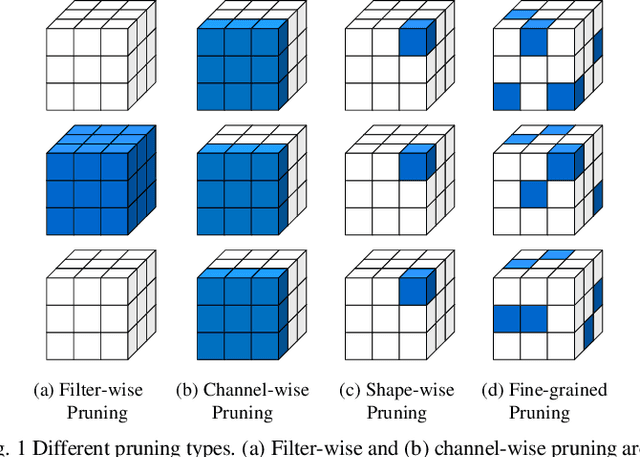
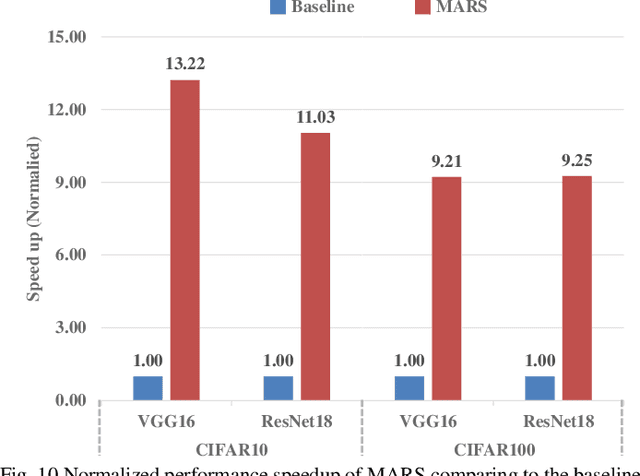
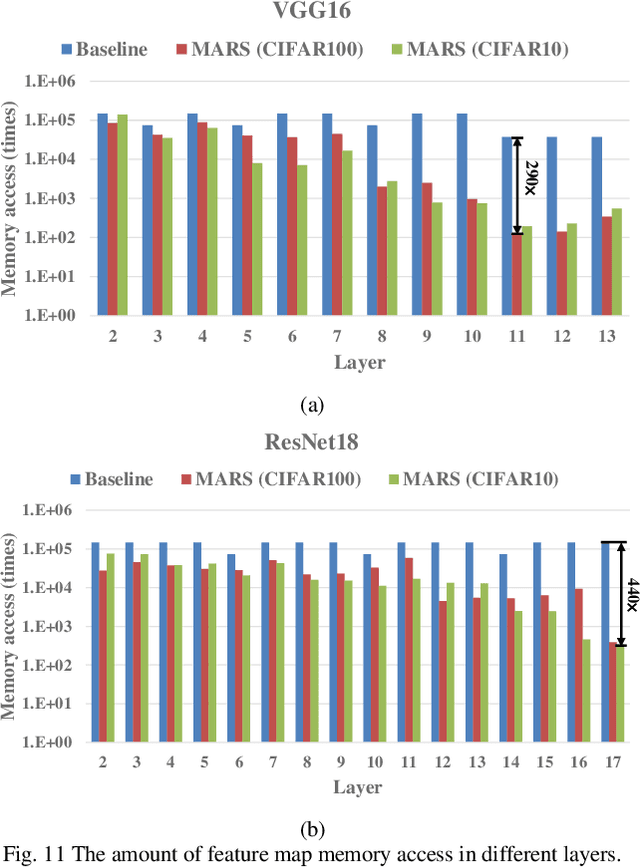
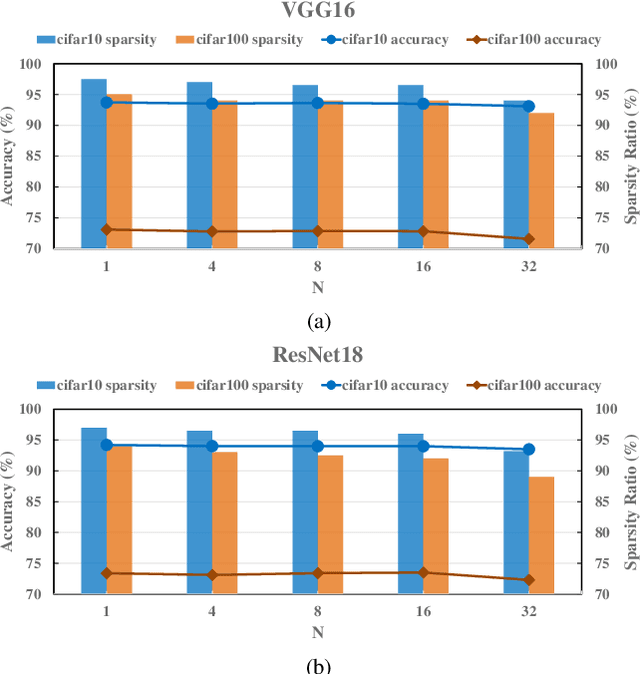
Convolutional neural networks (CNNs) play a key role in deep learning applications. However, the large storage overheads and the substantial computation cost of CNNs are problematic in hardware accelerators. Computing-in-memory (CIM) architecture has demonstrated great potential to effectively compute large-scale matrix-vector multiplication. However, the intensive multiply and accumulation (MAC) operations executed at the crossbar array and the limited capacity of CIM macros remain bottlenecks for further improvement of energy efficiency and throughput. To reduce computation costs, network pruning and quantization are two widely studied compression methods to shrink the model size. However, most of the model compression algorithms can only be implemented in digital-based CNN accelerators. For implementation in a static random access memory (SRAM) CIM-based accelerator, the model compression algorithm must consider the hardware limitations of CIM macros, such as the number of word lines and bit lines that can be turned on at the same time, as well as how to map the weight to the SRAM CIM macro. In this study, a software and hardware co-design approach is proposed to design an SRAM CIM-based CNN accelerator and an SRAM CIM-aware model compression algorithm. To lessen the high-precision MAC required by batch normalization (BN), a quantization algorithm that can fuse BN into the weights is proposed. Furthermore, to reduce the number of network parameters, a sparsity algorithm that considers a CIM architecture is proposed. Last, MARS, a CIM-based CNN accelerator that can utilize multiple SRAM CIM macros as processing units and support a sparsity neural network, is proposed.