 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReadOnce Transformers: Reusable Representations of Text for Transformers
Paper and Code
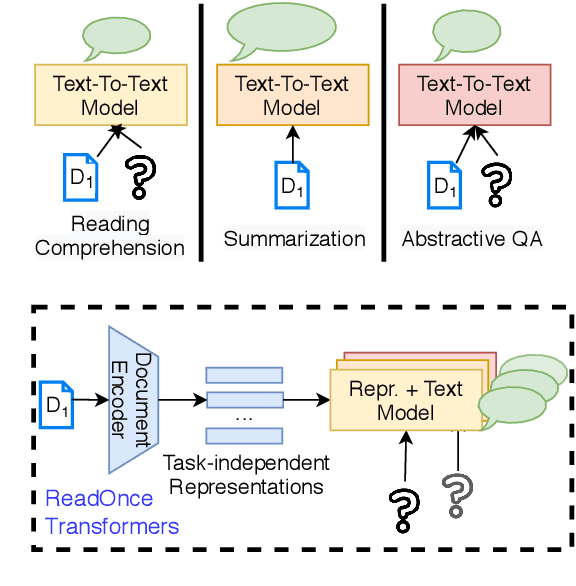
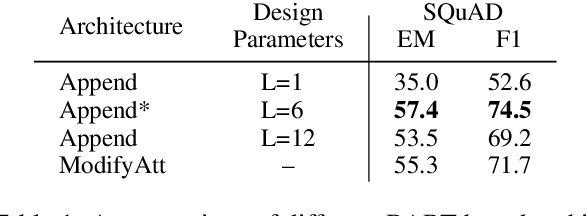
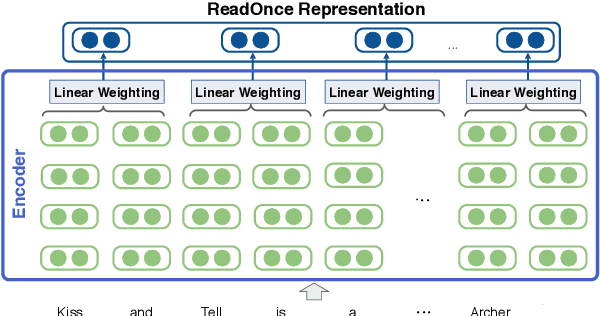
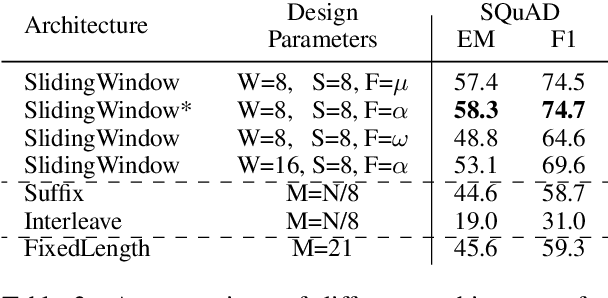
While large-scale language models are extremely effective when directly fine-tuned on many end-tasks, such models learn to extract information and solve the task simultaneously from end-task supervision. This is wasteful, as the general problem of gathering information from a document is mostly task-independent and need not be re-learned from scratch each time. Moreover, once the information has been captured in a computable representation, it can now be re-used across examples, leading to faster training and evaluation of models. We present a transformer-based approach, ReadOnce Transformers, that is trained to build such information-capturing representations of text. Our model compresses the document into a variable-length task-independent representation that can now be re-used in different examples and tasks, thereby requiring a document to only be read once. Additionally, we extend standard text-to-text models to consume our ReadOnce Representations along with text to solve multiple downstream tasks. We show our task-independent representations can be used for multi-hop QA, abstractive QA, and summarization. We observe 2x-5x speedups compared to standard text-to-text models, while also being able to handle long documents that would normally exceed the length limit of current models.