 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSandboxAQ's submission to MRL 2024 Shared Task on Multi-lingual Multi-task Information Retrieval
Paper and Code
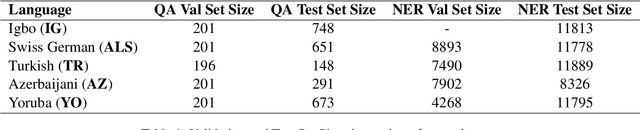
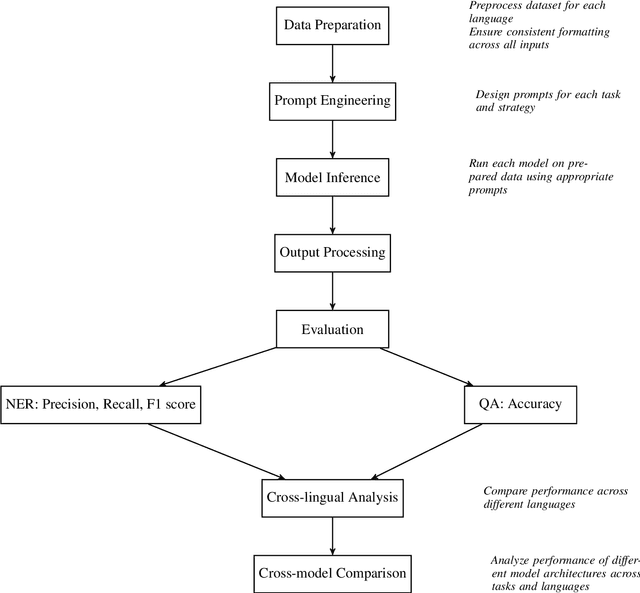
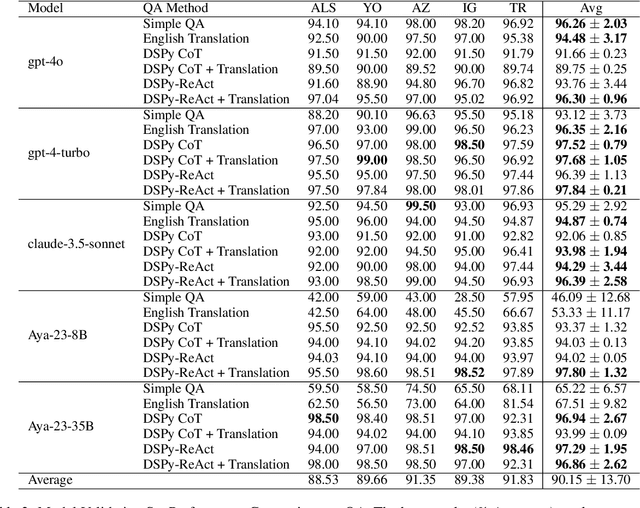
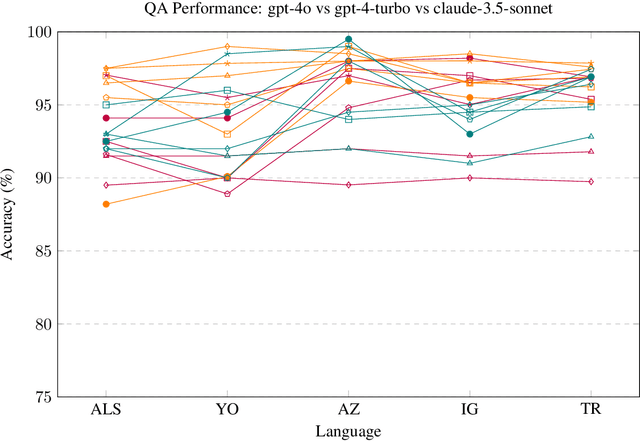
This paper explores the problems of Question Answering (QA) and Named Entity Recognition (NER) in five diverse languages. We tested five Large Language Models with various prompting methods, including zero-shot, chain-of-thought reasoning, and translation techniques. Our results show that while some models consistently outperform others, their effectiveness varies significantly across tasks and languages. We saw that advanced prompting techniques generally improved QA performance but had mixed results for NER; and we observed that language difficulty patterns differed between tasks. Our findings highlight the need for task-specific approaches in multilingual NLP and suggest that current models may develop different linguistic competencies for different tasks.