 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Robust Language Model Generation via Content Integrity Preservation
Jan 14, 2026Large Language Model (LLM) outputs often vary across user sociodemographic attributes, leading to disparities in factual accuracy, utility, and safety, even for objective questions where demographic information is irrelevant. Unlike prior work on stereotypical or representational bias, this paper studies identity-dependent degradation of core response quality. We show empirically that such degradation arises from biased generation behavior, despite factual knowledge being robustly encoded across identities. Motivated by this mismatch, we propose a lightweight, training-free framework for identity-robust generation that selectively neutralizes non-critical identity information while preserving semantically essential attributes, thus maintaining output content integrity. Experiments across four benchmarks and 18 sociodemographic identities demonstrate an average 77% reduction in identity-dependent bias compared to vanilla prompting and a 45% reduction relative to prompt-based defenses. Our work addresses a critical gap in mitigating the impact of user identity cues in prompts on core generation quality.
Disambiguation in Conversational Question Answering in the Era of LLM: A Survey
May 18, 2025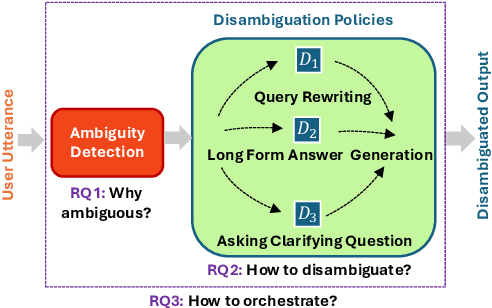
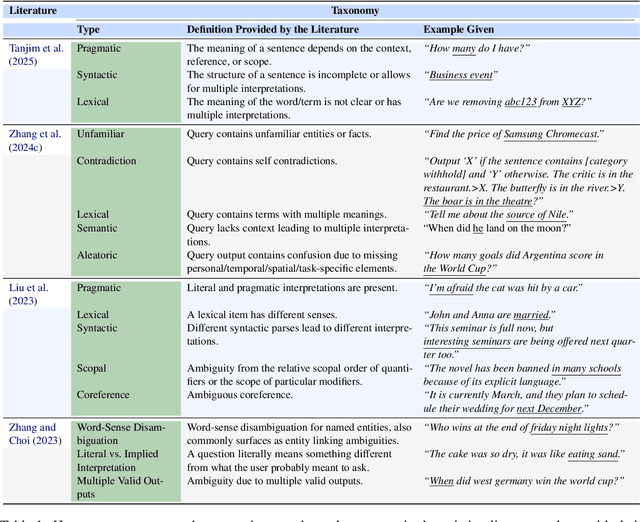
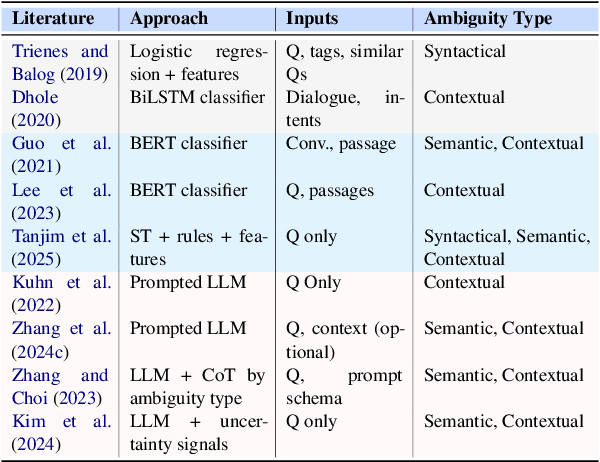
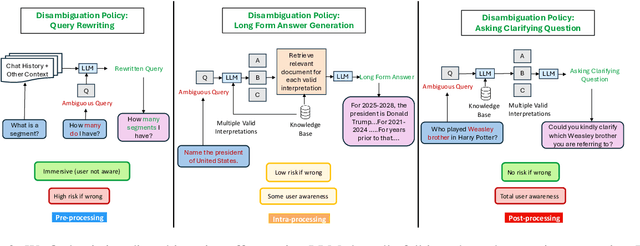
Ambiguity remains a fundamental challenge in Natural Language Processing (NLP) due to the inherent complexity and flexibility of human language. With the advent of Large Language Models (LLMs), addressing ambiguity has become even more critical due to their expanded capabilities and applications. In the context of Conversational Question Answering (CQA), this paper explores the definition, forms, and implications of ambiguity for language driven systems, particularly in the context of LLMs. We define key terms and concepts, categorize various disambiguation approaches enabled by LLMs, and provide a comparative analysis of their advantages and disadvantages. We also explore publicly available datasets for benchmarking ambiguity detection and resolution techniques and highlight their relevance for ongoing research. Finally, we identify open problems and future research directions, proposing areas for further investigation. By offering a comprehensive review of current research on ambiguities and disambiguation with LLMs, we aim to contribute to the development of more robust and reliable language systems.
ECLAIR: Enhanced Clarification for Interactive Responses
Mar 19, 2025



We present ECLAIR (Enhanced CLArification for Interactive Responses), a novel unified and end-to-end framework for interactive disambiguation in enterprise AI assistants. ECLAIR generates clarification questions for ambiguous user queries and resolves ambiguity based on the user's response.We introduce a generalized architecture capable of integrating ambiguity information from multiple downstream agents, enhancing context-awareness in resolving ambiguities and allowing enterprise specific definition of agents. We further define agents within our system that provide domain-specific grounding information. We conduct experiments comparing ECLAIR to few-shot prompting techniques and demonstrate ECLAIR's superior performance in clarification question generation and ambiguity resolution.
SKALD: Learning-Based Shot Assembly for Coherent Multi-Shot Video Creation
Mar 11, 2025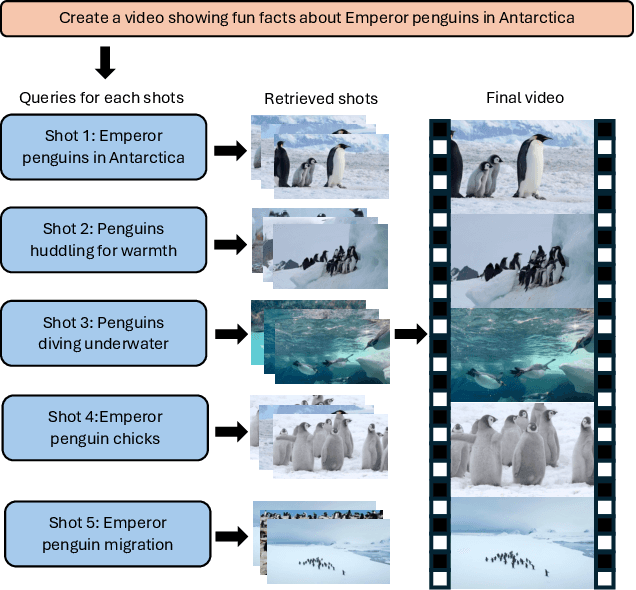
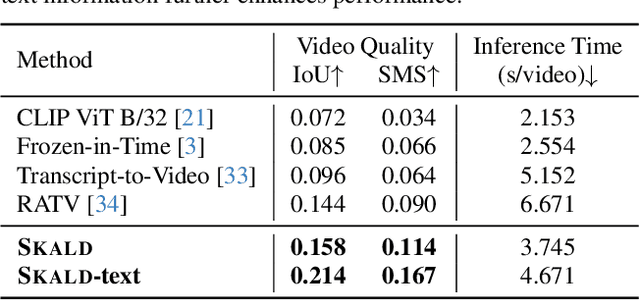

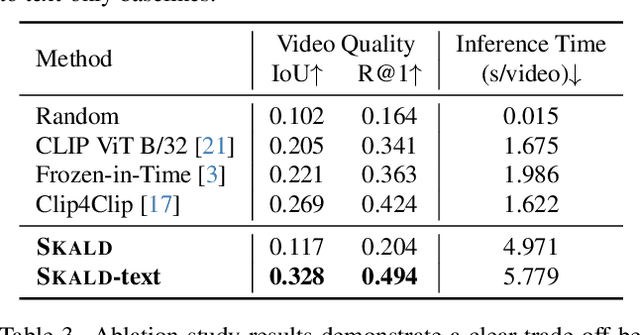
We present SKALD, a multi-shot video assembly method that constructs coherent video sequences from candidate shots with minimal reliance on text. Central to our approach is the Learned Clip Assembly (LCA) score, a learning-based metric that measures temporal and semantic relationships between shots to quantify narrative coherence. We tackle the exponential complexity of combining multiple shots with an efficient beam-search algorithm guided by the LCA score. To train our model effectively with limited human annotations, we propose two tasks for the LCA encoder: Shot Coherence Learning, which uses contrastive learning to distinguish coherent and incoherent sequences, and Feature Regression, which converts these learned representations into a real-valued coherence score. We develop two variants: a base SKALD model that relies solely on visual coherence and SKALD-text, which integrates auxiliary text information when available. Experiments on the VSPD and our curated MSV3C datasets show that SKALD achieves an improvement of up to 48.6% in IoU and a 43% speedup over the state-of-the-art methods. A user study further validates our approach, with 45% of participants favoring SKALD-assembled videos, compared to 22% preferring text-based assembly methods.
Exploring Rewriting Approaches for Different Conversational Tasks
Feb 26, 2025



Conversational assistants often require a question rewriting algorithm that leverages a subset of past interactions to provide a more meaningful (accurate) answer to the user's question or request. However, the exact rewriting approach may often depend on the use case and application-specific tasks supported by the conversational assistant, among other constraints. In this paper, we systematically investigate two different approaches, denoted as rewriting and fusion, on two fundamentally different generation tasks, including a text-to-text generation task and a multimodal generative task that takes as input text and generates a visualization or data table that answers the user's question. Our results indicate that the specific rewriting or fusion approach highly depends on the underlying use case and generative task. In particular, we find that for a conversational question-answering assistant, the query rewriting approach performs best, whereas for a data analysis assistant that generates visualizations and data tables based on the user's conversation with the assistant, the fusion approach works best. Notably, we explore two datasets for the data analysis assistant use case, for short and long conversations, and we find that query fusion always performs better, whereas for the conversational text-based question-answering, the query rewrite approach performs best.
Towards Trustworthy Retrieval Augmented Generation for Large Language Models: A Survey
Feb 08, 2025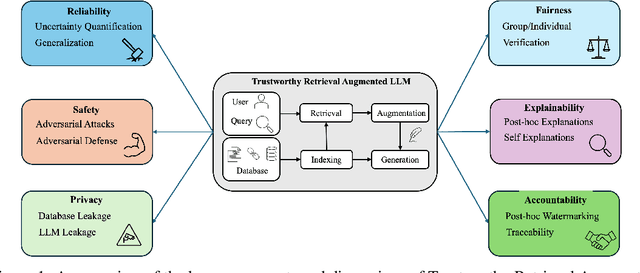
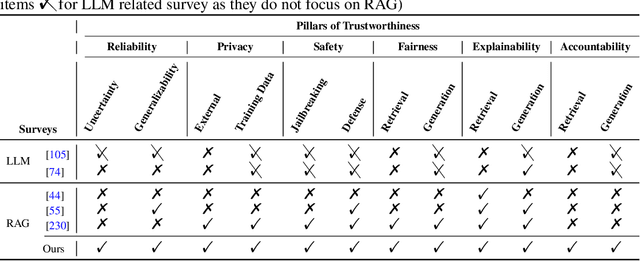


Retrieval-Augmented Generation (RAG) is an advanced technique designed to address the challenges of Artificial Intelligence-Generated Content (AIGC). By integrating context retrieval into content generation, RAG provides reliable and up-to-date external knowledge, reduces hallucinations, and ensures relevant context across a wide range of tasks. However, despite RAG's success and potential, recent studies have shown that the RAG paradigm also introduces new risks, including robustness issues, privacy concerns, adversarial attacks, and accountability issues. Addressing these risks is critical for future applications of RAG systems, as they directly impact their trustworthiness. Although various methods have been developed to improve the trustworthiness of RAG methods, there is a lack of a unified perspective and framework for research in this topic. Thus, in this paper, we aim to address this gap by providing a comprehensive roadmap for developing trustworthy RAG systems. We place our discussion around five key perspectives: reliability, privacy, safety, fairness, explainability, and accountability. For each perspective, we present a general framework and taxonomy, offering a structured approach to understanding the current challenges, evaluating existing solutions, and identifying promising future research directions. To encourage broader adoption and innovation, we also highlight the downstream applications where trustworthy RAG systems have a significant impact.
Diversify-verify-adapt: Efficient and Robust Retrieval-Augmented Ambiguous Question Answering
Sep 04, 2024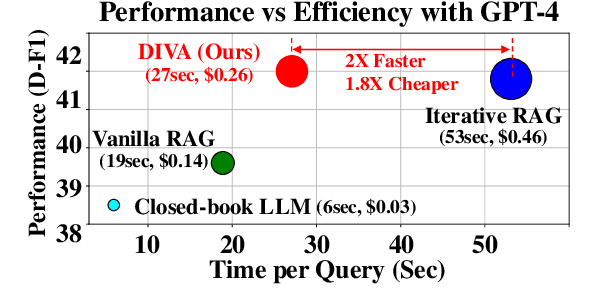
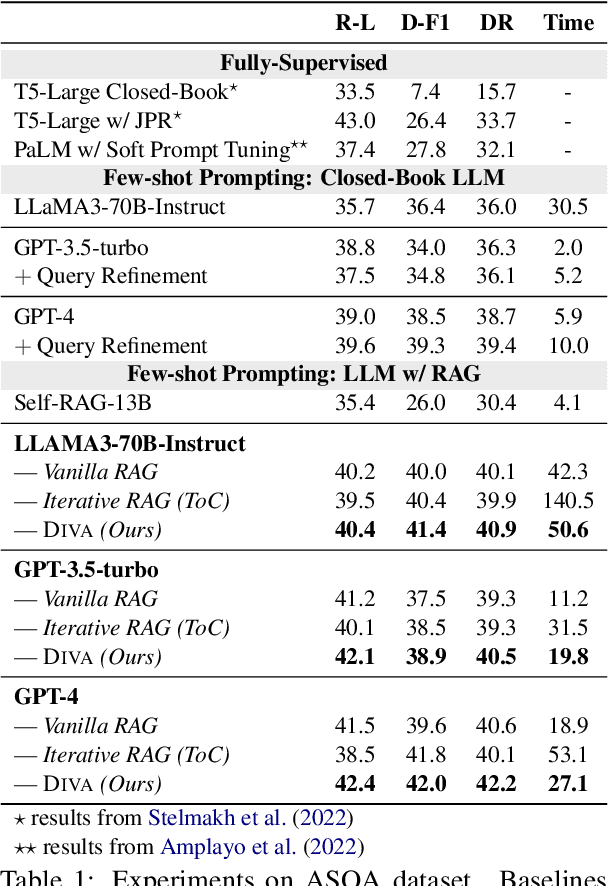
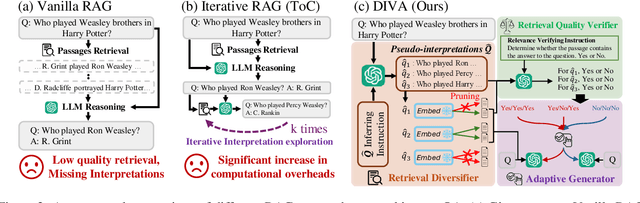
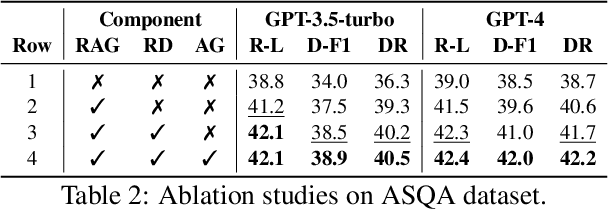
The retrieval augmented generation (RAG) framework addresses an ambiguity in user queries in QA systems by retrieving passages that cover all plausible interpretations and generating comprehensive responses based on the passages. However, our preliminary studies reveal that a single retrieval process often suffers from low quality results, as the retrieved passages frequently fail to capture all plausible interpretations. Although the iterative RAG approach has been proposed to address this problem, it comes at the cost of significantly reduced efficiency. To address these issues, we propose the diversify-verify-adapt (DIVA) framework. DIVA first diversifies the retrieved passages to encompass diverse interpretations. Subsequently, DIVA verifies the quality of the passages and adapts the most suitable approach tailored to their quality. This approach improves the QA systems accuracy and robustness by handling low quality retrieval issue in ambiguous questions, while enhancing efficiency.
X-Reflect: Cross-Reflection Prompting for Multimodal Recommendation
Aug 27, 2024

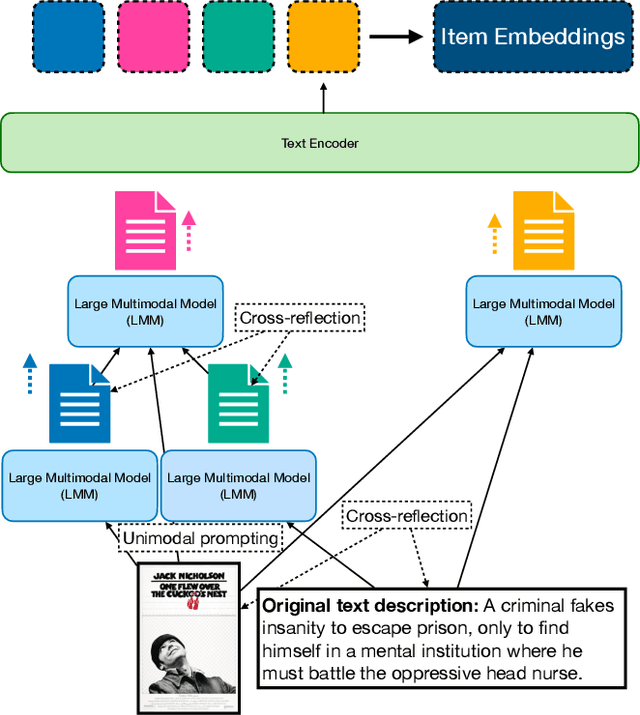
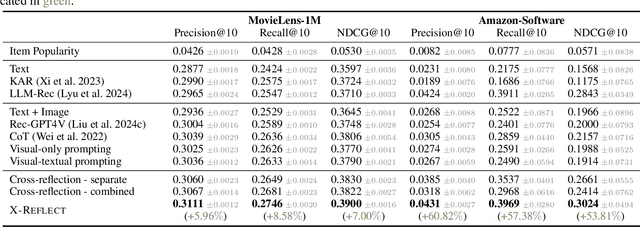
Large Language Models (LLMs) and Large Multimodal Models (LMMs) have been shown to enhance the effectiveness of enriching item descriptions, thereby improving the accuracy of recommendation systems. However, most existing approaches either rely on text-only prompting or employ basic multimodal strategies that do not fully exploit the complementary information available from both textual and visual modalities. This paper introduces a novel framework, Cross-Reflection Prompting, termed X-Reflect, designed to address these limitations by prompting LMMs to explicitly identify and reconcile supportive and conflicting information between text and images. By capturing nuanced insights from both modalities, this approach generates more comprehensive and contextually richer item representations. Extensive experiments conducted on two widely used benchmarks demonstrate that our method outperforms existing prompting baselines in downstream recommendation accuracy. Additionally, we evaluate the generalizability of our framework across different LMM backbones and the robustness of the prompting strategies, offering insights for optimization. This work underscores the importance of integrating multimodal information and presents a novel solution for improving item understanding in multimodal recommendation systems.
Self-Debiasing Large Language Models: Zero-Shot Recognition and Reduction of Stereotypes
Feb 03, 2024Large language models (LLMs) have shown remarkable advances in language generation and understanding but are also prone to exhibiting harmful social biases. While recognition of these behaviors has generated an abundance of bias mitigation techniques, most require modifications to the training data, model parameters, or decoding strategy, which may be infeasible without access to a trainable model. In this work, we leverage the zero-shot capabilities of LLMs to reduce stereotyping in a technique we introduce as zero-shot self-debiasing. With two approaches, self-debiasing via explanation and self-debiasing via reprompting, we show that self-debiasing can significantly reduce the degree of stereotyping across nine different social groups while relying only on the LLM itself and a simple prompt, with explanations correctly identifying invalid assumptions and reprompting delivering the greatest reductions in bias. We hope this work opens inquiry into other zero-shot techniques for bias mitigation.
Bias and Fairness in Large Language Models: A Survey
Sep 02, 2023Rapid advancements of large language models (LLMs) have enabled the processing, understanding, and generation of human-like text, with increasing integration into systems that touch our social sphere. Despite this success, these models can learn, perpetuate, and amplify harmful social biases. In this paper, we present a comprehensive survey of bias evaluation and mitigation techniques for LLMs. We first consolidate, formalize, and expand notions of social bias and fairness in natural language processing, defining distinct facets of harm and introducing several desiderata to operationalize fairness for LLMs. We then unify the literature by proposing three intuitive taxonomies, two for bias evaluation, namely metrics and datasets, and one for mitigation. Our first taxonomy of metrics for bias evaluation disambiguates the relationship between metrics and evaluation datasets, and organizes metrics by the different levels at which they operate in a model: embeddings, probabilities, and generated text. Our second taxonomy of datasets for bias evaluation categorizes datasets by their structure as counterfactual inputs or prompts, and identifies the targeted harms and social groups; we also release a consolidation of publicly-available datasets for improved access. Our third taxonomy of techniques for bias mitigation classifies methods by their intervention during pre-processing, in-training, intra-processing, and post-processing, with granular subcategories that elucidate research trends. Finally, we identify open problems and challenges for future work. Synthesizing a wide range of recent research, we aim to provide a clear guide of the existing literature that empowers researchers and practitioners to better understand and prevent the propagation of bias in LLMs.