 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-Reflect: Cross-Reflection Prompting for Multimodal Recommendation
Paper and Code


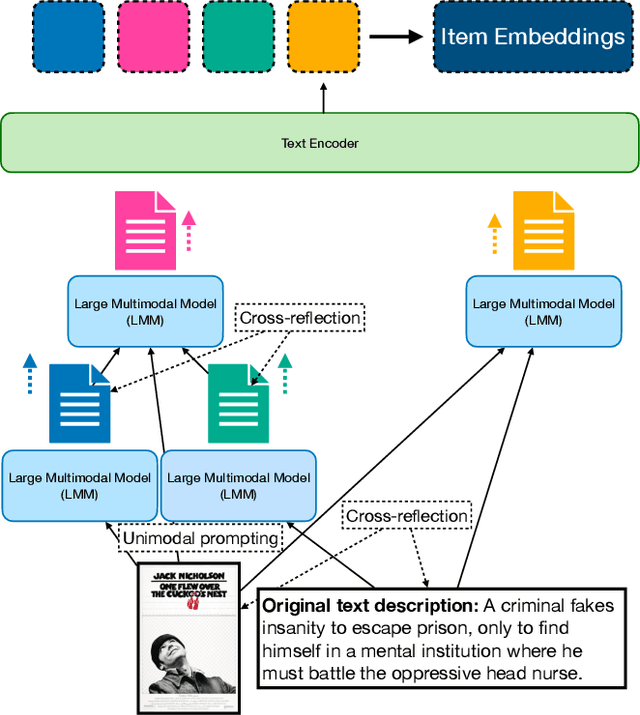
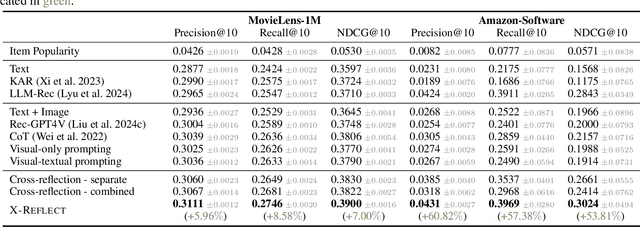
Large Language Models (LLMs) and Large Multimodal Models (LMMs) have been shown to enhance the effectiveness of enriching item descriptions, thereby improving the accuracy of recommendation systems. However, most existing approaches either rely on text-only prompting or employ basic multimodal strategies that do not fully exploit the complementary information available from both textual and visual modalities. This paper introduces a novel framework, Cross-Reflection Prompting, termed X-Reflect, designed to address these limitations by prompting LMMs to explicitly identify and reconcile supportive and conflicting information between text and images. By capturing nuanced insights from both modalities, this approach generates more comprehensive and contextually richer item representations. Extensive experiments conducted on two widely used benchmarks demonstrate that our method outperforms existing prompting baselines in downstream recommendation accuracy. Additionally, we evaluate the generalizability of our framework across different LMM backbones and the robustness of the prompting strategies, offering insights for optimization. This work underscores the importance of integrating multimodal information and presents a novel solution for improving item understanding in multimodal recommendation systems.