 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgram Synthesis with Large Language Models
Aug 16, 2021



This paper explores the limits of the current generation of large language models for program synthesis in general purpose programming languages. We evaluate a collection of such models (with between 244M and 137B parameters) on two new benchmarks, MBPP and MathQA-Python, in both the few-shot and fine-tuning regimes. Our benchmarks are designed to measure the ability of these models to synthesize short Python programs from natural language descriptions. The Mostly Basic Programming Problems (MBPP) dataset contains 974 programming tasks, designed to be solvable by entry-level programmers. The MathQA-Python dataset, a Python version of the MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text. On both datasets, we find that synthesis performance scales log-linearly with model size. Our largest models, even without finetuning on a code dataset, can synthesize solutions to 59.6 percent of the problems from MBPP using few-shot learning with a well-designed prompt. Fine-tuning on a held-out portion of the dataset improves performance by about 10 percentage points across most model sizes. On the MathQA-Python dataset, the largest fine-tuned model achieves 83.8 percent accuracy. Going further, we study the model's ability to engage in dialog about code, incorporating human feedback to improve its solutions. We find that natural language feedback from a human halves the error rate compared to the model's initial prediction. Additionally, we conduct an error analysis to shed light on where these models fall short and what types of programs are most difficult to generate. Finally, we explore the semantic grounding of these models by fine-tuning them to predict the results of program execution. We find that even our best models are generally unable to predict the output of a program given a specific input.
ShapeAssembly: Learning to Generate Programs for 3D Shape Structure Synthesis
Sep 17, 2020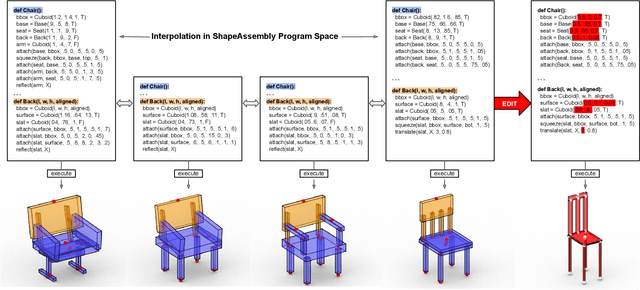
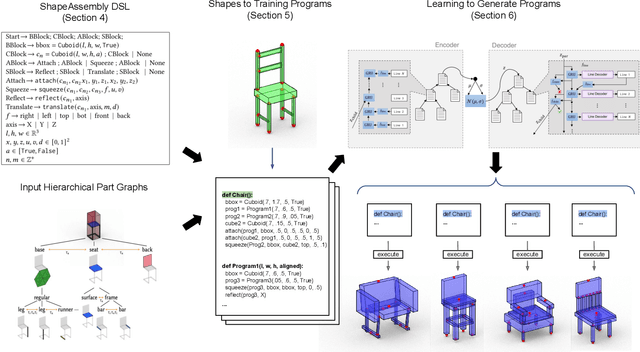
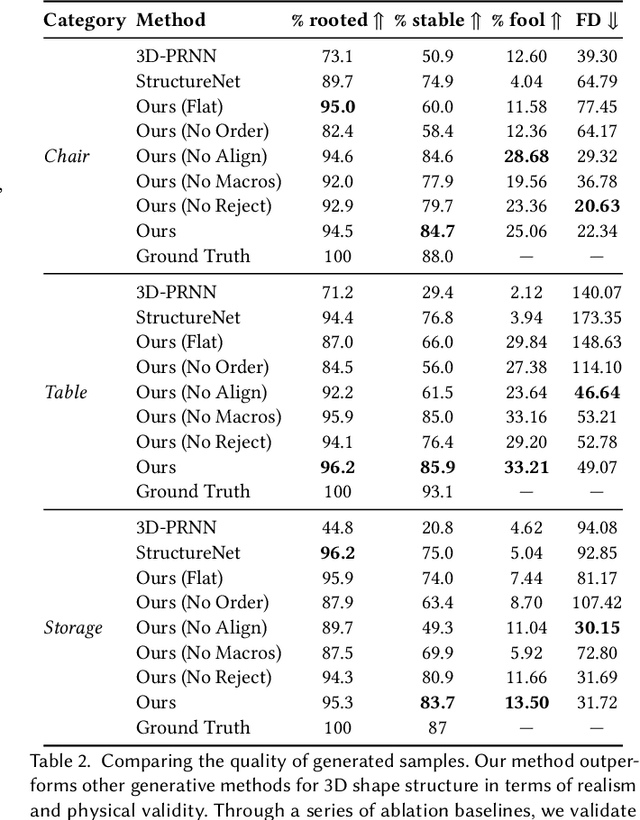
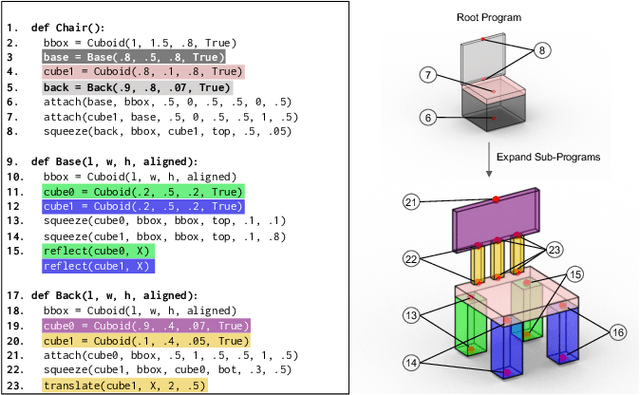
Manually authoring 3D shapes is difficult and time consuming; generative models of 3D shapes offer compelling alternatives. Procedural representations are one such possibility: they offer high-quality and editable results but are difficult to author and often produce outputs with limited diversity. On the other extreme are deep generative models: given enough data, they can learn to generate any class of shape but their outputs have artifacts and the representation is not editable. In this paper, we take a step towards achieving the best of both worlds for novel 3D shape synthesis. We propose ShapeAssembly, a domain-specific "assembly-language" for 3D shape structures. ShapeAssembly programs construct shapes by declaring cuboid part proxies and attaching them to one another, in a hierarchical and symmetrical fashion. Its functions are parameterized with free variables, so that one program structure is able to capture a family of related shapes. We show how to extract ShapeAssembly programs from existing shape structures in the PartNet dataset. Then we train a deep generative model, a hierarchical sequence VAE, that learns to write novel ShapeAssembly programs. The program captures the subset of variability that is interpretable and editable. The deep model captures correlations across shape collections that are hard to express procedurally. We evaluate our approach by comparing shapes output by our generated programs to those from other recent shape structure synthesis models. We find that our generated shapes are more plausible and physically-valid than those of other methods. Additionally, we assess the latent spaces of these models, and find that ours is better structured and produces smoother interpolations. As an application, we use our generative model and differentiable program interpreter to infer and fit shape programs to unstructured geometry, such as point clouds.
The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models
Aug 12, 2020



We present the Language Interpretability Tool (LIT), an open-source platform for visualization and understanding of NLP models. We focus on core questions about model behavior: Why did my model make this prediction? When does it perform poorly? What happens under a controlled change in the input? LIT integrates local explanations, aggregate analysis, and counterfactual generation into a streamlined, browser-based interface to enable rapid exploration and error analysis. We include case studies for a diverse set of workflows, including exploring counterfactuals for sentiment analysis, measuring gender bias in coreference systems, and exploring local behavior in text generation. LIT supports a wide range of models--including classification, seq2seq, and structured prediction--and is highly extensible through a declarative, framework-agnostic API. LIT is under active development, with code and full documentation available at https://github.com/pair-code/lit.