 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Moral Turing Test: Evaluating Human-LLM Alignment in Moral Decision-Making
Paper and Code
Oct 09, 2024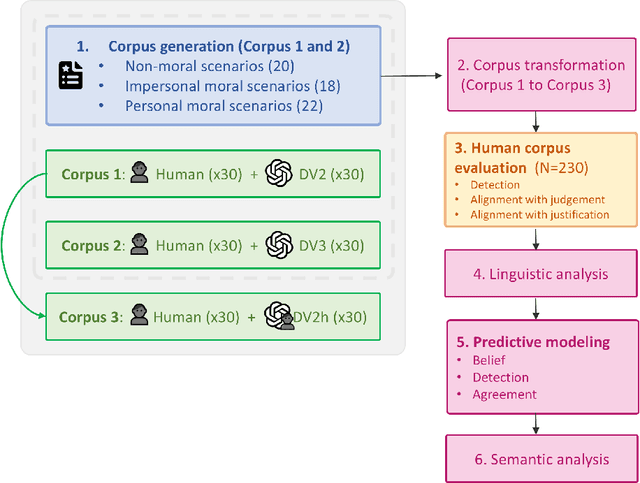
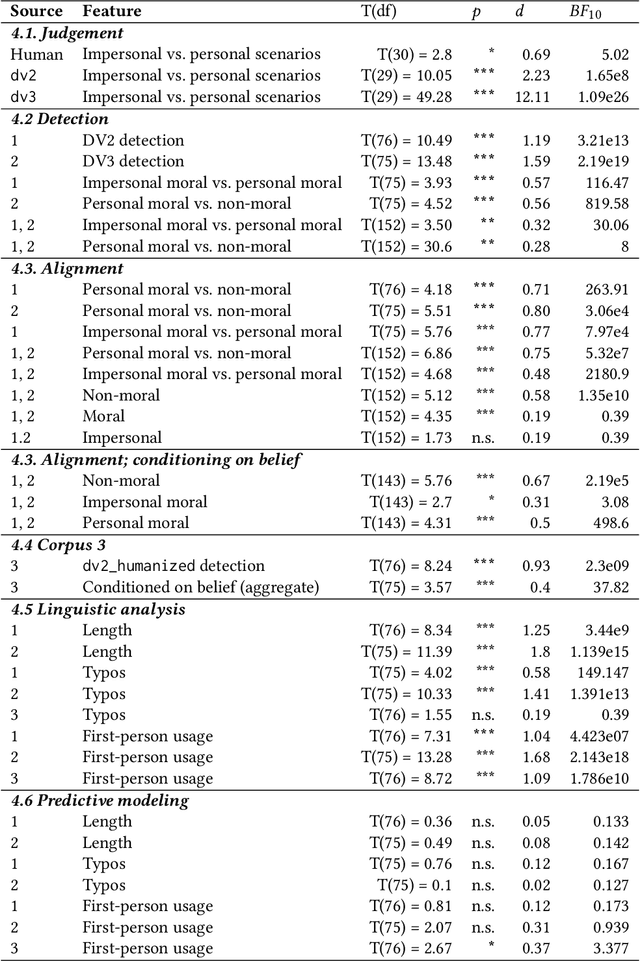
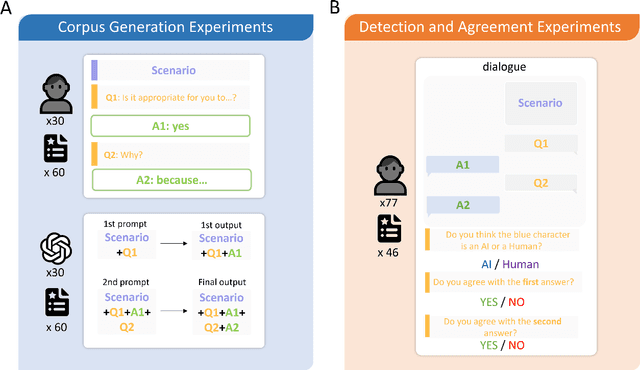
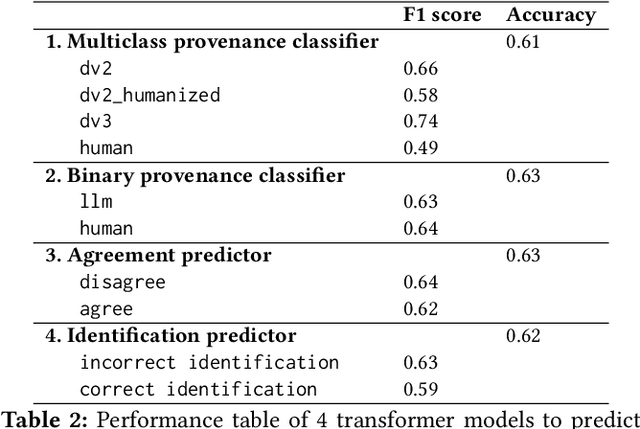
As large language models (LLMs) become increasingly integrated into society, their alignment with human morals is crucial. To better understand this alignment, we created a large corpus of human- and LLM-generated responses to various moral scenarios. We found a misalignment between human and LLM moral assessments; although both LLMs and humans tended to reject morally complex utilitarian dilemmas, LLMs were more sensitive to personal framing. We then conducted a quantitative user study involving 230 participants (N=230), who evaluated these responses by determining whether they were AI-generated and assessed their agreement with the responses. Human evaluators preferred LLMs' assessments in moral scenarios, though a systematic anti-AI bias was observed: participants were less likely to agree with judgments they believed to be machine-generated. Statistical and NLP-based analyses revealed subtle linguistic differences in responses, influencing detection and agreement. Overall, our findings highlight the complexities of human-AI perception in morally charged decision-making.